

Doublet identification in single-cell sequencing data using scDblFinder
- PMID: 35814628
- PMCID: PMC9204188
- DOI: 10.12688/f1000research.73600.2
Doublet identification in single-cell sequencing data using scDblFinder
Abstract
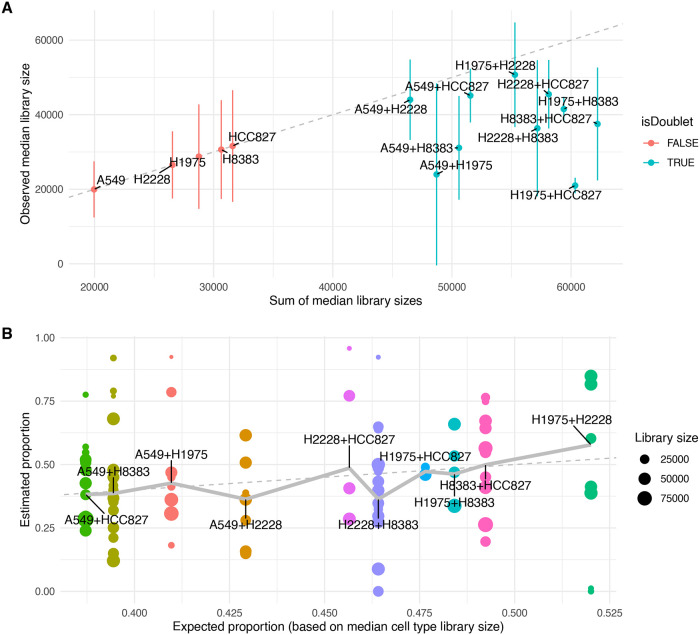
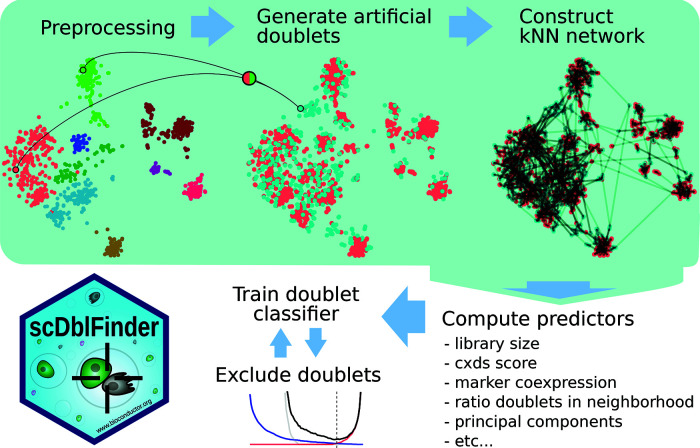
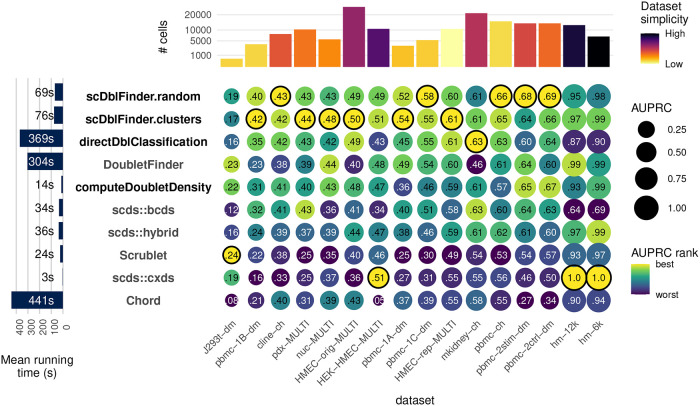
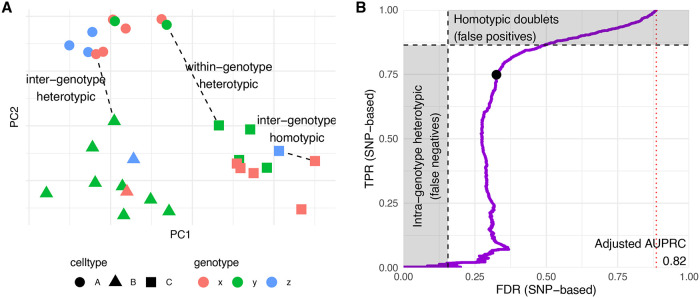
Doublets are prevalent in single-cell sequencing data and can lead to artifactual findings. A number of strategies have therefore been proposed to detect them. Building on the strengths of existing approaches, we developed scDblFinder, a fast, flexible and accurate Bioconductor-based doublet detection method. Here we present the method, justify its design choices, demonstrate its performance on both single-cell RNA and accessibility (ATAC) sequencing data, and provide some observations on doublet formation, detection, and enrichment analysis. Even in complex datasets, scDblFinder can accurately identify most heterotypic doublets, and was already found by an independent benchmark to outcompete alternatives.
Keywords: doublets; filtering; multiplets; single-cell sequencing.
Copyright: © 2022 Germain PL et al.
Conflict of interest statement
No competing interests were disclosed.
Figures
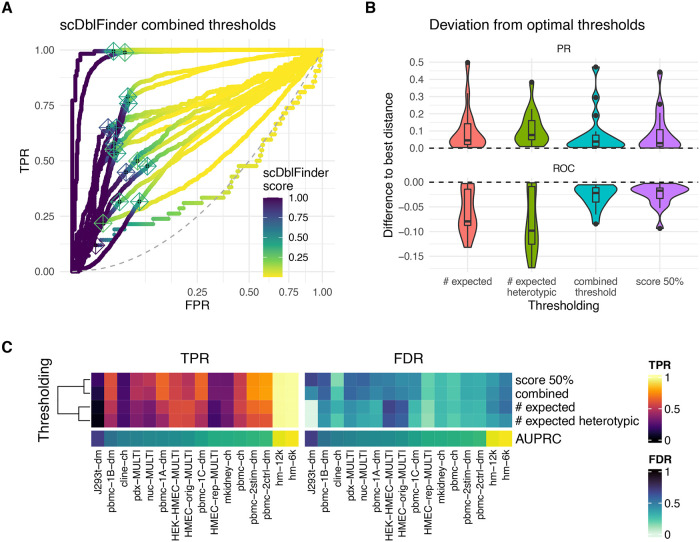
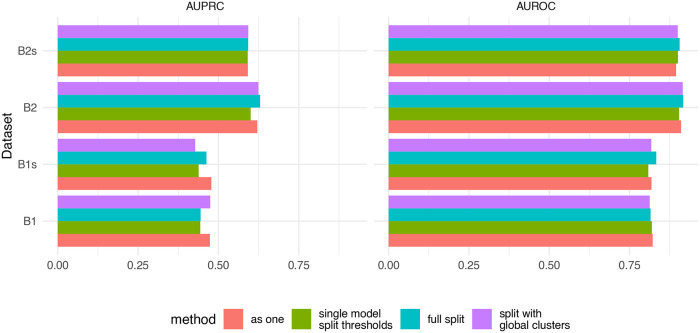
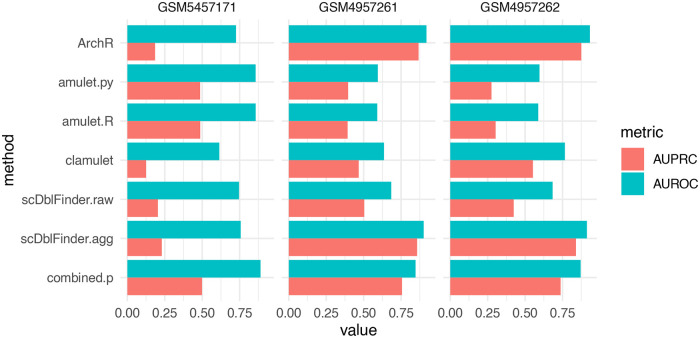
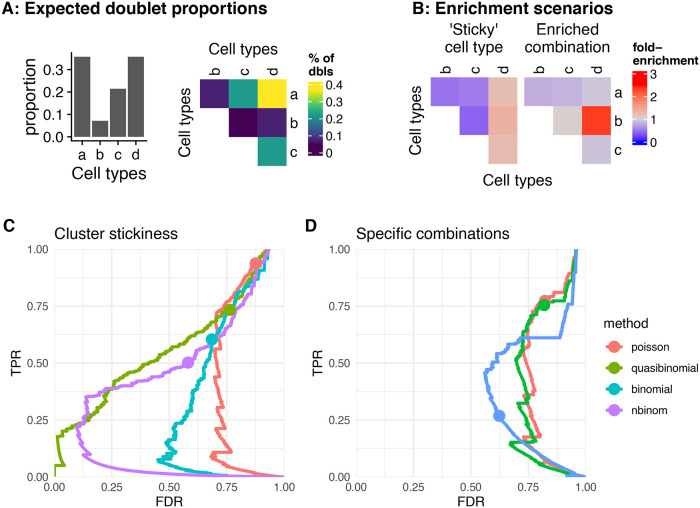
References
MeSH terms
Substances
Associated data
LinkOut - more resources
Full Text Sources
Other Literature Sources