

Computational estimation of quality and clinical relevance of cancer cell lines
- PMID: 35822563
- PMCID: PMC9277610
- DOI: 10.15252/msb.202211017
Computational estimation of quality and clinical relevance of cancer cell lines
Abstract
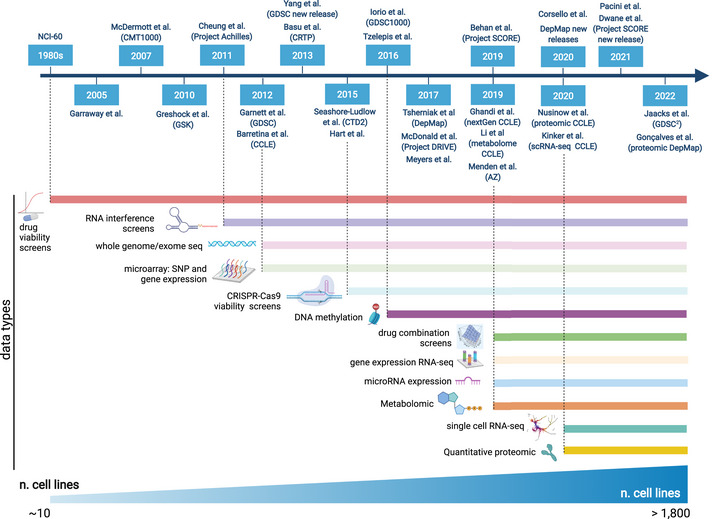
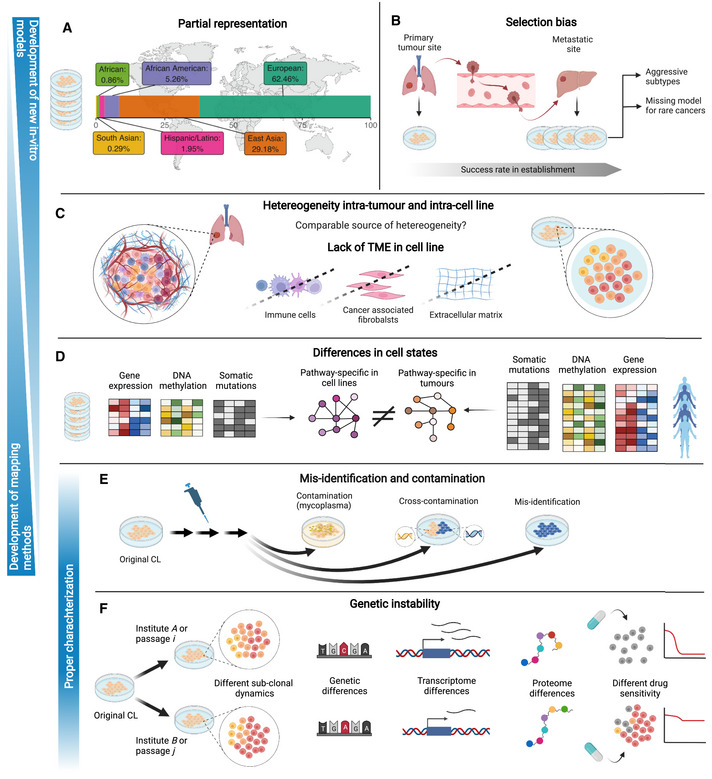
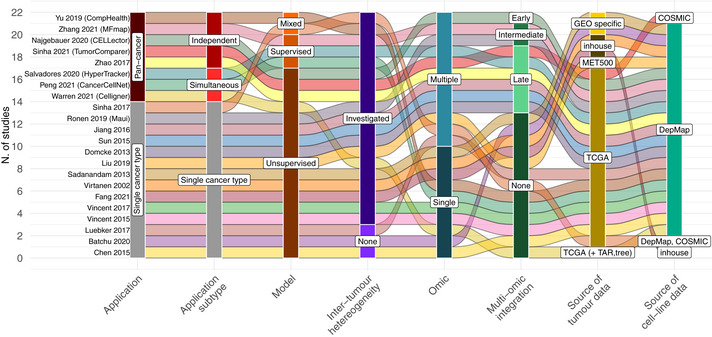
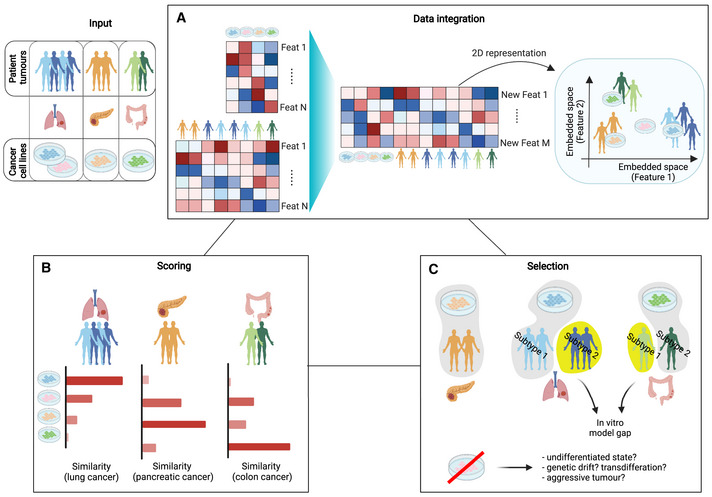
Immortal cancer cell lines (CCLs) are the most widely used system for investigating cancer biology and for the preclinical development of oncology therapies. Pharmacogenomic and genome-wide editing screenings have facilitated the discovery of clinically relevant gene-drug interactions and novel therapeutic targets via large panels of extensively characterised CCLs. However, tailoring pharmacological strategies in a precision medicine context requires bridging the existing gaps between tumours and in vitro models. Indeed, intrinsic limitations of CCLs such as misidentification, the absence of tumour microenvironment and genetic drift have highlighted the need to identify the most faithful CCLs for each primary tumour while addressing their heterogeneity, with the development of new models where necessary. Here, we discuss the most significant limitations of CCLs in representing patient features, and we review computational methods aiming at systematically evaluating the suitability of CCLs as tumour proxies and identifying the best patient representative in vitro models. Additionally, we provide an overview of the applications of these methods to more complex models and discuss future machine-learning-based directions that could resolve some of the arising discrepancies.
Keywords: cancer cell lines; computational biology; drug discovery; personalised medicine; pharmacogenomics.
© 2022 The Authors. Published under the terms of the CC BY 4.0 license.
Figures
References
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
