

Acoustic regularities in infant-directed speech and song across cultures
- PMID: 35851843
- PMCID: PMC10101735
- DOI: 10.1038/s41562-022-01410-x
Acoustic regularities in infant-directed speech and song across cultures
Abstract
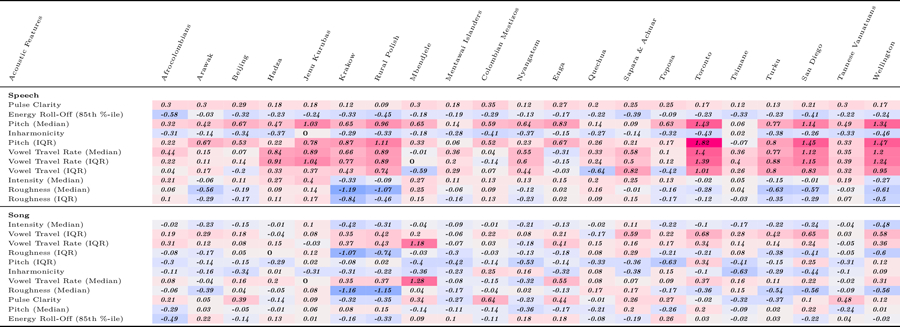
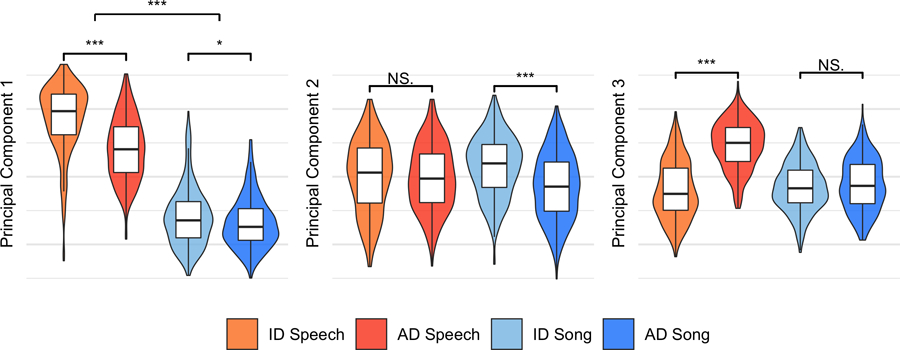
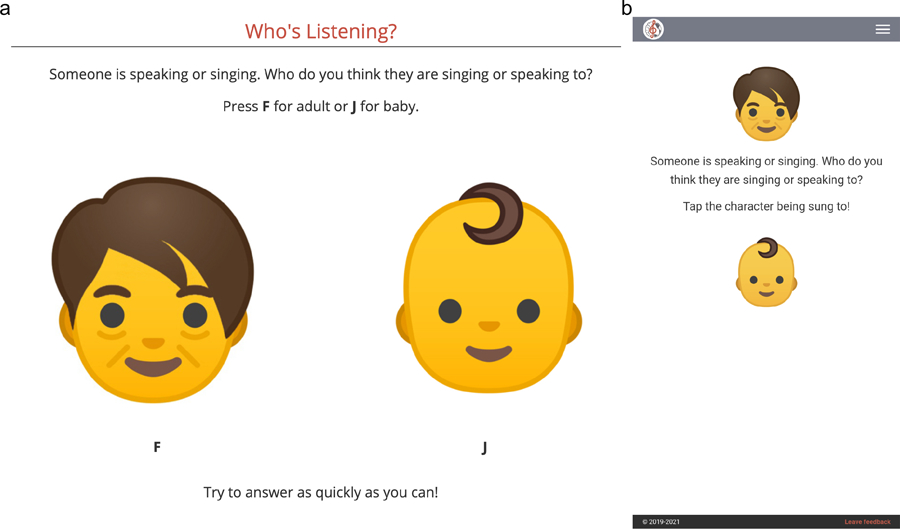
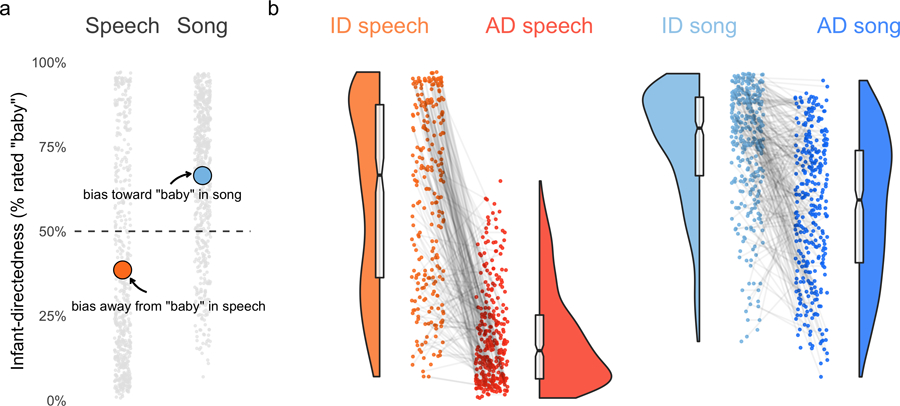
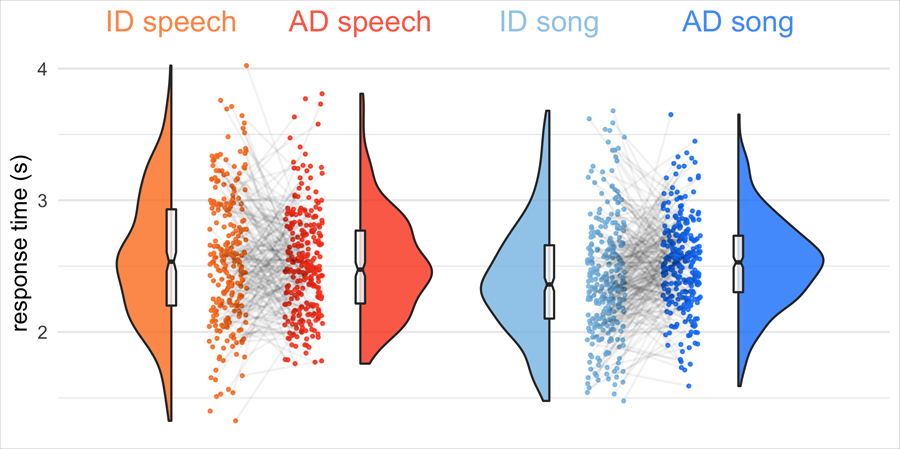
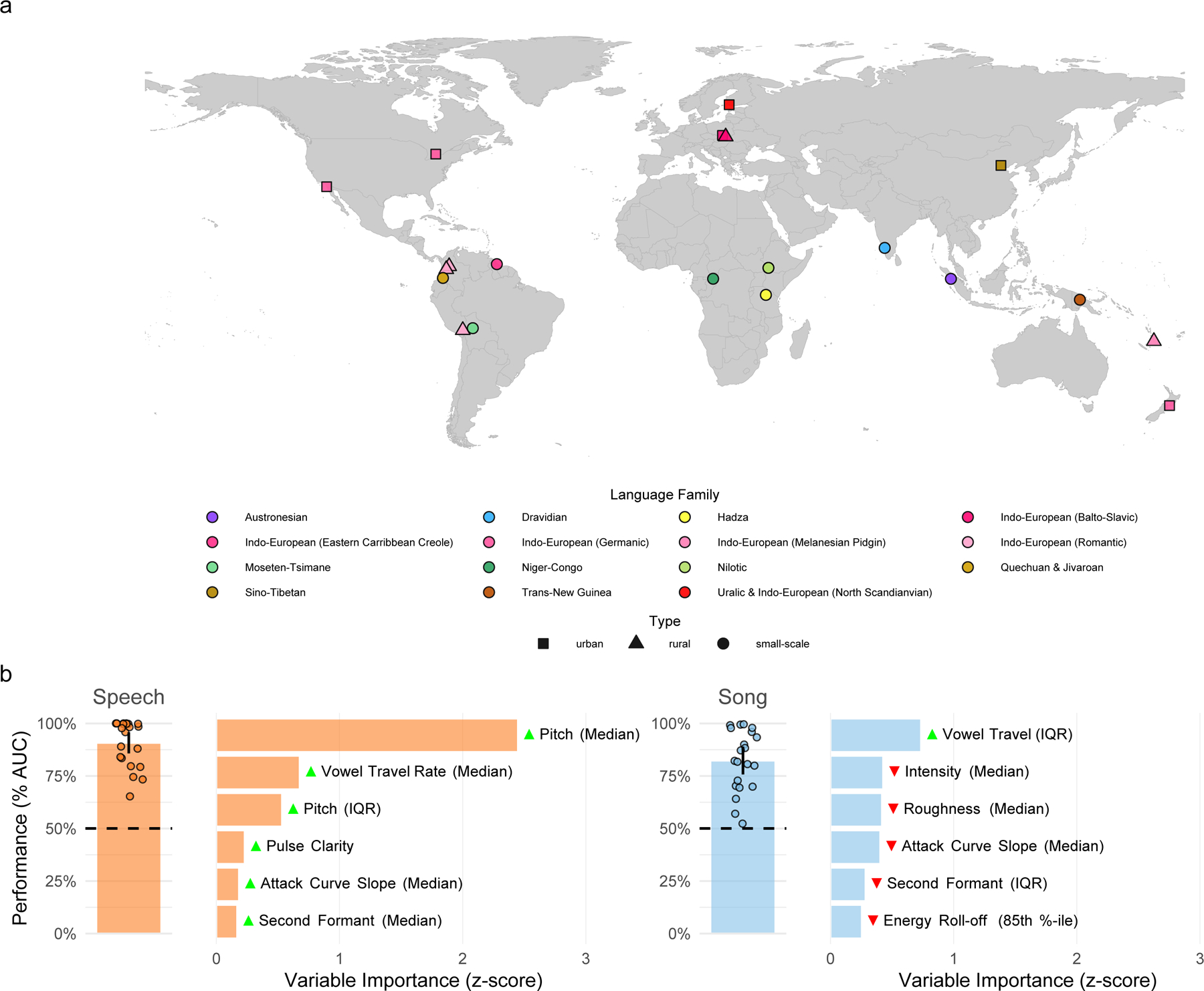
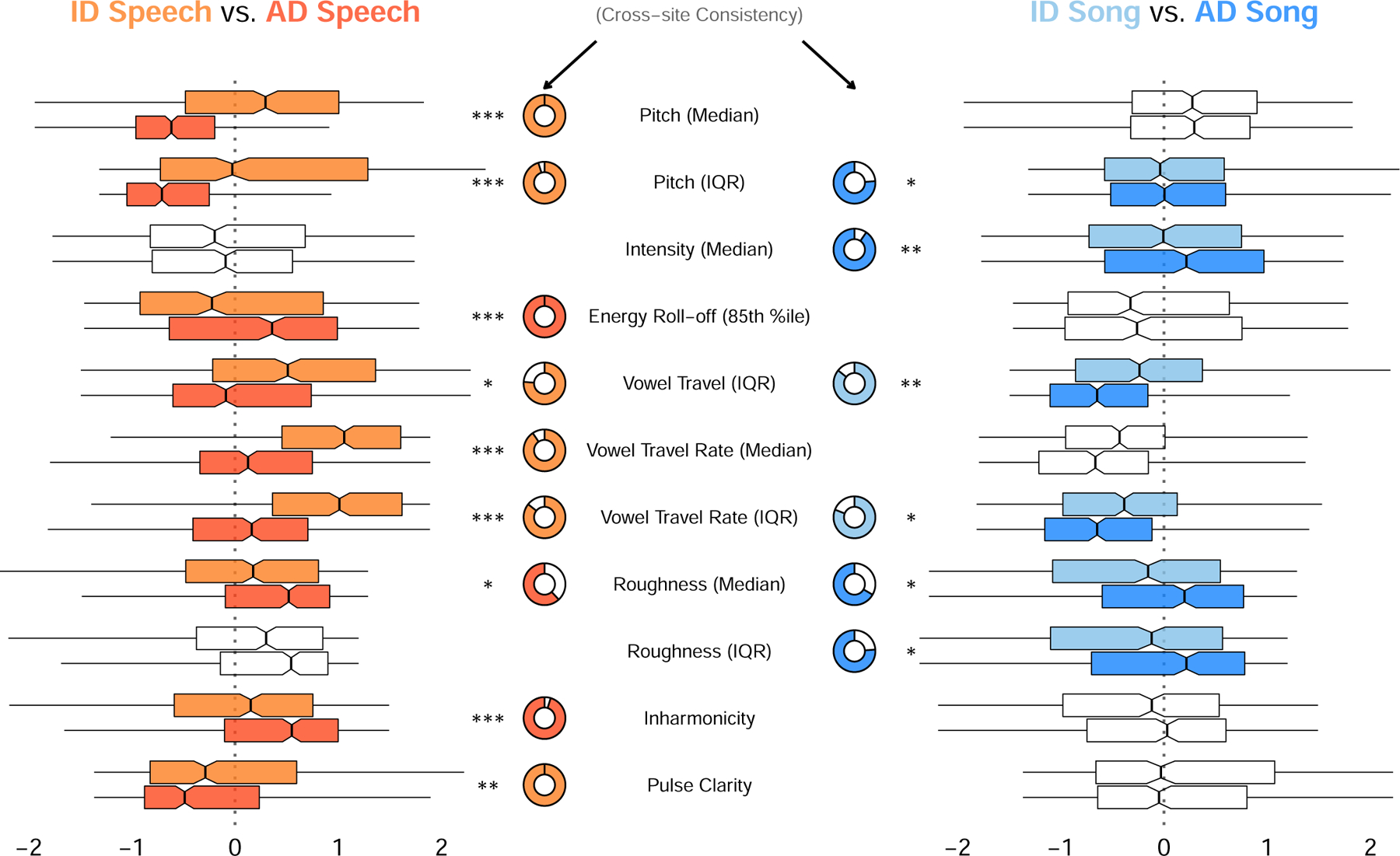
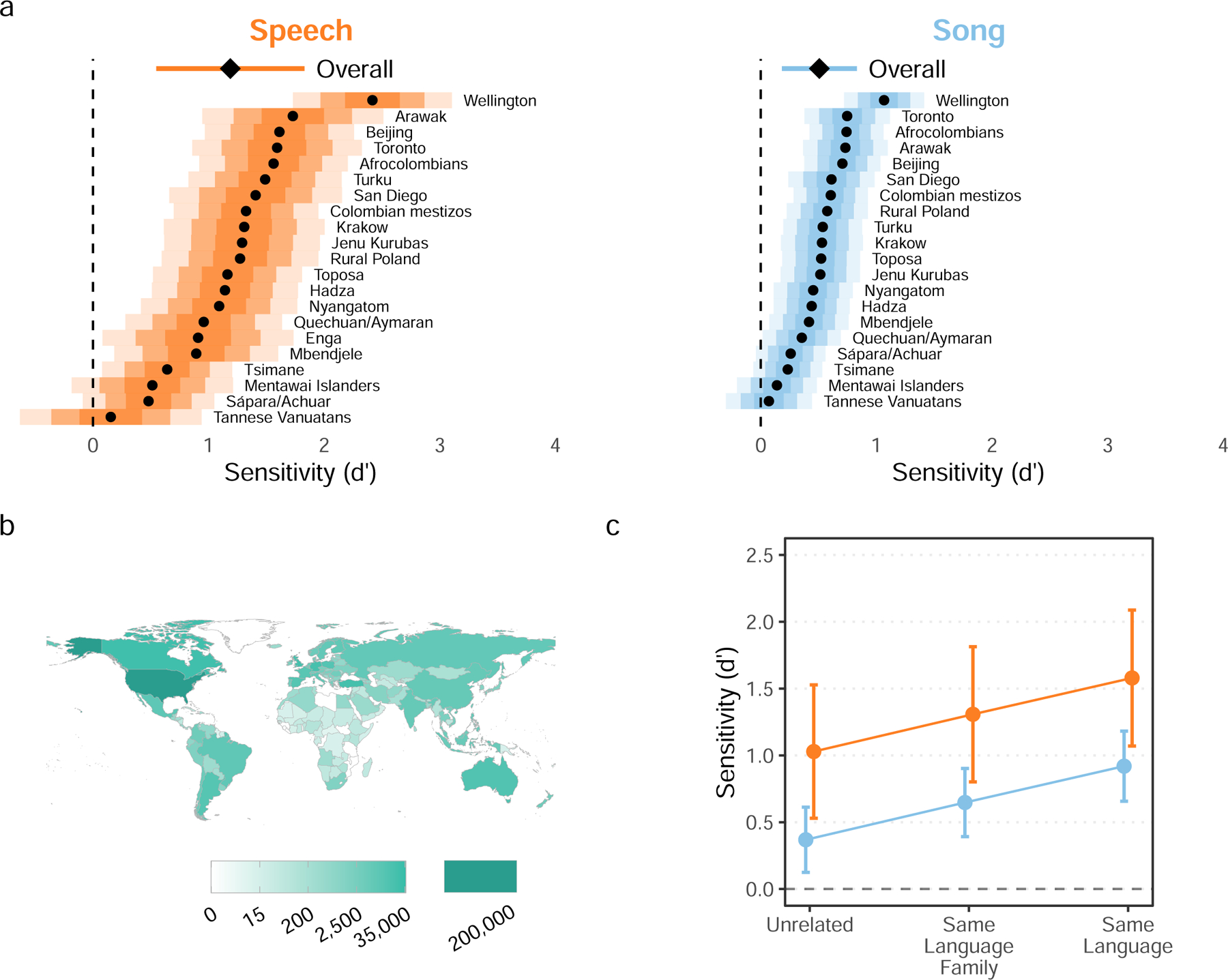
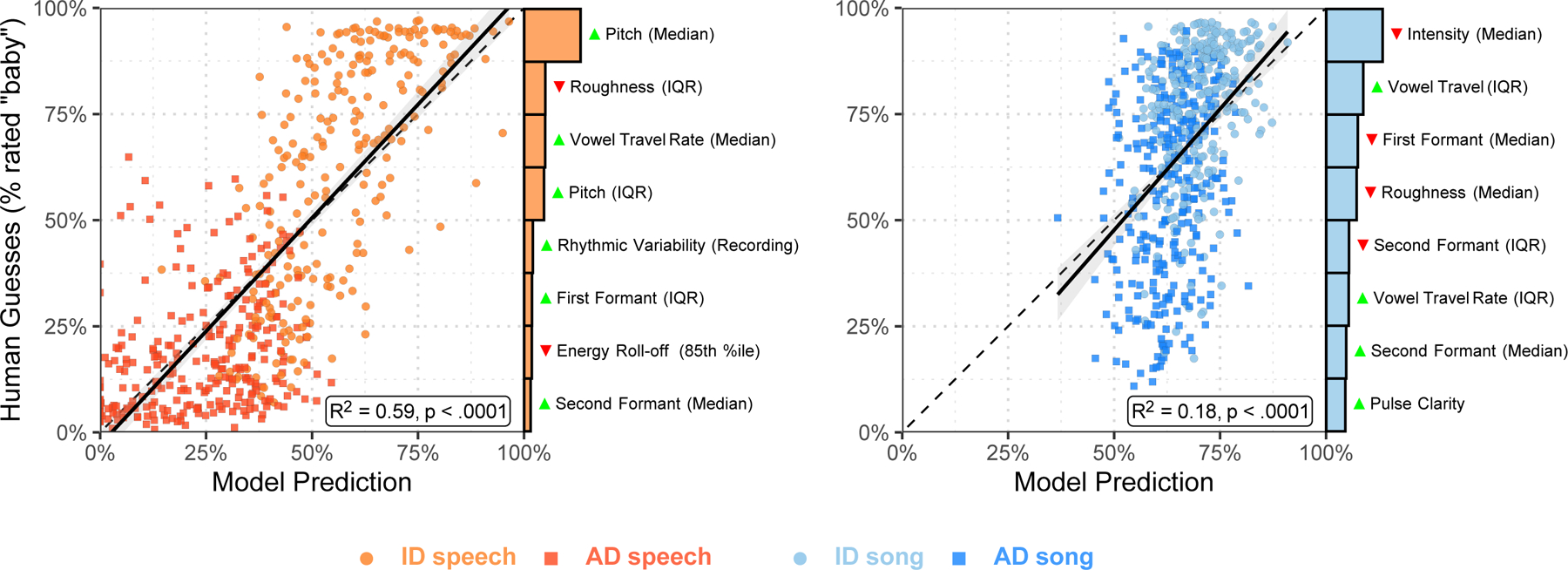
When interacting with infants, humans often alter their speech and song in ways thought to support communication. Theories of human child-rearing, informed by data on vocal signalling across species, predict that such alterations should appear globally. Here, we show acoustic differences between infant-directed and adult-directed vocalizations across cultures. We collected 1,615 recordings of infant- and adult-directed speech and song produced by 410 people in 21 urban, rural and small-scale societies. Infant-directedness was reliably classified from acoustic features only, with acoustic profiles of infant-directedness differing across language and music but in consistent fashions. We then studied listener sensitivity to these acoustic features. We played the recordings to 51,065 people from 187 countries, recruited via an English-language website, who guessed whether each vocalization was infant-directed. Their intuitions were more accurate than chance, predictable in part by common sets of acoustic features and robust to the effects of linguistic relatedness between vocalizer and listener. These findings inform hypotheses of the psychological functions and evolution of human communication.
© 2022. The Author(s), under exclusive licence to Springer Nature Limited.
Conflict of interest statement
Competing interests statement
The authors declare no competing interests.
Figures
References
-
- Morton ES On the occurrence and significance of motivation-structural rules in some bird and mammal sounds. The American Naturalist 111, 855–869 (1977).
-
- Endler JA Some general comments on the evolution and design of animal communication systems. Philosophical Transactions of the Royal Society B: Biological Sciences 340, 215–225 (1993). - PubMed
-
- Owren MJ & Rendall D Sound on the rebound: Bringing form and function back to the forefront in understanding nonhuman primate vocal signaling. Evolutionary Anthropology 10, 58–71 (2001).
-
- Fitch WT, Neubauer J & Herzel H Calls out of chaos: The adaptive significance of nonlinear phenomena in mammalian vocal production. Animal Behaviour 63, 407–418 (2002).
-
- Wiley RH The evolution of communication: Information and manipulation. Animal Behaviour 2, 156–189 (1983).
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
