

On the semantic representation of risk
- PMID: 35857448
- PMCID: PMC9269897
- DOI: 10.1126/sciadv.abm1883
On the semantic representation of risk
Abstract
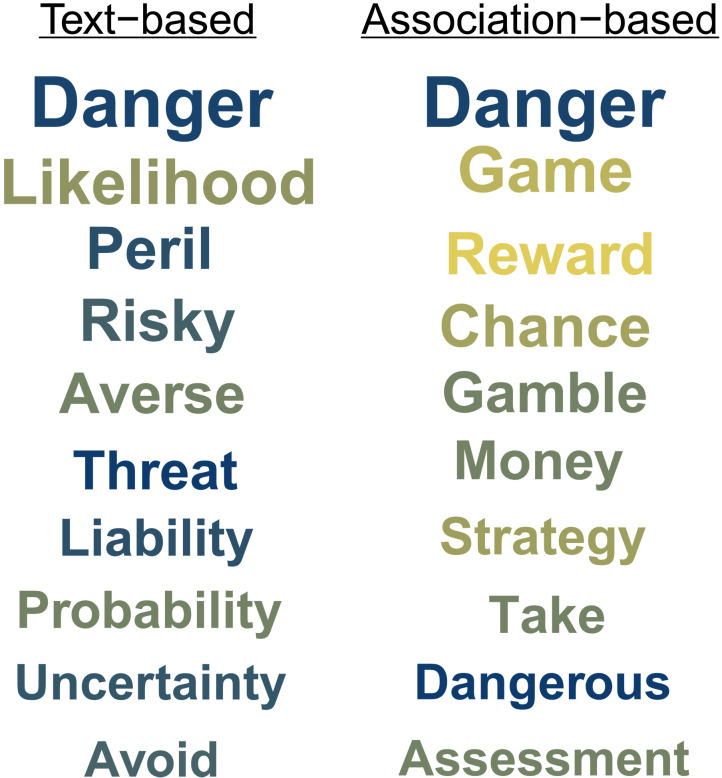
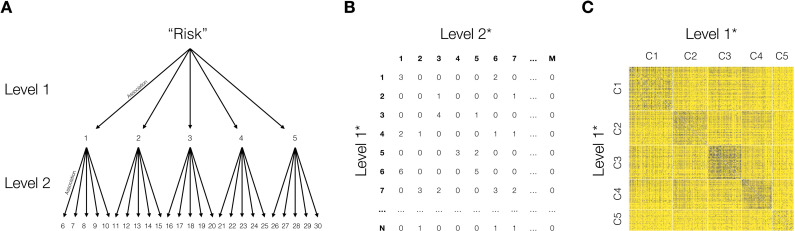
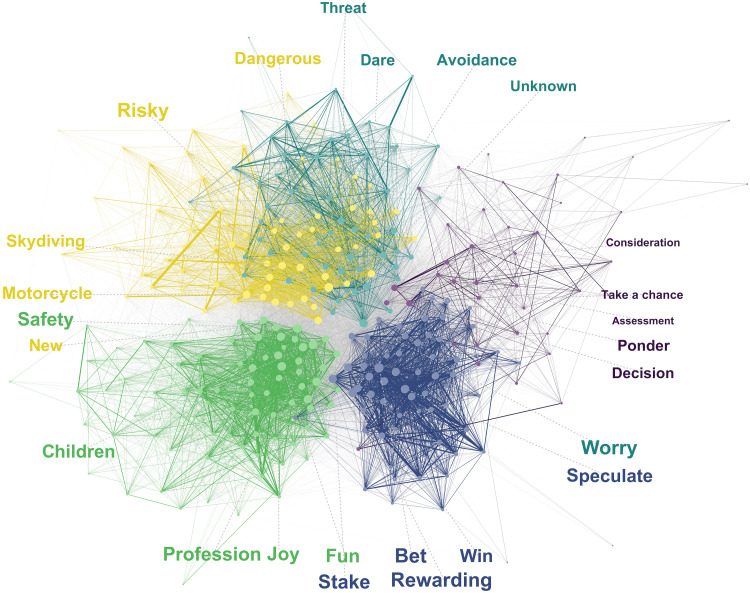
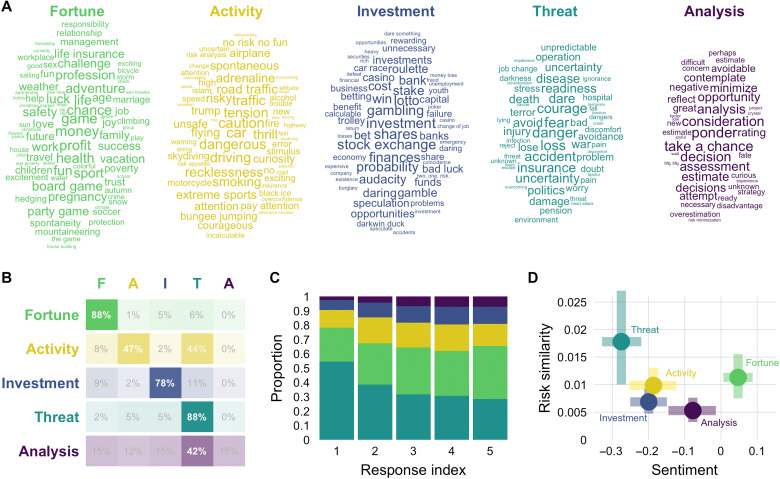
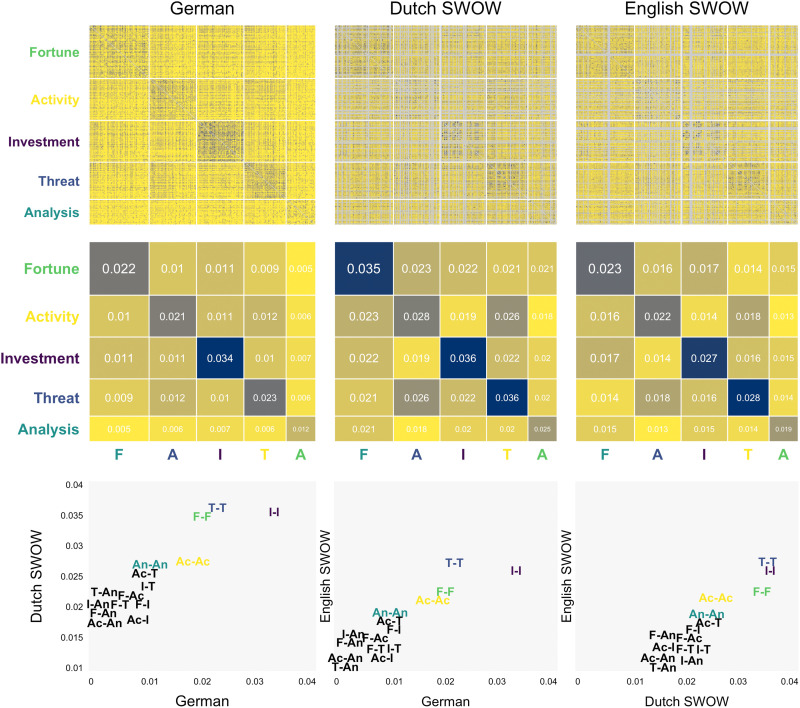
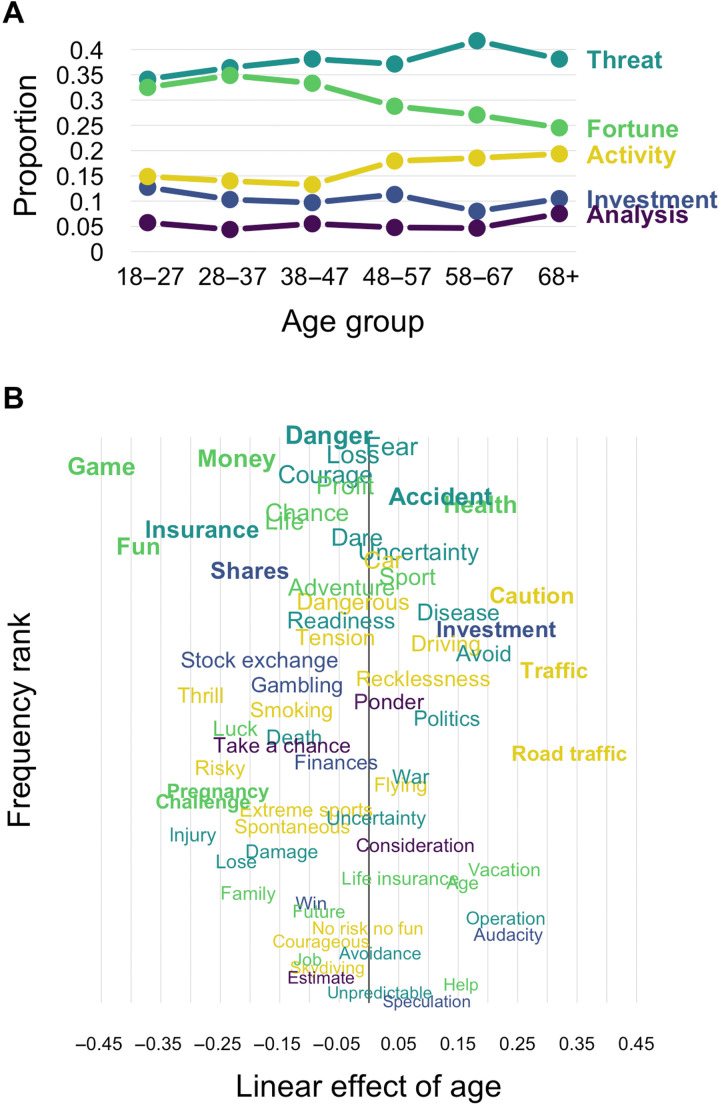
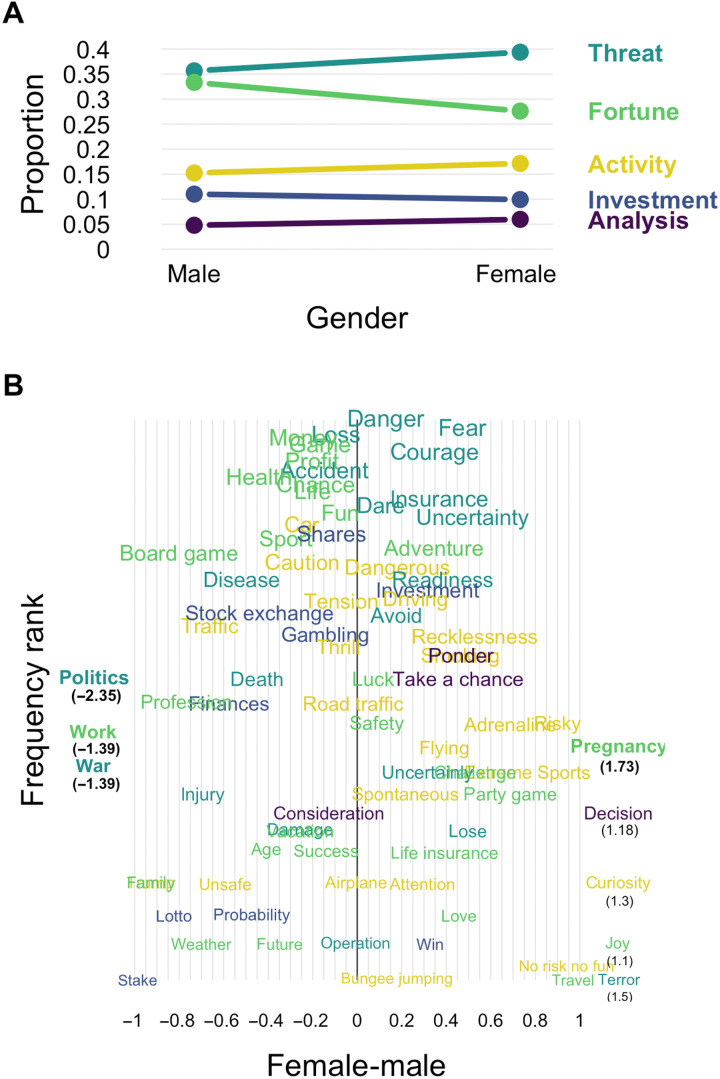
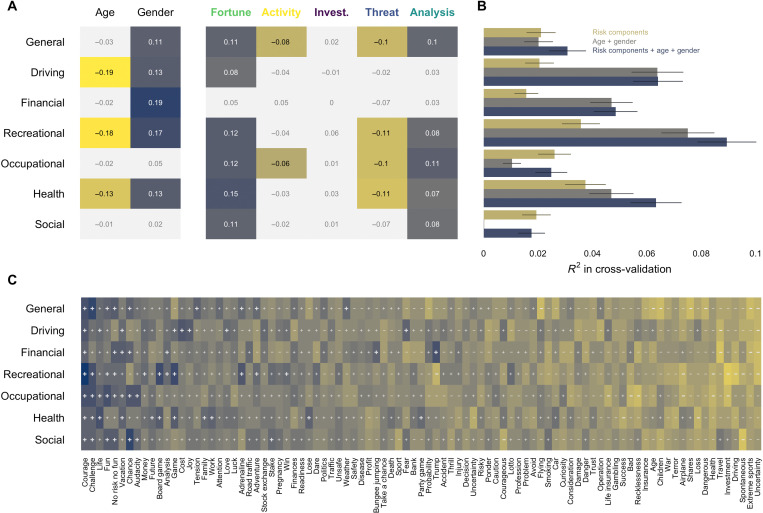
What are the defining features of lay people's semantic representation of risk? We contribute to mapping the semantics of risk based on word associations to provide insight into both universal and individual differences in the representation of risk. Specifically, we introduce a mini-snowball word association paradigm and use the tools of network and sentiment analysis to characterize the semantics of risk. We find that association-based representations not only corroborate but also extend those extracted from past survey- and text-based approaches. Crucially, we find that the semantics of risk show universal properties and individual and group differences. Most notably, while semantic clusters generalize across languages, their frequency varies systematically across demographic groups, with older and female respondents showing more negative connotations and mentioning more often certain types of activities (e.g., recreational activities) relative to younger adults and males, respectively. Our work has general implications for the measurement of risk-related constructs by suggesting that "risk" can mean different things to different individuals.
Figures
References
-
- Starr C., Social benefit versus technological risk: What is our society willing to pay for safety? Science 165, 1232–1238 (1969). - PubMed
-
- Aven T., The risk concept—Historical and recent development trends. Reliab. Eng. Syst.Saf. 99, 33–44 (2012).
-
- Boholm M., The semantic field of risk. Saf. Sci. 92, 205–216 (2017).
-
- Boudia S., Jas N., Introduction: Risk and ‘risk society’ in historical perspective. Hist. Technol. 23, 317–331 (2007).
LinkOut - more resources
Full Text Sources
Miscellaneous
