

Artificial Intelligence and Deep Learning for Rheumatologists
- PMID: 35857865
- PMCID: PMC10092842
- DOI: 10.1002/art.42296
Artificial Intelligence and Deep Learning for Rheumatologists
Abstract
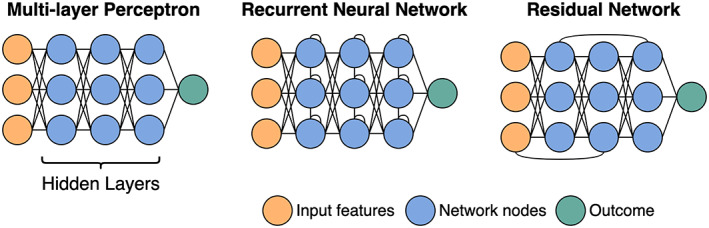
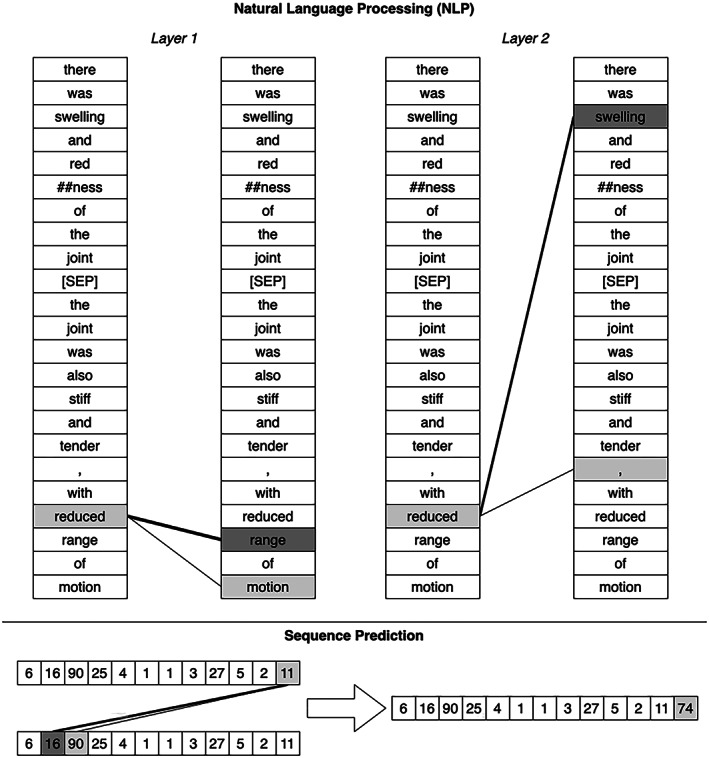
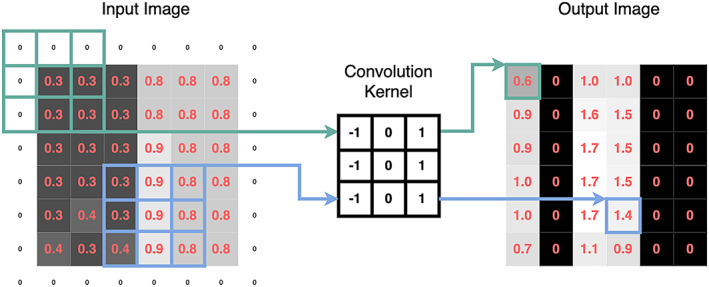
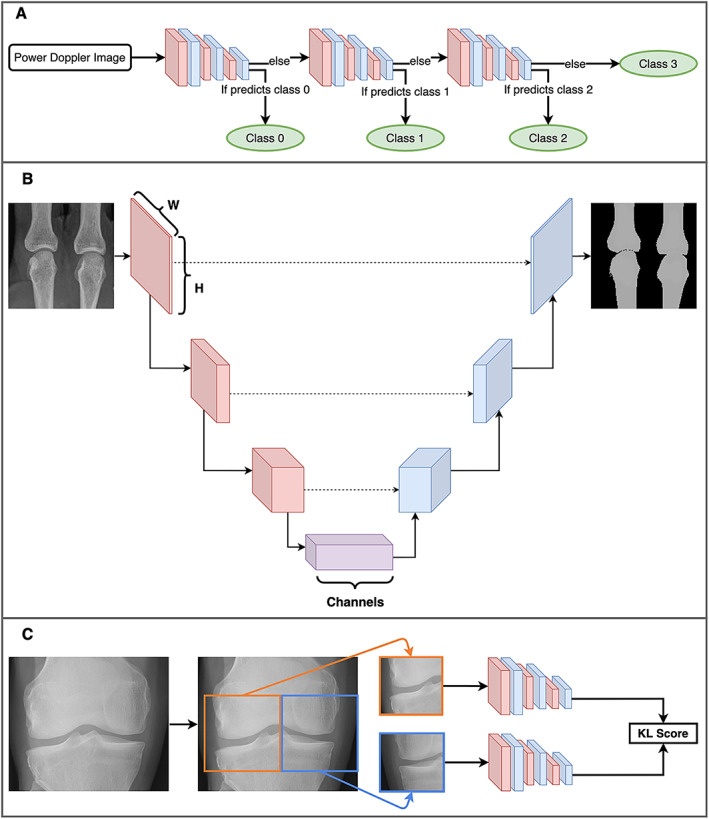
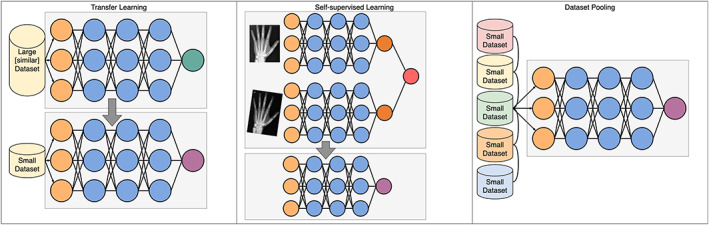
Deep learning has emerged as the leading method in machine learning, spawning a rapidly growing field of academic research and commercial applications across medicine. Deep learning could have particular relevance to rheumatology if correctly utilized. The greatest benefits of deep learning methods are seen with unstructured data frequently found in rheumatology, such as images and text, where traditional machine learning methods have struggled to unlock the trove of information held within these data formats. The basis for this success comes from the ability of deep learning to learn the structure of the underlying data. It is no surprise that the first areas of medicine that have started to experience impact from deep learning heavily rely on interpreting visual data, such as triaging radiology workflows and computer-assisted colonoscopy. Applications in rheumatology are beginning to emerge, with recent successes in areas as diverse as detecting joint erosions on plain radiography, predicting future rheumatoid arthritis disease activity, and identifying halo sign on temporal artery ultrasound. Given the important role deep learning methods are likely to play in the future of rheumatology, it is imperative that rheumatologists understand the methods and assumptions that underlie the deep learning algorithms in widespread use today, their limitations and the landscape of deep learning research that will inform algorithm development, and clinical decision support tools of the future. The best applications of deep learning in rheumatology must be informed by the clinical experience of rheumatologists, so that algorithms can be developed to tackle the most relevant clinical problems.
© 2022 The Authors. Arthritis & Rheumatology published by Wiley Periodicals LLC on behalf of American College of Rheumatology.
Figures
References
-
- LeCun Y, Bengio Y, Hinton G. Deep learning. Nature 2015;521:436–44. - PubMed
-
- American College of Radiology . AI Central. URL: https://aicentral.acrdsi.org/.
-
- Silver D, Hubert T, Schrittwieser J, et al. Mastering chess and shogi by self‐play with a general reinforcement learning algorithm. arXiv [cs.AI] 2017. URL: http://arxiv.org/abs/1712.01815. - PubMed
-
- Zhang J, Zhao Y, Saleh M, et al. PEGASUS: Pre‐training with Extracted Gap‐sentences for Abstractive Summarization. arXiv [cs.CL] 2019. URL: http://arxiv.org/abs/1912.08777.
-
- Chen K, Oldja R, Smolyanskiy N, et al. MVLidarNet: Real‐time multi‐class scene understanding for autonomous driving using multiple views. arXiv [cs.CV] 2020. URL: http://arxiv.org/abs/2006.05518.
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
