

Interpreting models interpreting brain dynamics
- PMID: 35864279
- PMCID: PMC9304350
- DOI: 10.1038/s41598-022-15539-2
Interpreting models interpreting brain dynamics
Abstract
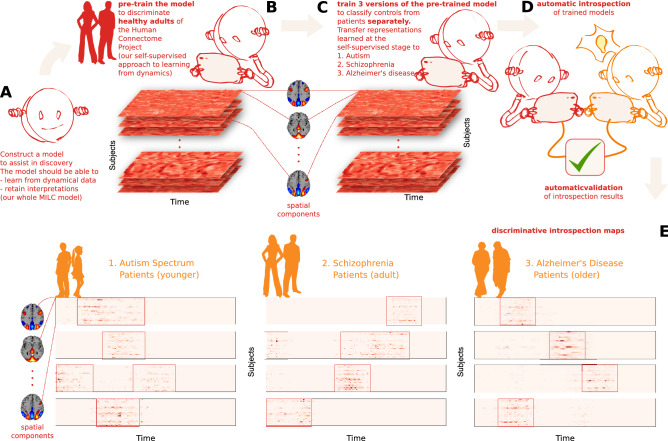
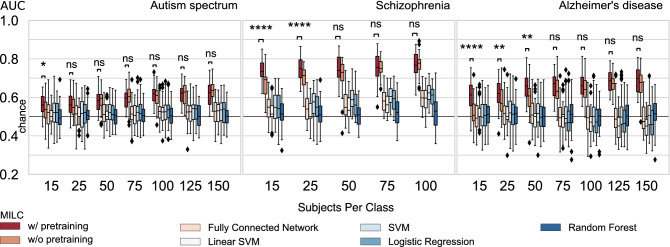
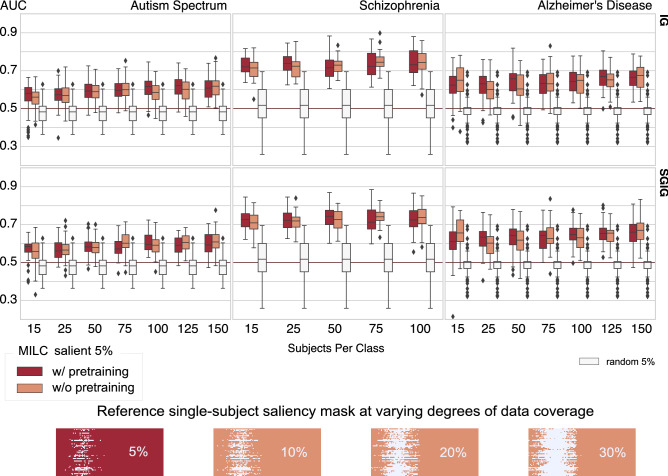
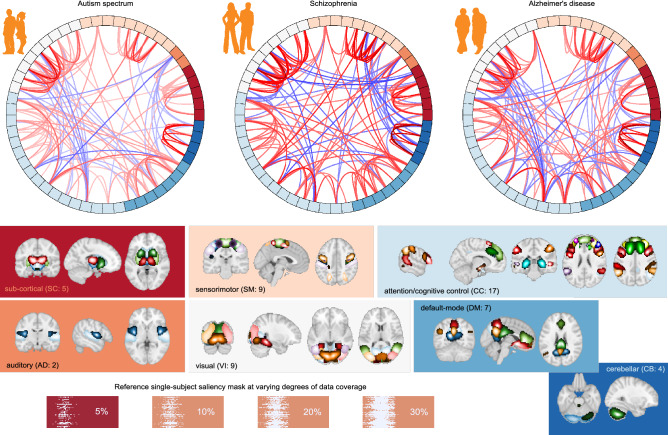
Brain dynamics are highly complex and yet hold the key to understanding brain function and dysfunction. The dynamics captured by resting-state functional magnetic resonance imaging data are noisy, high-dimensional, and not readily interpretable. The typical approach of reducing this data to low-dimensional features and focusing on the most predictive features comes with strong assumptions and can miss essential aspects of the underlying dynamics. In contrast, introspection of discriminatively trained deep learning models may uncover disorder-relevant elements of the signal at the level of individual time points and spatial locations. Yet, the difficulty of reliable training on high-dimensional low sample size datasets and the unclear relevance of the resulting predictive markers prevent the widespread use of deep learning in functional neuroimaging. In this work, we introduce a deep learning framework to learn from high-dimensional dynamical data while maintaining stable, ecologically valid interpretations. Results successfully demonstrate that the proposed framework enables learning the dynamics of resting-state fMRI directly from small data and capturing compact, stable interpretations of features predictive of function and dysfunction.
© 2022. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures
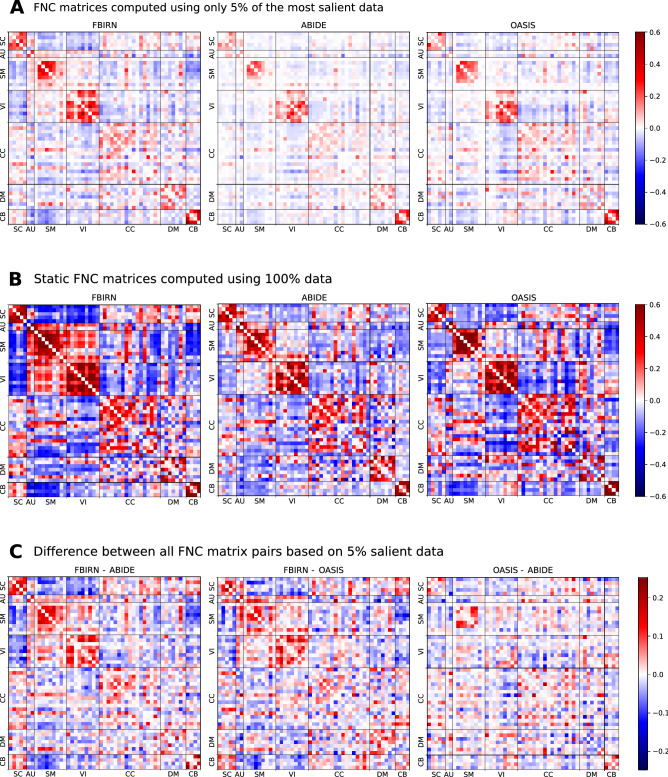
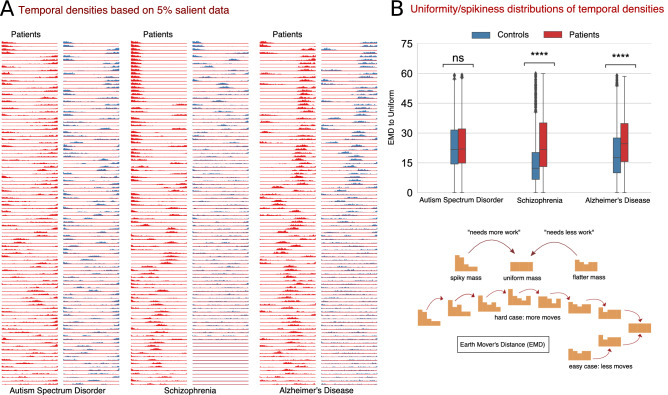
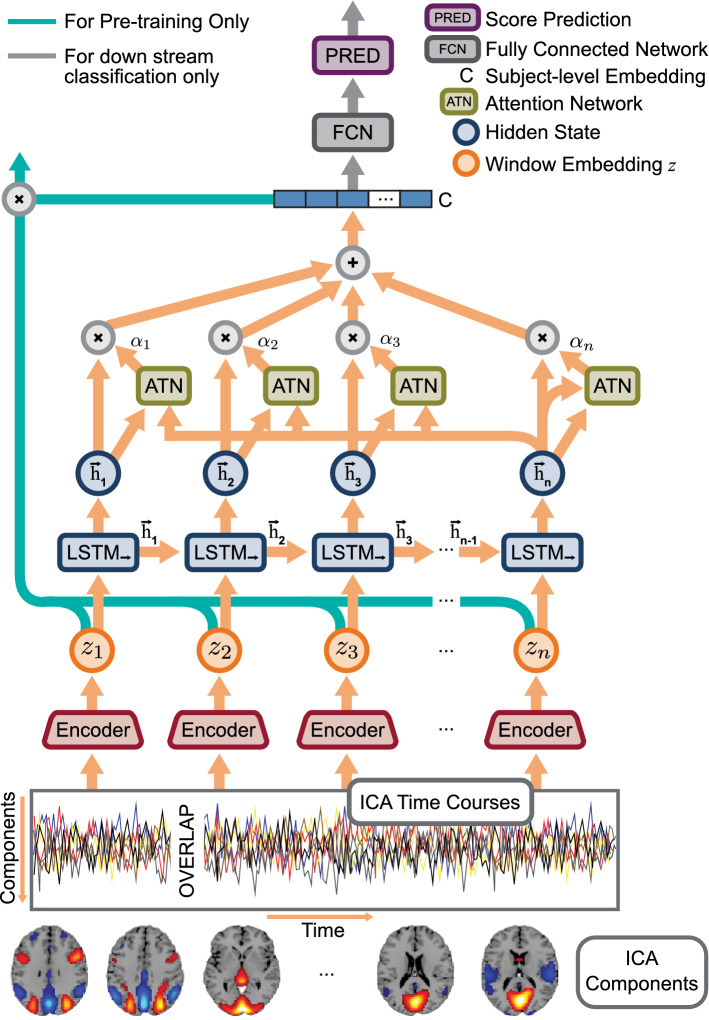
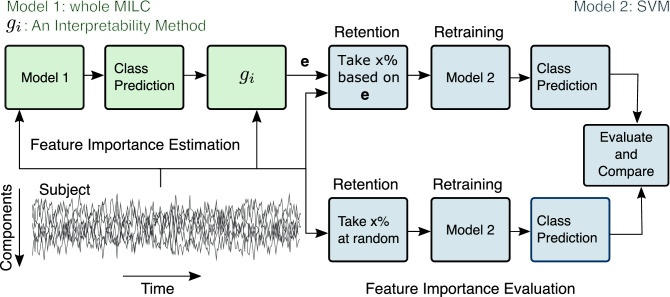
References
-
- Goldberg, D. P. & Huxley, P. Common Mental Disorders: A Bio-social Model. (Tavistock/Routledge, 1992).
Publication types
MeSH terms
Grants and funding
- P30 AG066444/AG/NIA NIH HHS/United States
- U54 MH091657/MH/NIMH NIH HHS/United States
- R01 AG043434/AG/NIA NIH HHS/United States
- R01 EB009352/EB/NIBIB NIH HHS/United States
- K23 MH087770/MH/NIMH NIH HHS/United States
- UL1 TR000448/TR/NCATS NIH HHS/United States
- R01MH118695/NH/NIH HHS/United States
- R01EB006841/NH/NIH HHS/United States
- U24 RR021992/RR/NCRR NIH HHS/United States
- P01 AG003991/AG/NIA NIH HHS/United States
- P50 AG005681/AG/NIA NIH HHS/United States
- P01 AG026276/AG/NIA NIH HHS/United States
- R03 MH096321/MH/NIMH NIH HHS/United States
- RF1MH121885/NH/NIH HHS/United States
LinkOut - more resources
Full Text Sources
Medical
