

Graph-based molecular Pareto optimisation
- PMID: 35872811
- PMCID: PMC9241971
- DOI: 10.1039/d2sc00821a
Graph-based molecular Pareto optimisation
Abstract
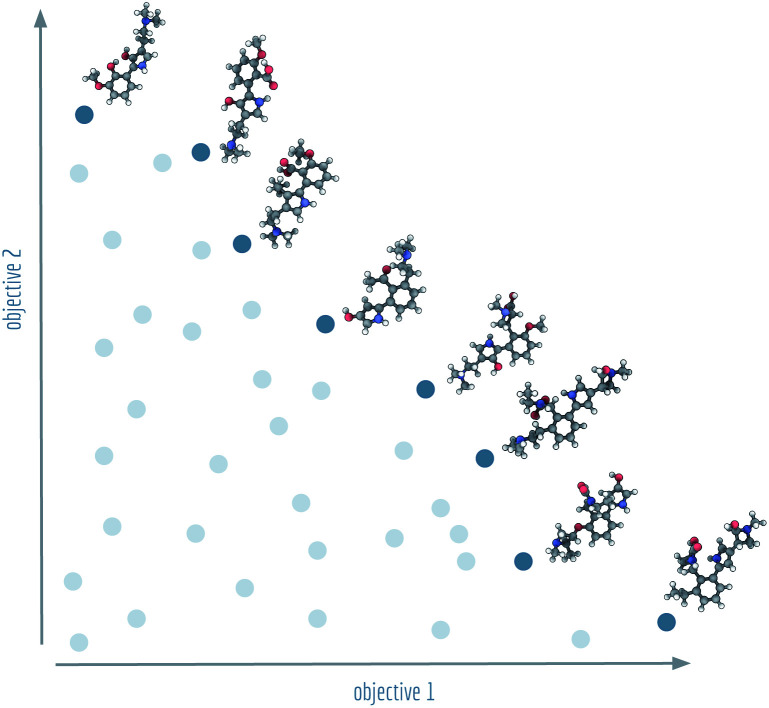
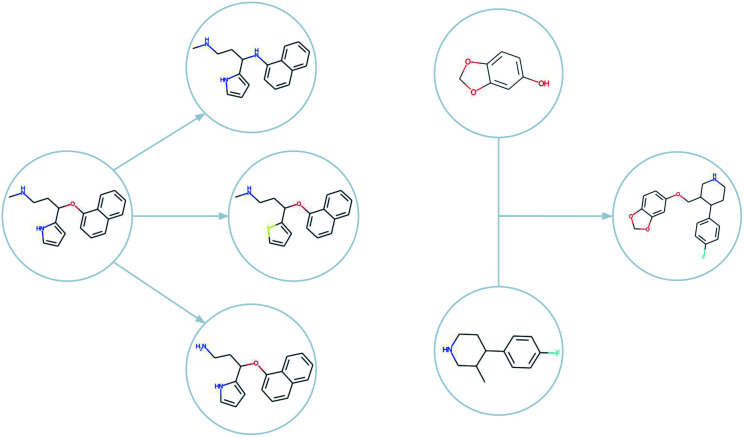
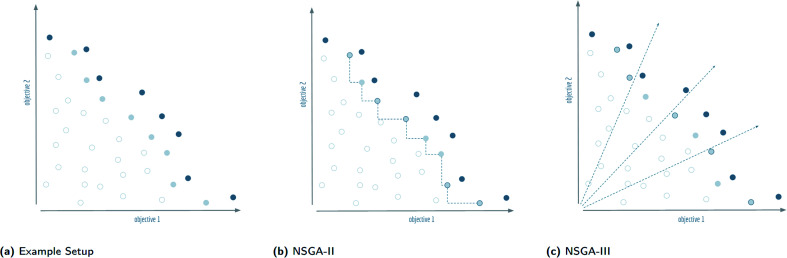
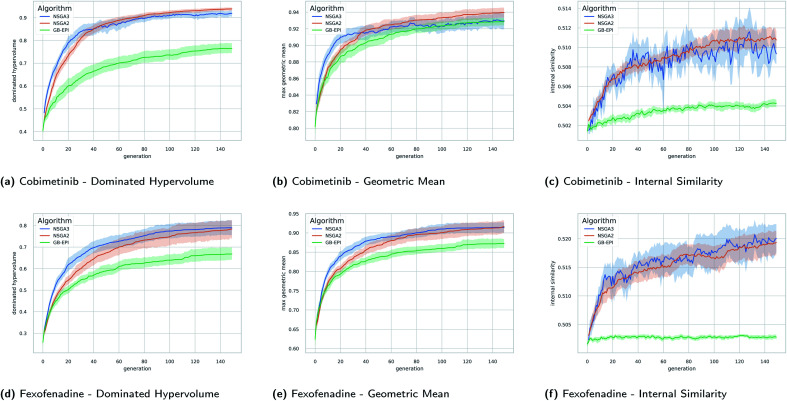
Computer-assisted design of small molecules has experienced a resurgence in academic and industrial interest due to the widespread use of data-driven techniques such as deep generative models. While the ability to generate molecules that fulfil required chemical properties is encouraging, the use of deep learning models requires significant, if not prohibitive, amounts of data and computational power. At the same time, open-sourcing of more traditional techniques such as graph-based genetic algorithms for molecular optimisation [Jensen, Chem. Sci., 2019, 12, 3567-3572] has shown that simple and training-free algorithms can be efficient and robust alternatives. Further research alleviated the common genetic algorithm issue of evolutionary stagnation by enforcing molecular diversity during optimisation [Van den Abeele, Chem. Sci., 2020, 42, 11485-11491]. The crucial lesson distilled from the simultaneous development of deep generative models and advanced genetic algorithms has been the importance of chemical space exploration [Aspuru-Guzik, Chem. Sci., 2021, 12, 7079-7090]. For single-objective optimisation problems, chemical space exploration had to be discovered as a useable resource but in multi-objective optimisation problems, an exploration of trade-offs between conflicting objectives is inherently present. In this paper we provide state-of-the-art and open-source implementations of two generations of graph-based non-dominated sorting genetic algorithms (NSGA-II, NSGA-III) for molecular multi-objective optimisation. We provide the results of a series of benchmarks for the inverse design of small molecule drugs for both the NSGA-II and NSGA-III algorithms. In addition, we introduce the dominated hypervolume and extended fingerprint based internal similarity as novel metrics for these benchmarks. By design, NSGA-II, and NSGA-III outperform a single optimisation method baseline in terms of dominated hypervolume, but remarkably our results show they do so without relying on a greater internal chemical diversity.
This journal is © The Royal Society of Chemistry.
Conflict of interest statement
There are no conflicts to declare.
Figures

References
LinkOut - more resources
Full Text Sources