

Reconstructing Superquadrics from Intensity and Color Images
- PMID: 35891011
- PMCID: PMC9319097
- DOI: 10.3390/s22145332
Reconstructing Superquadrics from Intensity and Color Images
Abstract
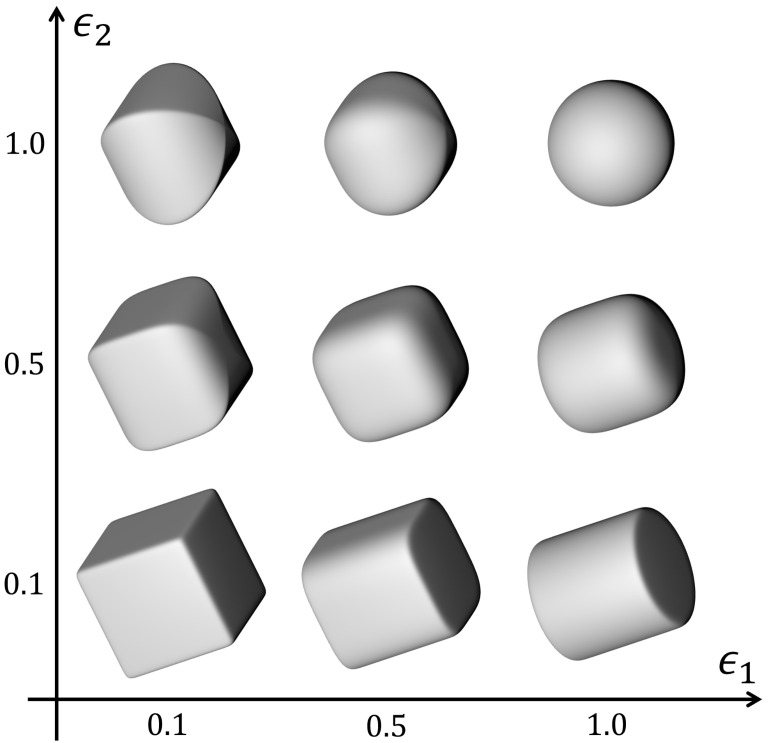
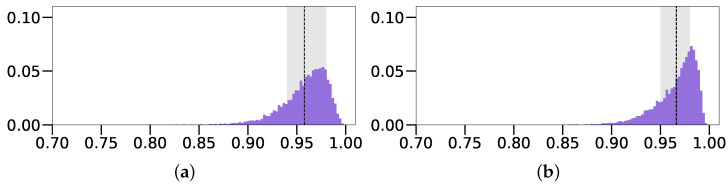
The task of reconstructing 3D scenes based on visual data represents a longstanding problem in computer vision. Common reconstruction approaches rely on the use of multiple volumetric primitives to describe complex objects. Superquadrics (a class of volumetric primitives) have shown great promise due to their ability to describe various shapes with only a few parameters. Recent research has shown that deep learning methods can be used to accurately reconstruct random superquadrics from both 3D point cloud data and simple depth images. In this paper, we extended these reconstruction methods to intensity and color images. Specifically, we used a dedicated convolutional neural network (CNN) model to reconstruct a single superquadric from the given input image. We analyzed the results in a qualitative and quantitative manner, by visualizing reconstructed superquadrics as well as observing error and accuracy distributions of predictions. We showed that a CNN model designed around a simple ResNet backbone can be used to accurately reconstruct superquadrics from images containing one object, but only if one of the spatial parameters is fixed or if it can be determined from other image characteristics, e.g., shadows. Furthermore, we experimented with images of increasing complexity, for example, by adding textures, and observed that the results degraded only slightly. In addition, we show that our model outperforms the current state-of-the-art method on the studied task. Our final result is a highly accurate superquadric reconstruction model, which can also reconstruct superquadrics from real images of simple objects, without additional training.
Keywords: color images; convolutional neural networks; deep learning; reconstruction; superquadrics.
Conflict of interest statement
The authors declare no conflict of interest.
Figures












References
-
- Barr A.H. Superquadrics and angle-preserving transformations. IEEE Comput. Graph. Appl. 1981;1:11–23. doi: 10.1109/MCG.1981.1673799. - DOI
-
- Solina F., Bajcsy R. Recovery of parametric models from range images: The case for superquadrics with global deformations. IEEE Trans. Pattern Anal. Mach. Intell. 1990;12:131–147. doi: 10.1109/34.44401. - DOI
-
- Khosla P., Volpe R. Superquadric artificial potentials for obstacle avoidance and approach; Proceedings of the IEEE International Conference on Robotics and Automation; Philadelphia, PA, USA. 24–29 April 1988; pp. 1778–1784. - DOI
-
- Smith N.E., Cobb R.G., Baker W.P. Incorporating stochastics into optimal collision avoidance problems using superquadrics. J. Air Transp. 2020;28:65–69. doi: 10.2514/1.D0170. - DOI
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
