

Neural responses in human superior temporal cortex support coding of voice representations
- PMID: 35900975
- PMCID: PMC9333263
- DOI: 10.1371/journal.pbio.3001675
Neural responses in human superior temporal cortex support coding of voice representations
Abstract
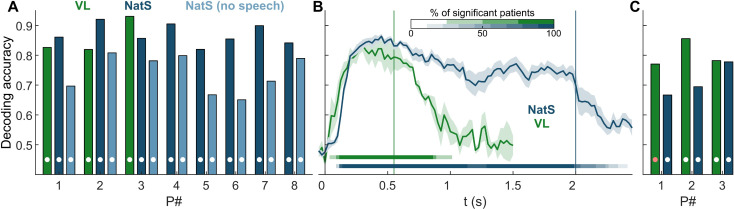
The ability to recognize abstract features of voice during auditory perception is an intricate feat of human audition. For the listener, this occurs in near-automatic fashion to seamlessly extract complex cues from a highly variable auditory signal. Voice perception depends on specialized regions of auditory cortex, including superior temporal gyrus (STG) and superior temporal sulcus (STS). However, the nature of voice encoding at the cortical level remains poorly understood. We leverage intracerebral recordings across human auditory cortex during presentation of voice and nonvoice acoustic stimuli to examine voice encoding at the cortical level in 8 patient-participants undergoing epilepsy surgery evaluation. We show that voice selectivity increases along the auditory hierarchy from supratemporal plane (STP) to the STG and STS. Results show accurate decoding of vocalizations from human auditory cortical activity even in the complete absence of linguistic content. These findings show an early, less-selective temporal window of neural activity in the STG and STS followed by a sustained, strongly voice-selective window. Encoding models demonstrate divergence in the encoding of acoustic features along the auditory hierarchy, wherein STG/STS responses are best explained by voice category and acoustics, as opposed to acoustic features of voice stimuli alone. This is in contrast to neural activity recorded from STP, in which responses were accounted for by acoustic features. These findings support a model of voice perception that engages categorical encoding mechanisms within STG and STS to facilitate feature extraction.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures



Comment in
-
The path of voices in our brain.PLoS Biol. 2022 Jul 29;20(7):e3001742. doi: 10.1371/journal.pbio.3001742. eCollection 2022 Jul. PLoS Biol. 2022. PMID: 35905075 Free PMC article.
References
-
- Mathias S. R., von Kriegstein K. Voice Processing and Voice-Identity Recognition. in Timbre: Acoustics, Perception, and Cognition (eds. Siedenburg K., Saitis C., McAdams S., Popper A. N., Fay R. R.) 175–209. Springer International Publishing; 2019. doi: 10.1007/978-3-030-14832-4_7 - DOI
-
- Hepper PG, Scott D, Shahidullah S. Newborn and fetal response to maternal voice. J Reprod Infant Psychol. 1993;11:147–53.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
