

Virtual contrast enhancement for CT scans of abdomen and pelvis
- PMID: 35914340
- PMCID: PMC10227907
- DOI: 10.1016/j.compmedimag.2022.102094
Virtual contrast enhancement for CT scans of abdomen and pelvis
Abstract
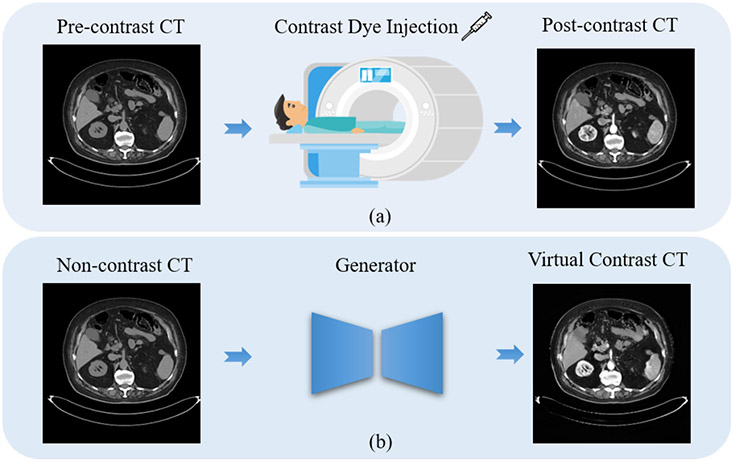
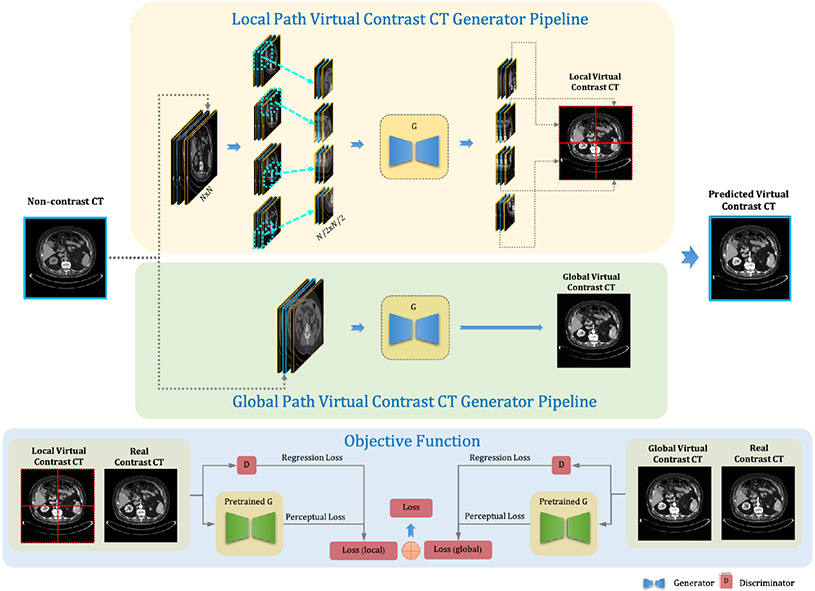
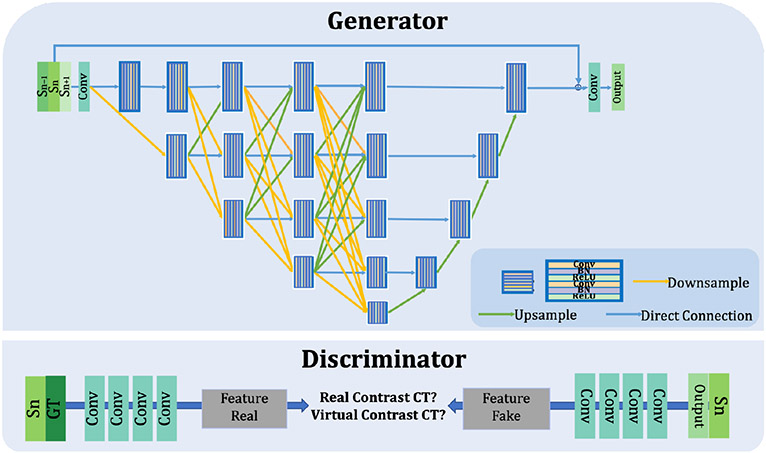
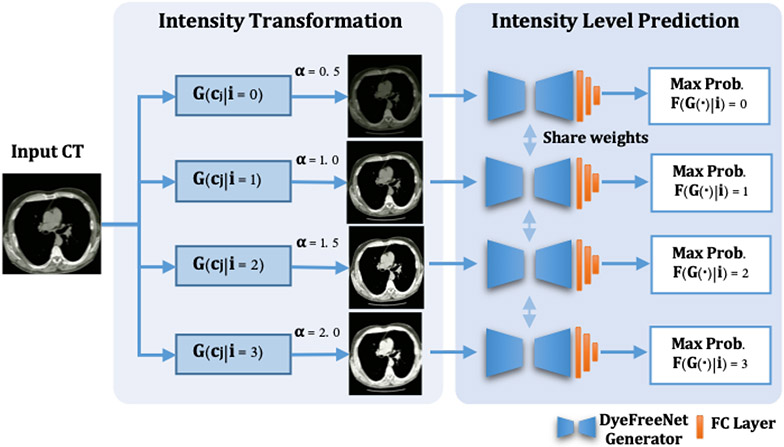
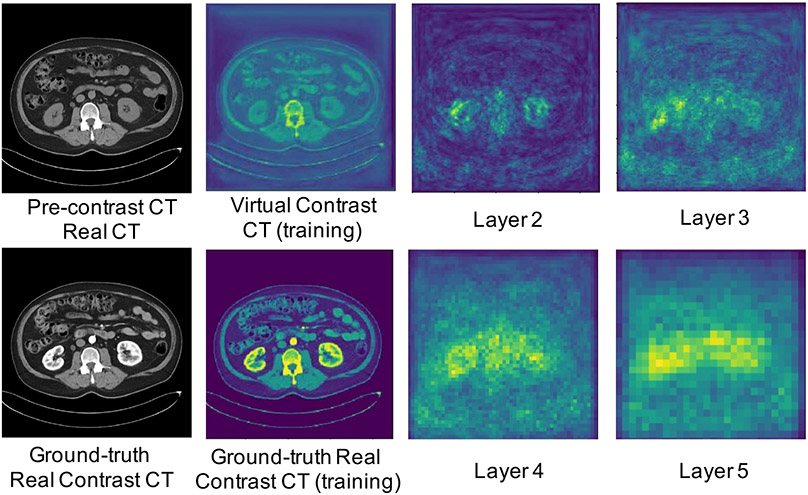
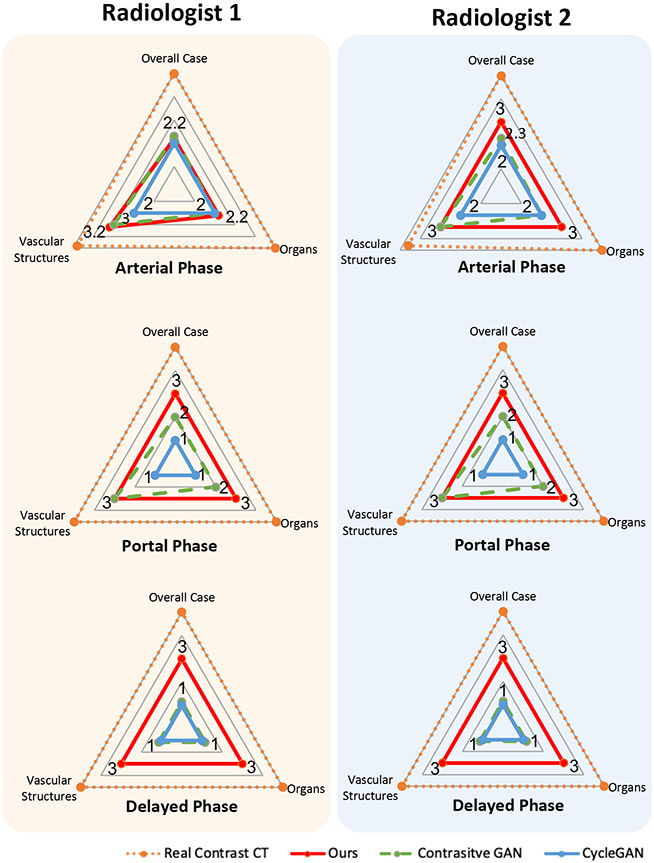
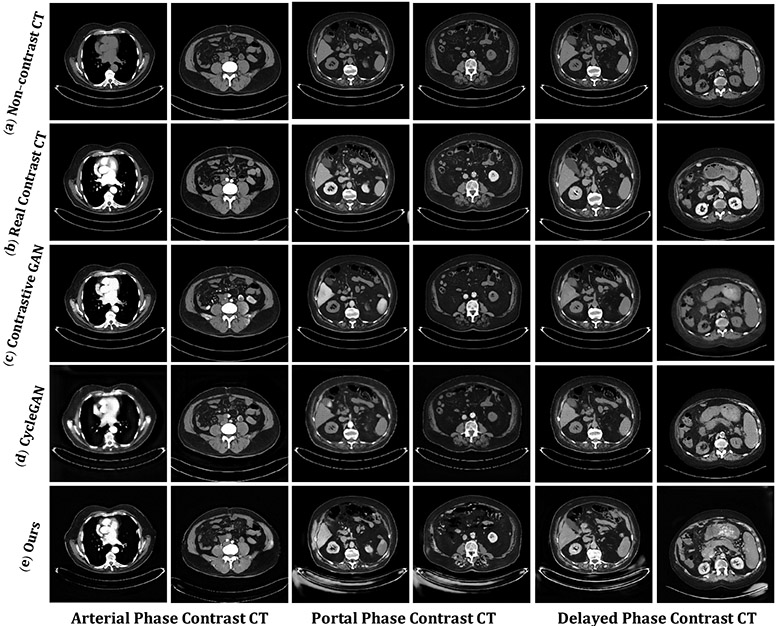
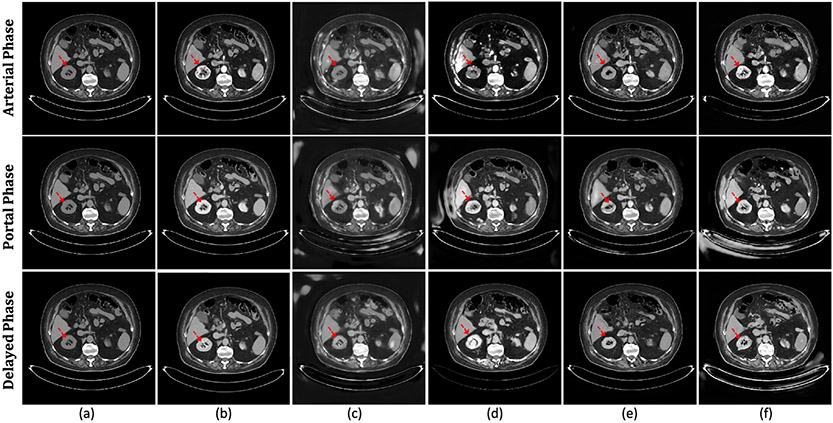
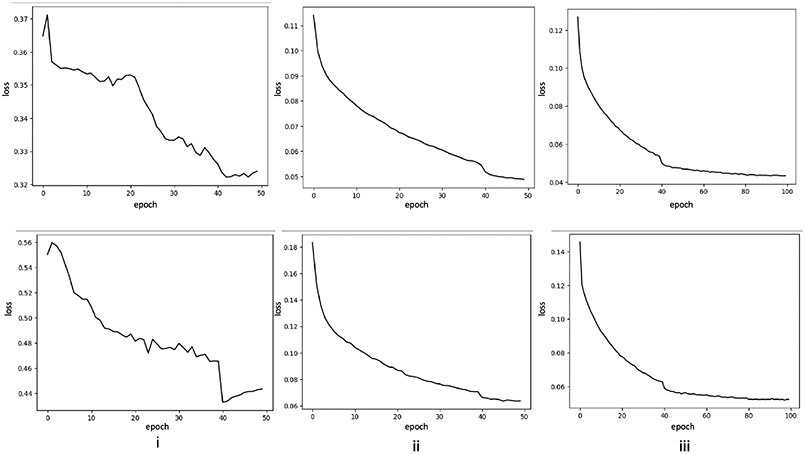
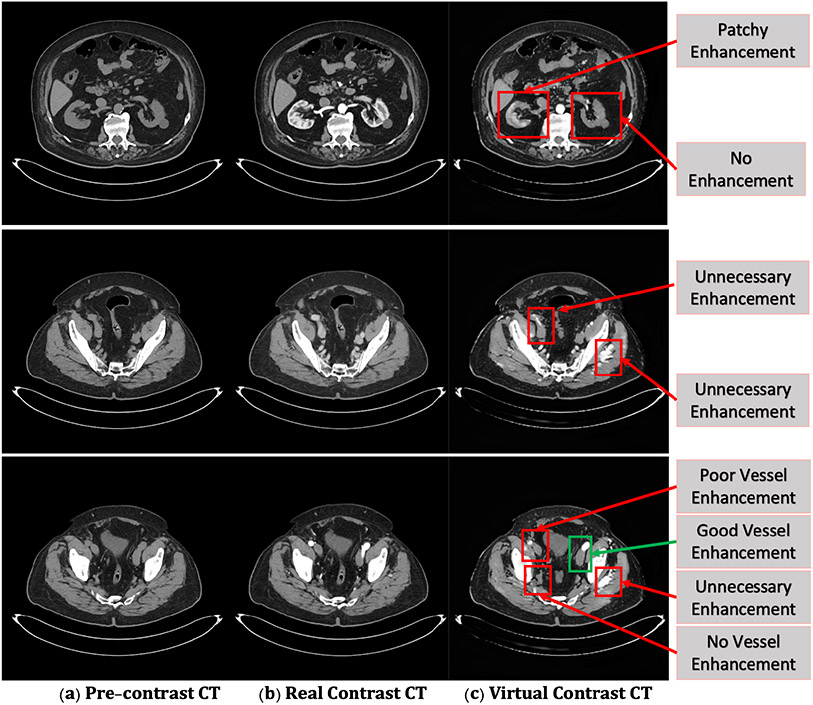
Contrast agents are commonly used to highlight blood vessels, organs, and other structures in magnetic resonance imaging (MRI) and computed tomography (CT) scans. However, these agents may cause allergic reactions or nephrotoxicity, limiting their use in patients with kidney dysfunctions. In this paper, we propose a generative adversarial network (GAN) based framework to automatically synthesize contrast-enhanced CTs directly from the non-contrast CTs in the abdomen and pelvis region. The respiratory and peristaltic motion can affect the pixel-level mapping of contrast-enhanced learning, which makes this task more challenging than other body parts. A perceptual loss is introduced to compare high-level semantic differences of the enhancement areas between the virtual contrast-enhanced and actual contrast-enhanced CT images. Furthermore, to accurately synthesize the intensity details as well as remain texture structures of CT images, a dual-path training schema is proposed to learn the texture and structure features simultaneously. Experiment results on three contrast phases (i.e. arterial, portal, and delayed phase) show the potential to synthesize virtual contrast-enhanced CTs directly from non-contrast CTs of the abdomen and pelvis for clinical evaluation.
Keywords: Contrast enhanced CT; Deep learning; Generative adversarial network; Image synthesize.
Copyright © 2022 Elsevier Ltd. All rights reserved.
Conflict of interest statement
Declaration of competing interest The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Figures
Similar articles
-
Body region localization in whole-body low-dose CT images of PET/CT scans using virtual landmarks.Med Phys. 2019 Mar;46(3):1286-1299. doi: 10.1002/mp.13376. Epub 2019 Jan 24. Med Phys. 2019. PMID: 30609058 Free PMC article.
-
Transforming UTE-mDixon MR Abdomen-Pelvis Images Into CT by Jointly Leveraging Prior Knowledge and Partial Supervision.IEEE/ACM Trans Comput Biol Bioinform. 2021 Jan-Feb;18(1):70-82. doi: 10.1109/TCBB.2020.2979841. Epub 2021 Feb 3. IEEE/ACM Trans Comput Biol Bioinform. 2021. PMID: 32175868 Free PMC article.
-
Multiphase acquisitions in pediatric abdominal-pelvic CT are a common practice and contribute to unnecessary radiation dose.Pediatr Radiol. 2018 Nov;48(12):1714-1723. doi: 10.1007/s00247-018-4192-y. Epub 2018 Jul 7. Pediatr Radiol. 2018. PMID: 29980861
-
Virtual Non-contrast Imaging in The Abdomen and The Pelvis: An Overview.Semin Ultrasound CT MR. 2022 Aug;43(4):293-310. doi: 10.1053/j.sult.2022.03.004. Epub 2022 Mar 18. Semin Ultrasound CT MR. 2022. PMID: 35738815 Review.
-
Vascular applications of ferumoxytol-enhanced magnetic resonance imaging of the abdomen and pelvis.Abdom Radiol (NY). 2021 May;46(5):2203-2218. doi: 10.1007/s00261-020-02817-8. Epub 2020 Oct 22. Abdom Radiol (NY). 2021. PMID: 33090256 Review.
Cited by
-
Simulating dynamic tumor contrast enhancement in breast MRI using conditional generative adversarial networks.J Med Imaging (Bellingham). 2025 Nov;12(Suppl 2):S22014. doi: 10.1117/1.JMI.12.S2.S22014. Epub 2025 Jun 28. J Med Imaging (Bellingham). 2025. PMID: 40584874
-
Special Issue: Artificial Intelligence in Advanced Medical Imaging.Bioengineering (Basel). 2024 Dec 5;11(12):1229. doi: 10.3390/bioengineering11121229. Bioengineering (Basel). 2024. PMID: 39768047 Free PMC article.
-
Deep Learning on Misaligned Dual-Energy Chest X-ray Images Using Paired Cycle-Consistent Generative Adversarial Networks.J Imaging Inform Med. 2025 May 5. doi: 10.1007/s10278-025-01508-4. Online ahead of print. J Imaging Inform Med. 2025. PMID: 40325327
References
-
- Liu J, Li M, Wang J, Wu F, Liu T, Pan Y, A survey of MRI-based brain tumor segmentation methods, Tsinghua Science and Technology 19 (6) (2014) 578–595.
-
- Litjens G, Kooi T, Bejnordi BE, Setio AAA, Ciompi F, Ghafoorian M, et al., A survey on deep learning in medical image analysis, Medical image analysis 42 (2017) 60–88. - PubMed
-
- Brenner DJ, Hricak H, Radiation exposure from medical imaging: time to regulate?, Jama 304 (2) (2010) 208–209. - PubMed
-
- Beckett KR, Moriarity AK, Langer JM, Safe use of contrast media: what the radiologist needs to know, Radiographics 35 (6) (2015) 1738–1750. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Medical
Research Materials
