

Social capital II: determinants of economic connectedness
- PMID: 35915343
- PMCID: PMC9352593
- DOI: 10.1038/s41586-022-04997-3
Social capital II: determinants of economic connectedness
Abstract
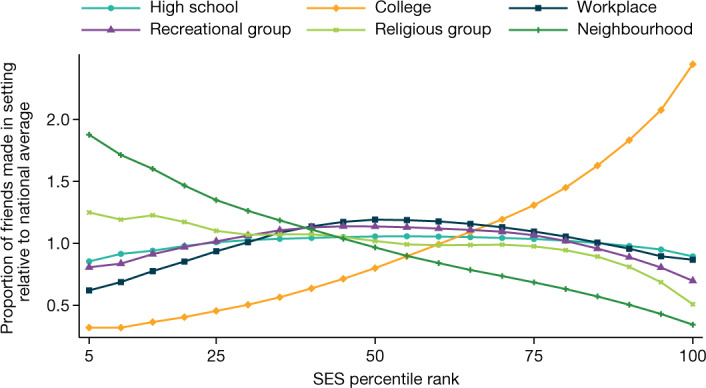
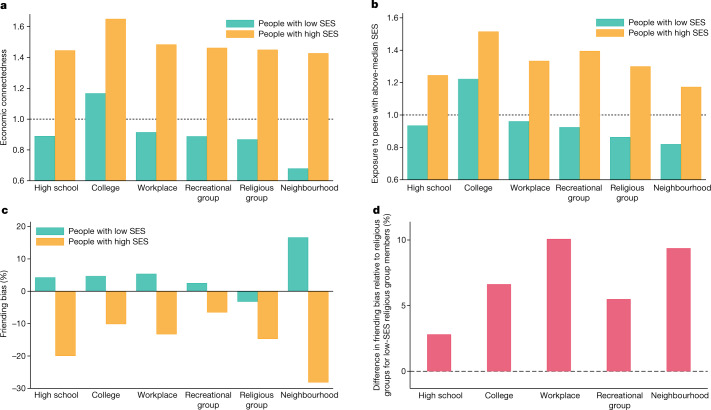
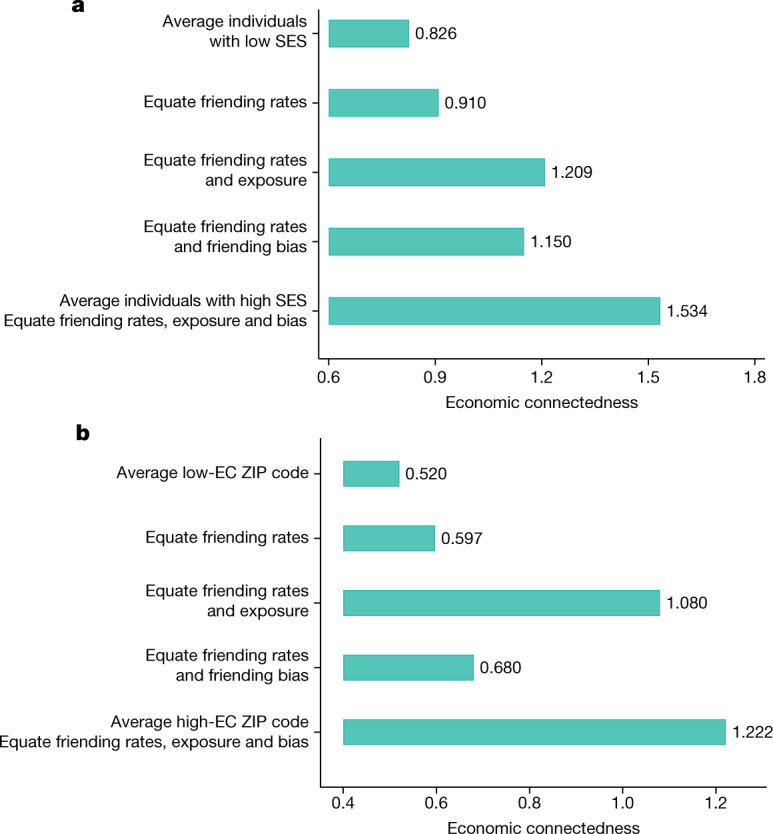
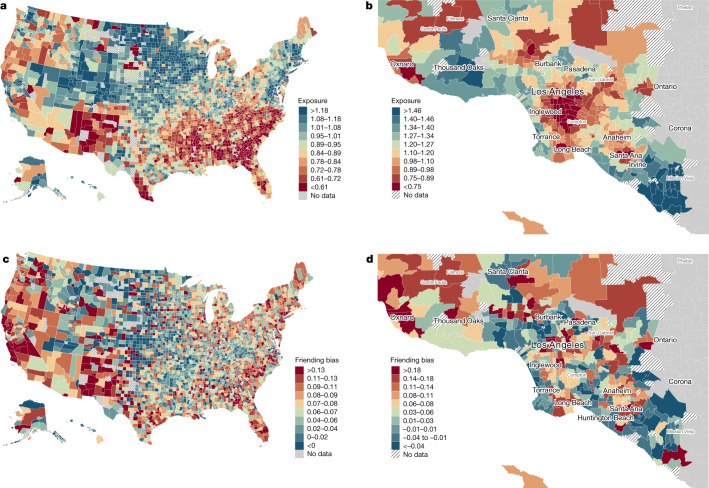
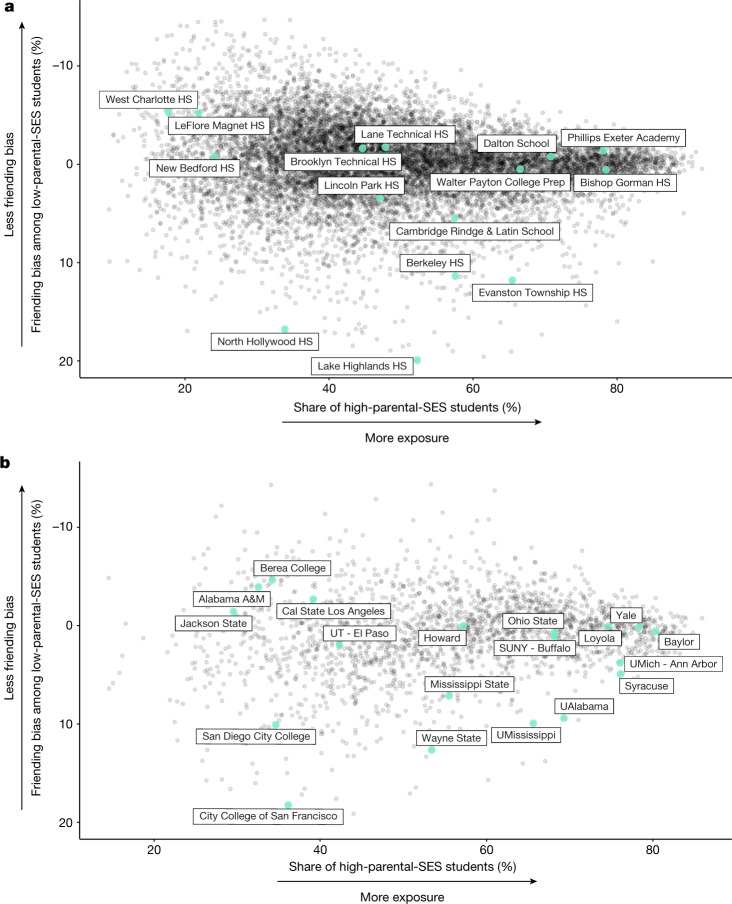
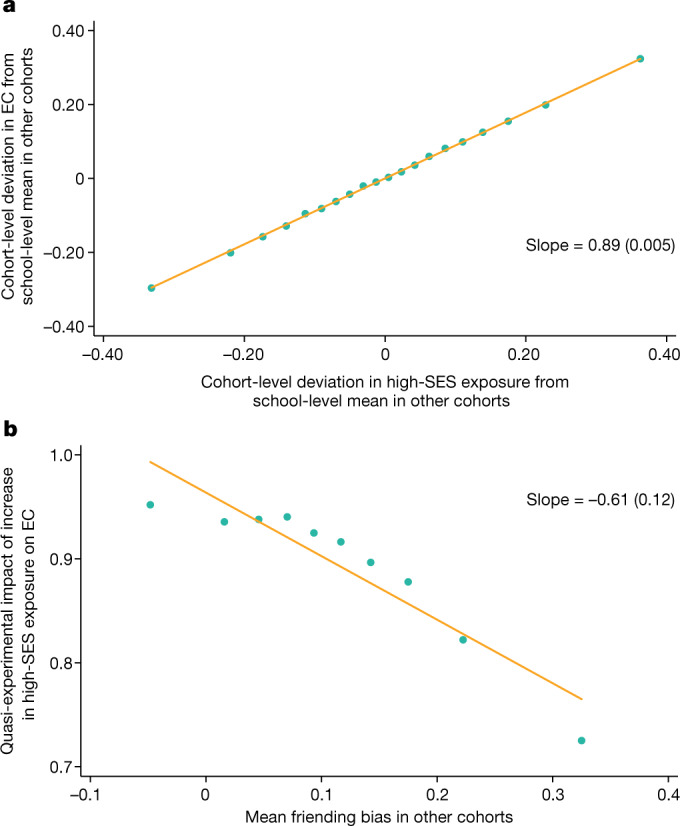
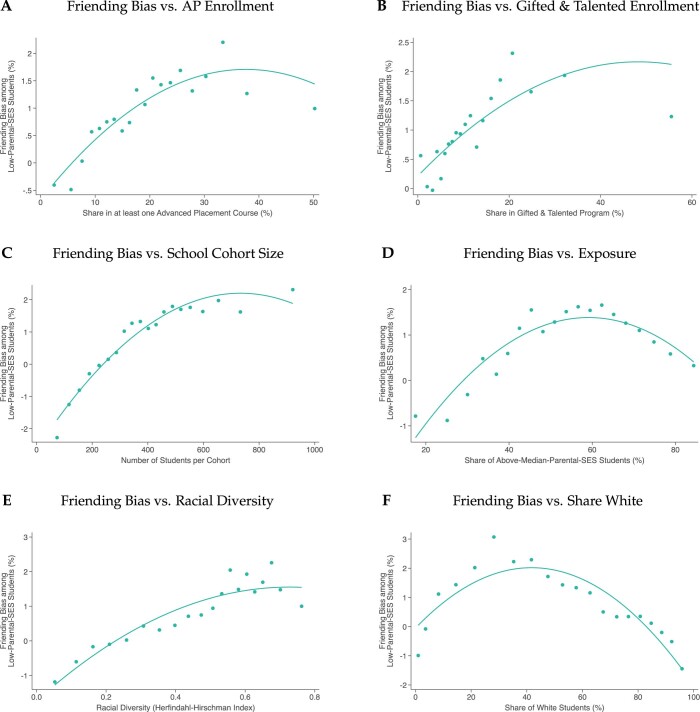
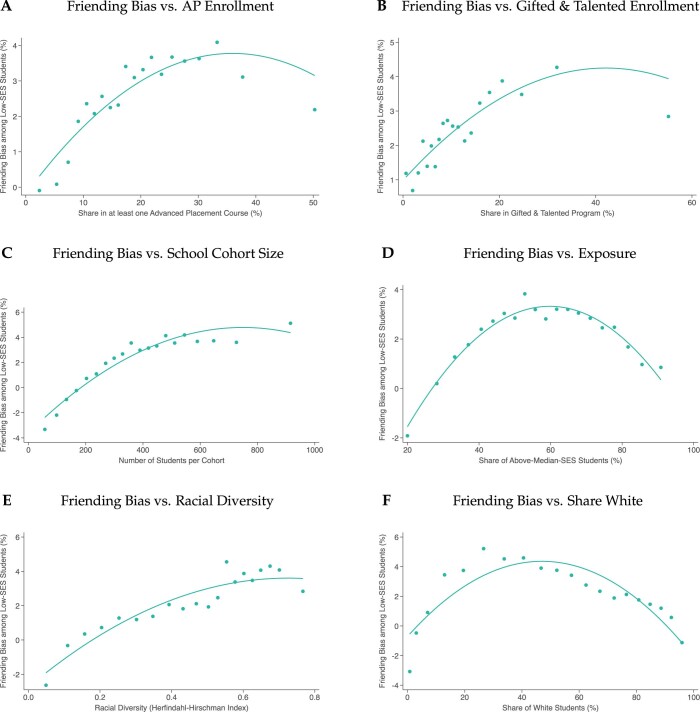
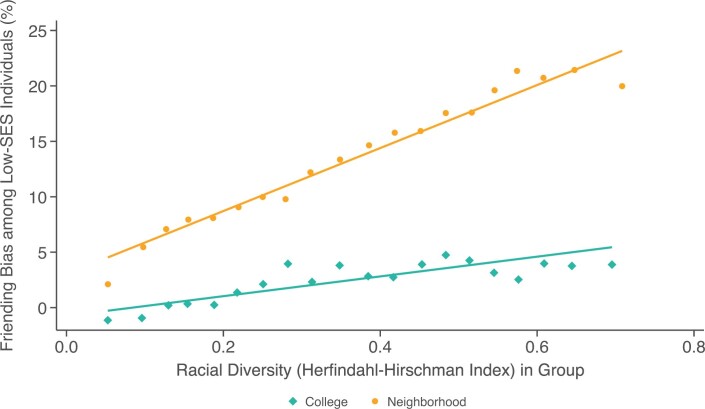
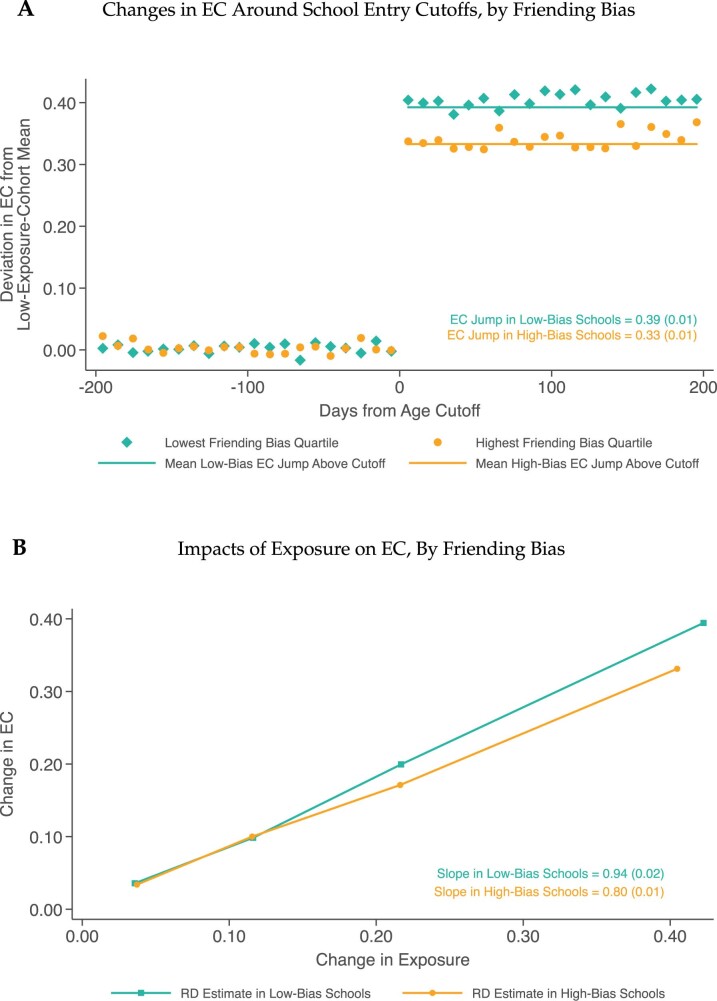
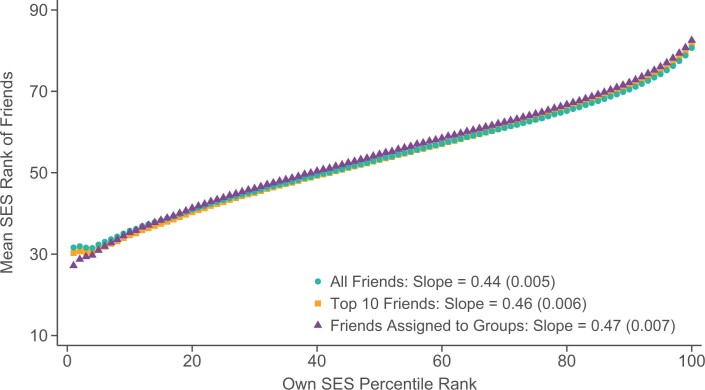
Low levels of social interaction across class lines have generated widespread concern1-4 and are associated with worse outcomes, such as lower rates of upward income mobility4-7. Here we analyse the determinants of cross-class interaction using data from Facebook, building on the analysis in our companion paper7. We show that about half of the social disconnection across socioeconomic lines-measured as the difference in the share of high-socioeconomic status (SES) friends between people with low and high SES-is explained by differences in exposure to people with high SES in groups such as schools and religious organizations. The other half is explained by friending bias-the tendency for people with low SES to befriend people with high SES at lower rates even conditional on exposure. Friending bias is shaped by the structure of the groups in which people interact. For example, friending bias is higher in larger and more diverse groups and lower in religious organizations than in schools and workplaces. Distinguishing exposure from friending bias is helpful for identifying interventions to increase cross-SES friendships (economic connectedness). Using fluctuations in the share of students with high SES across high school cohorts, we show that increases in high-SES exposure lead low-SES people to form more friendships with high-SES people in schools that exhibit low levels of friending bias. Thus, socioeconomic integration can increase economic connectedness in communities in which friending bias is low. By contrast, when friending bias is high, increasing cross-SES interactions among existing members may be necessary to increase economic connectedness. To support such efforts, we release privacy-protected statistics on economic connectedness, exposure and friending bias for each ZIP (postal) code, high school and college in the United States at https://www.socialcapital.org .
© 2022. The Author(s).
Conflict of interest statement
In 2018, T.K. and J.S. received an unrestricted gift from Facebook to NYU Stern. Opportunity Insights receives core funding from the Chan Zuckerberg Foundation (CZI). CZI is a separate entity from Meta, and CZI funding to Opportunity Insights was not used for this research. M.B, P.B., M.B. and N.W. are employees of Meta Platforms. T.K., J.S., S.G. and F.M. are contract affiliates through Meta’s contract with PRO Unlimited. F.G., A.G., M.J., D.J., M.K., T.R., N.T, W.T. and R.Z. are contract affiliates through Meta’s contract with Harvard University. Meta Platforms did not dispute or influence any findings or conclusions during their collaboration on this research. This work was produced under an agreement between Meta and Harvard University specifying that Harvard shall own all intellectual property rights, titles and interests (subject to the restrictions of any journal or publisher of the resulting publication(s)).
Figures
Comment in
-
The social connections that shape economic prospects.Nature. 2022 Aug;608(7921):37-38. doi: 10.1038/d41586-022-01843-4. Nature. 2022. PMID: 35915246 No abstract available.
Similar articles
-
Social capital I: measurement and associations with economic mobility.Nature. 2022 Aug;608(7921):108-121. doi: 10.1038/s41586-022-04996-4. Epub 2022 Aug 1. Nature. 2022. PMID: 35915342 Free PMC article.
-
Bridging social capital among Facebook users and COVID-19 cases growth in Arizona.Soc Sci Med. 2024 Nov;360:117313. doi: 10.1016/j.socscimed.2024.117313. Epub 2024 Sep 12. Soc Sci Med. 2024. PMID: 39270574 Review.
-
The mediating role of social capital in the relationship between socioeconomic status and adolescent wellbeing: evidence from Ghana.BMC Public Health. 2020 Jan 7;20(1):20. doi: 10.1186/s12889-019-8142-x. BMC Public Health. 2020. PMID: 31910835 Free PMC article.
-
Does socioeconomic status moderate the relationships between school connectedness with psychological distress, suicidal ideation and attempts in adolescents?Prev Med. 2016 Jun;87:11-17. doi: 10.1016/j.ypmed.2016.02.010. Epub 2016 Feb 12. Prev Med. 2016. PMID: 26876628
-
Socioeconomic factors and breast carcinoma in multicultural women.Cancer. 2000 Mar 1;88(5 Suppl):1256-64. doi: 10.1002/(sici)1097-0142(20000301)88:5+<1256::aid-cncr13>3.0.co;2-3. Cancer. 2000. PMID: 10705364 Review.
Cited by
-
Human mobility networks reveal increased segregation in large cities.Nature. 2023 Dec;624(7992):586-592. doi: 10.1038/s41586-023-06757-3. Epub 2023 Nov 29. Nature. 2023. PMID: 38030732 Free PMC article.
-
Carbon dating challenge, friendship economics - the week in infographics.Nature. 2022 Aug 3. doi: 10.1038/d41586-022-02109-9. Online ahead of print. Nature. 2022. PMID: 35922493 No abstract available.
-
Association of Population Well-Being With Cardiovascular Outcomes.JAMA Netw Open. 2023 Jul 3;6(7):e2321740. doi: 10.1001/jamanetworkopen.2023.21740. JAMA Netw Open. 2023. PMID: 37405774 Free PMC article.
-
Long ties, disruptive life events, and economic prosperity.Proc Natl Acad Sci U S A. 2023 Jul 11;120(28):e2211062120. doi: 10.1073/pnas.2211062120. Epub 2023 Jul 6. Proc Natl Acad Sci U S A. 2023. PMID: 37410864 Free PMC article.
-
Cognitive representations of social networks in isolated villages.Nat Hum Behav. 2025 Jun 16:10.1038/s41562-025-02221-6. doi: 10.1038/s41562-025-02221-6. Online ahead of print. Nat Hum Behav. 2025. PMID: 40523958 Free PMC article.
References
-
- Fischer CS, Mattson G. Is America fragmenting? Ann. Rev. Sociol. 2009;35:435–455. doi: 10.1146/annurev-soc-070308-115909. - DOI
-
- Smith JA, McPherson M, Smith-Lovin L. Social distance in the United States: sex, race, religion, age, and education homophily among confidants, 1985 to 2004. Am. Sociol. Rev. 2014;79:432–456. doi: 10.1177/0003122414531776. - DOI
-
- Doob, C. B. Social Inequality and Social Stratification in US Society (Routledge, 2019).
-
- Putnam, R. D. Our Kids: The American Dream in Crisis (Simon and Schuster, 2016).
-
- Alesina A, Baqir R, Easterly W. Public goods and ethnic divisions. Q. J. Econ. 1999;114:1243–1284. doi: 10.1162/003355399556269. - DOI
MeSH terms
LinkOut - more resources
Full Text Sources
