

A Syntactic Information-Based Classification Model for Medical Literature: Algorithm Development and Validation Study
- PMID: 35917162
- PMCID: PMC9382554
- DOI: 10.2196/37817
A Syntactic Information-Based Classification Model for Medical Literature: Algorithm Development and Validation Study
Abstract
Background: The ever-increasing volume of medical literature necessitates the classification of medical literature. Medical relation extraction is a typical method of classifying a large volume of medical literature. With the development of arithmetic power, medical relation extraction models have evolved from rule-based models to neural network models. The single neural network model discards the shallow syntactic information while discarding the traditional rules. Therefore, we propose a syntactic information-based classification model that complements and equalizes syntactic information to enhance the model.
Objective: We aim to complete a syntactic information-based relation extraction model for more efficient medical literature classification.
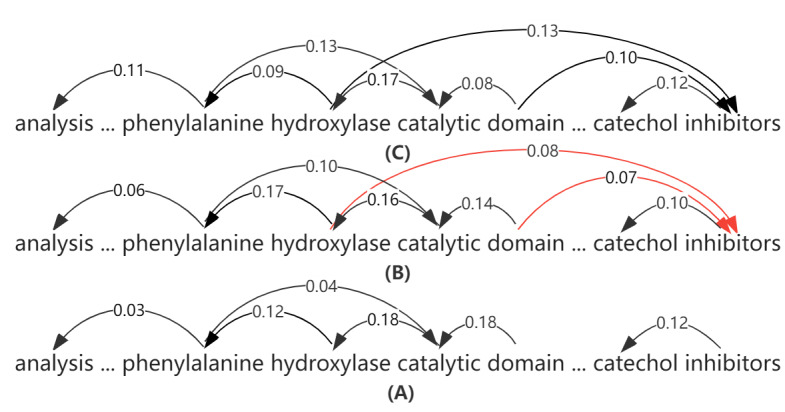
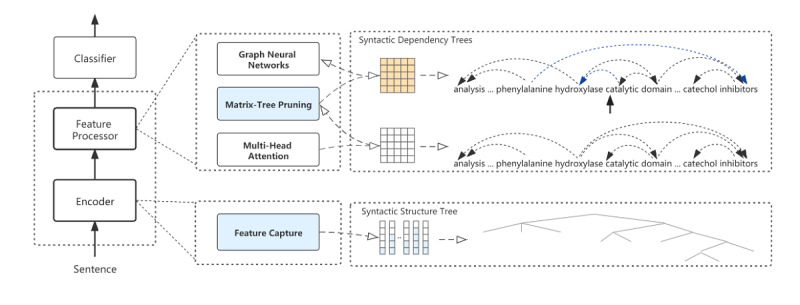
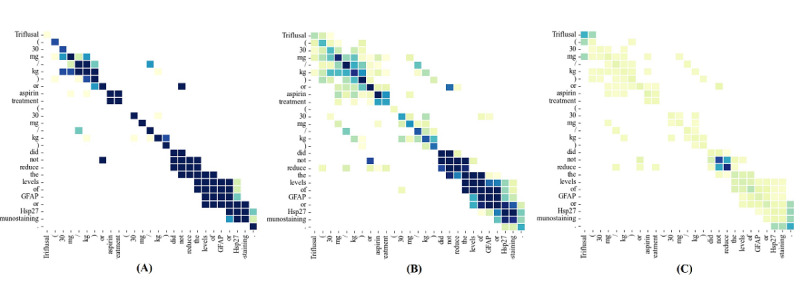
Methods: We devised 2 methods for enhancing syntactic information in the model. First, we introduced shallow syntactic information into the convolutional neural network to enhance nonlocal syntactic interactions. Second, we devise a cross-domain pruning method to equalize local and nonlocal syntactic interactions.
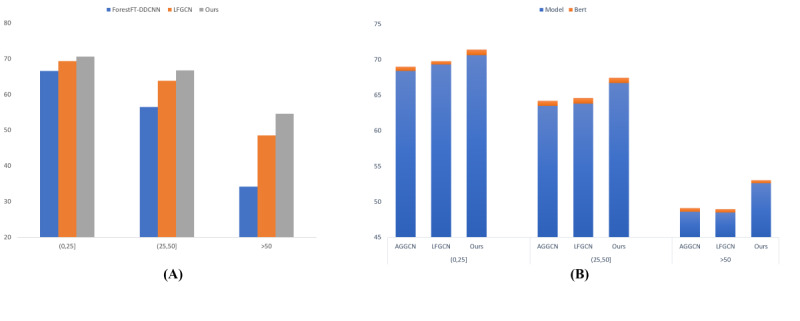
Results: We experimented with 3 data sets related to the classification of medical literature. The F1 values were 65.5% and 91.5% on the BioCreative ViCPR (CPR) and Phenotype-Gene Relationship data sets, respectively, and the accuracy was 88.7% on the PubMed data set. Our model outperforms the current state-of-the-art baseline model in the experiments.
Conclusions: Our model based on syntactic information effectively enhances medical relation extraction. Furthermore, the results of the experiments show that shallow syntactic information helps obtain nonlocal interaction in sentences and effectively reinforces syntactic features. It also provides new ideas for future research directions.
Keywords: classification; extraction; interaction; literature; medical literature; medical relation extraction; medical text; neural networks; pruning method; semantic; syntactic; syntactic features; text.
©Wentai Tang, Jian Wang, Hongfei Lin, Di Zhao, Bo Xu, Yijia Zhang, Zhihao Yang. Originally published in JMIR Medical Informatics (https://medinform.jmir.org), 02.08.2022.
Conflict of interest statement
Conflicts of Interest: None declared.
Figures
References
-
- Heeman PA, Allen JF. Incorporating POS Tagging Into Language Modeling. Fifth European Conference on Speech Communication and Technology, EUROSPEECH; September 22-25, 1997; Rhodes. 1997. https://www.cs.rochester.edu/research/cisd/pubs/1997/paper1.pdf
-
- Wright JH, Jones GJF, Lloyd-Thomas H. A robust language model incorporating a substring parser and extended n-grams. ICASSP '94. IEEE International Conference on Acoustics, Speech and Signal Processing; April 19-22, 1994; Adelaide, SA. 1994. - DOI
-
- Merity S, Keskar NS, Socher R. Regularizing and optimizing LSTM language models. 6th International Conference on Learning Representations, ICLR 2018; April 30 - May 3, 2018; Vancouver, BC. 2018.
-
- Peng N, Poon H, Quirk C, Toutanova K, Yih W. Cross-Sentence N-ary Relation Extraction with Graph LSTMs. TACL. 2017 Dec;5:101–115. doi: 10.1162/tacl_a_00049. - DOI
-
- Linfeng S, Yue Z, Zhiguo W. N-ary Relation Extraction using Graph-State LSTM. 2018 Conference on Empirical Methods in Natural Language Processing; October 31, 2018; Brussels. 2018. - DOI
LinkOut - more resources
Full Text Sources
