

Prediction of Smoking Habits From Class-Imbalanced Saliva Microbiome Data Using Data Augmentation and Machine Learning
- PMID: 35928158
- PMCID: PMC9343866
- DOI: 10.3389/fmicb.2022.886201
Prediction of Smoking Habits From Class-Imbalanced Saliva Microbiome Data Using Data Augmentation and Machine Learning
Abstract
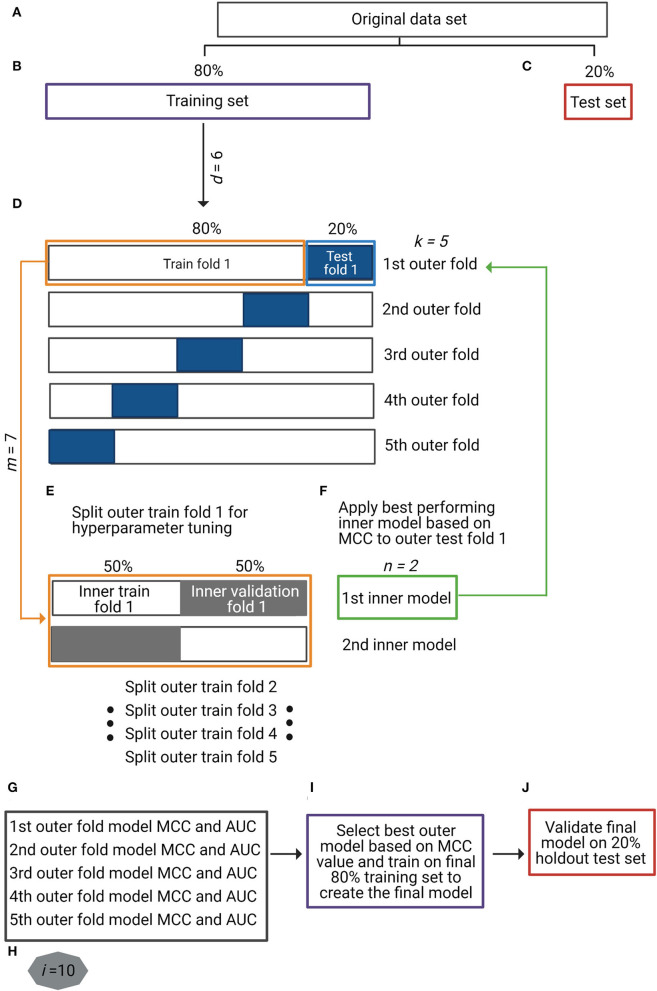
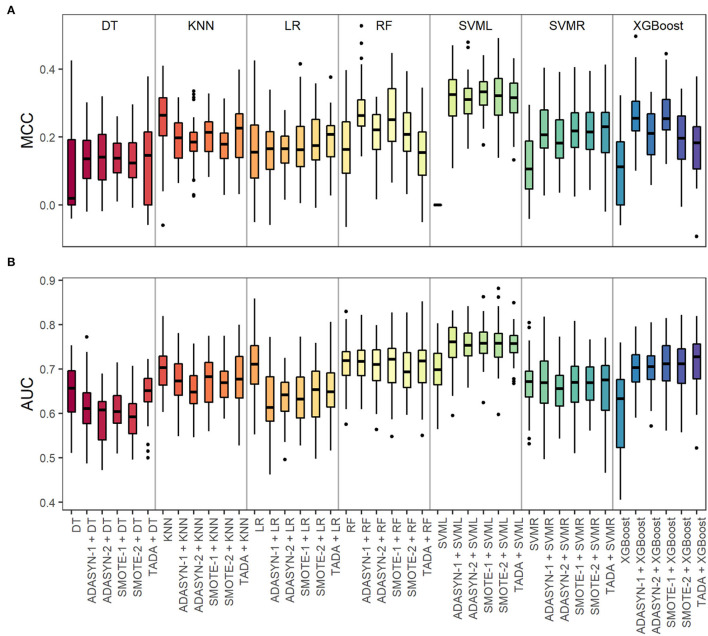
Human microbiome research is moving from characterization and association studies to translational applications in medical research, clinical diagnostics, and others. One of these applications is the prediction of human traits, where machine learning (ML) methods are often employed, but face practical challenges. Class imbalance in available microbiome data is one of the major problems, which, if unaccounted for, leads to spurious prediction accuracies and limits the classifier's generalization. Here, we investigated the predictability of smoking habits from class-imbalanced saliva microbiome data by combining data augmentation techniques to account for class imbalance with ML methods for prediction. We collected publicly available saliva 16S rRNA gene sequencing data and smoking habit metadata demonstrating a serious class imbalance problem, i.e., 175 current vs. 1,070 non-current smokers. Three data augmentation techniques (synthetic minority over-sampling technique, adaptive synthetic, and tree-based associative data augmentation) were applied together with seven ML methods: logistic regression, k-nearest neighbors, support vector machine with linear and radial kernels, decision trees, random forest, and extreme gradient boosting. K-fold nested cross-validation was used with the different augmented data types and baseline non-augmented data to validate the prediction outcome. Combining data augmentation with ML generally outperformed baseline methods in our dataset. The final prediction model combined tree-based associative data augmentation and support vector machine with linear kernel, and achieved a classification performance expressed as Matthews correlation coefficient of 0.36 and AUC of 0.81. Our method successfully addresses the problem of class imbalance in microbiome data for reliable prediction of smoking habits.
Keywords: class imbalance; data augmentation; human microbiome; machine learning; prediction modeling; saliva microbiome; smoking status; trait prediction.
Copyright © 2022 Díez López, Montiel González, Vidaki and Kayser.
Conflict of interest statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Figures
Similar articles
-
Joint modeling strategy for using electronic medical records data to build machine learning models: an example of intracerebral hemorrhage.BMC Med Inform Decis Mak. 2022 Oct 25;22(1):278. doi: 10.1186/s12911-022-02018-x. BMC Med Inform Decis Mak. 2022. PMID: 36284327 Free PMC article.
-
Solving the class imbalance problem using ensemble algorithm: application of screening for aortic dissection.BMC Med Inform Decis Mak. 2022 Mar 28;22(1):82. doi: 10.1186/s12911-022-01821-w. BMC Med Inform Decis Mak. 2022. PMID: 35346181 Free PMC article.
-
Combining handcrafted features with latent variables in machine learning for prediction of radiation-induced lung damage.Med Phys. 2019 May;46(5):2497-2511. doi: 10.1002/mp.13497. Epub 2019 Apr 8. Med Phys. 2019. PMID: 30891794 Free PMC article.
-
Combined In-silico and Machine Learning Approaches Toward Predicting Arrhythmic Risk in Post-infarction Patients.Front Physiol. 2021 Nov 8;12:745349. doi: 10.3389/fphys.2021.745349. eCollection 2021. Front Physiol. 2021. PMID: 34819872 Free PMC article.
-
Crash injury severity prediction considering data imbalance: A Wasserstein generative adversarial network with gradient penalty approach.Accid Anal Prev. 2023 Nov;192:107271. doi: 10.1016/j.aap.2023.107271. Epub 2023 Aug 31. Accid Anal Prev. 2023. PMID: 37659275
Cited by
-
Association of general health and lifestyle factors with the salivary microbiota - Lessons learned from the ADDITION-PRO cohort.Front Cell Infect Microbiol. 2022 Nov 16;12:1055117. doi: 10.3389/fcimb.2022.1055117. eCollection 2022. Front Cell Infect Microbiol. 2022. PMID: 36467723 Free PMC article.
References
-
- Abd Elrahman S. M., Abraham A. (2013). A review of class imbalance problem. J. Netw. 1, 332–340.
-
- Ali A., Shamsuddin S. M., Ralescu A. L. (2013). Classification with class imbalance problem. A review. Int. J. Advance Soft. Compu. Appl. 7, 176–204.
LinkOut - more resources
Full Text Sources