

Digital computing through randomness and order in neural networks
- PMID: 35947616
- PMCID: PMC9388095
- DOI: 10.1073/pnas.2115335119
Digital computing through randomness and order in neural networks
Abstract
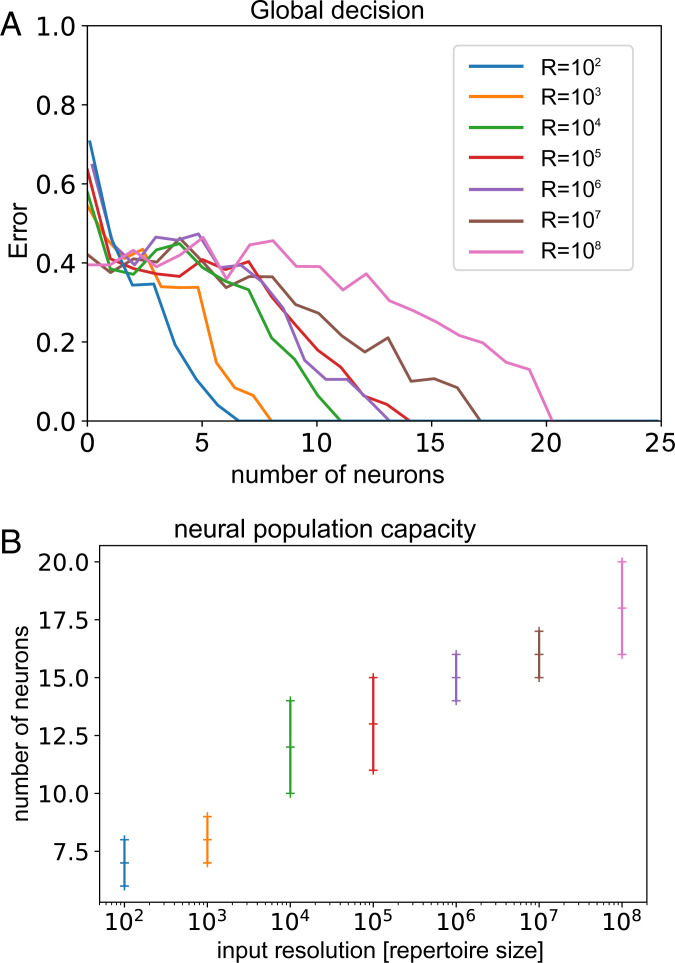
We propose that coding and decoding in the brain are achieved through digital computation using three principles: relative ordinal coding of inputs, random connections between neurons, and belief voting. Due to randomization and despite the coarseness of the relative codes, we show that these principles are sufficient for coding and decoding sequences with error-free reconstruction. In particular, the number of neurons needed grows linearly with the size of the input repertoire growing exponentially. We illustrate our model by reconstructing sequences with repertoires on the order of a billion items. From this, we derive the Shannon equations for the capacity limit to learn and transfer information in the neural population, which is then generalized to any type of neural network. Following the maximum entropy principle of efficient coding, we show that random connections serve to decorrelate redundant information in incoming signals, creating more compact codes for neurons and therefore, conveying a larger amount of information. Henceforth, despite the unreliability of the relative codes, few neurons become necessary to discriminate the original signal without error. Finally, we discuss the significance of this digital computation model regarding neurobiological findings in the brain and more generally with artificial intelligence algorithms, with a view toward a neural information theory and the design of digital neural networks.
Keywords: catastrophic forgetting; continual learning; digital computing; maximum entropy; sparse coding.
Conflict of interest statement
The authors declare no competing interest.
Figures








References
-
- Barlow H., “Possible principles underlying the transformation of sensory messages” in Sensory Communication, Rosenblith W., Ed. (MIT Press, Cambridge, MA, 1961), pp. 217–234.
-
- Baddeley R., Hancock P. J., Földiák P., Information Theory and the Brain (Cambridge University Press, Cambridge, United Kingdom, 2000).
-
- Olshausen B. A., Field D. J., Sparse coding of sensory inputs. Curr. Opin. Neurobiol. 14, 481–487 (2004). - PubMed
-
- Rolls E. T., Treves A., The neuronal encoding of information in the brain. Prog. Neurobiol. 95, 448–490 (2011). - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
