

Underlying neural mechanisms of degraded speech intelligibility following noise-induced hearing loss: The importance of distorted tonotopy
- PMID: 35953357
- PMCID: PMC11149709
- DOI: 10.1016/j.heares.2022.108586
Underlying neural mechanisms of degraded speech intelligibility following noise-induced hearing loss: The importance of distorted tonotopy
Abstract
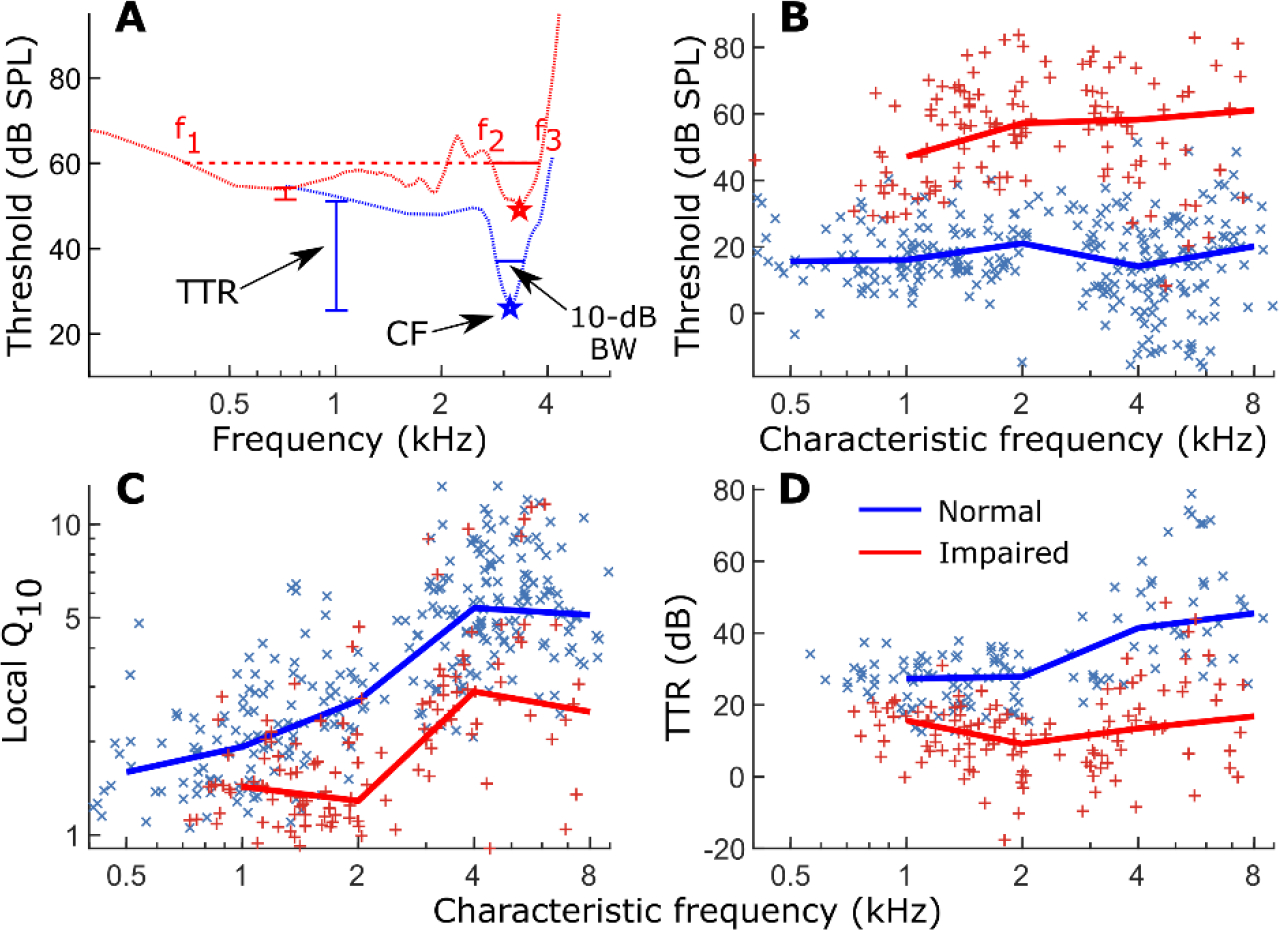
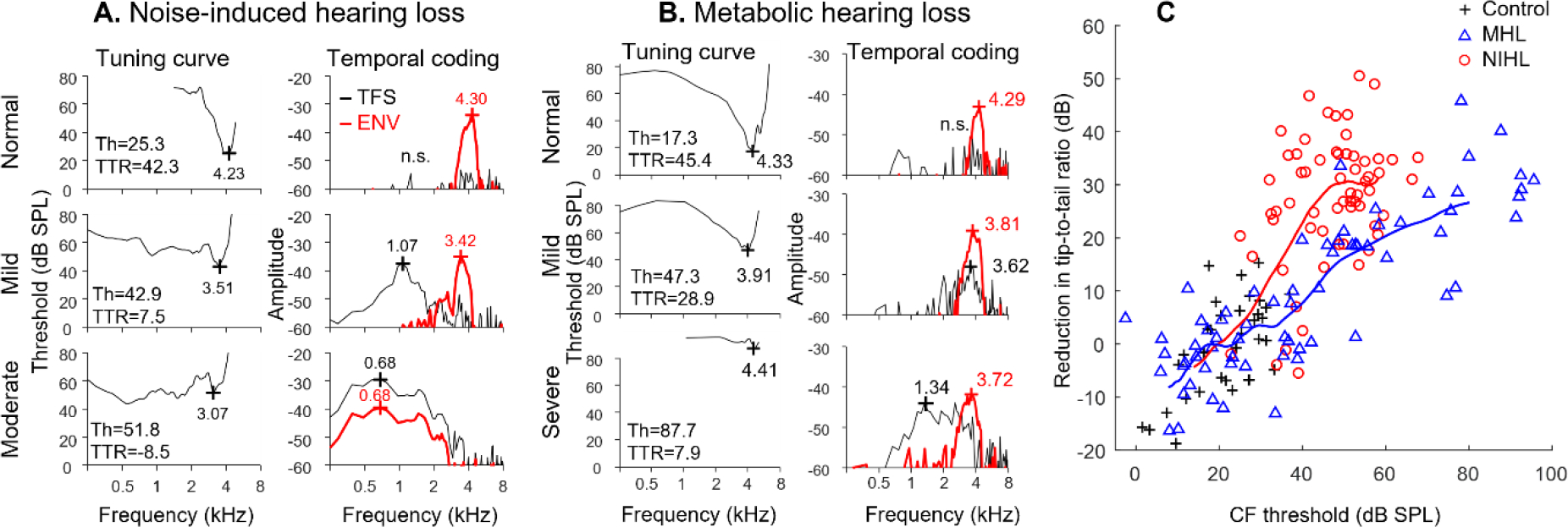
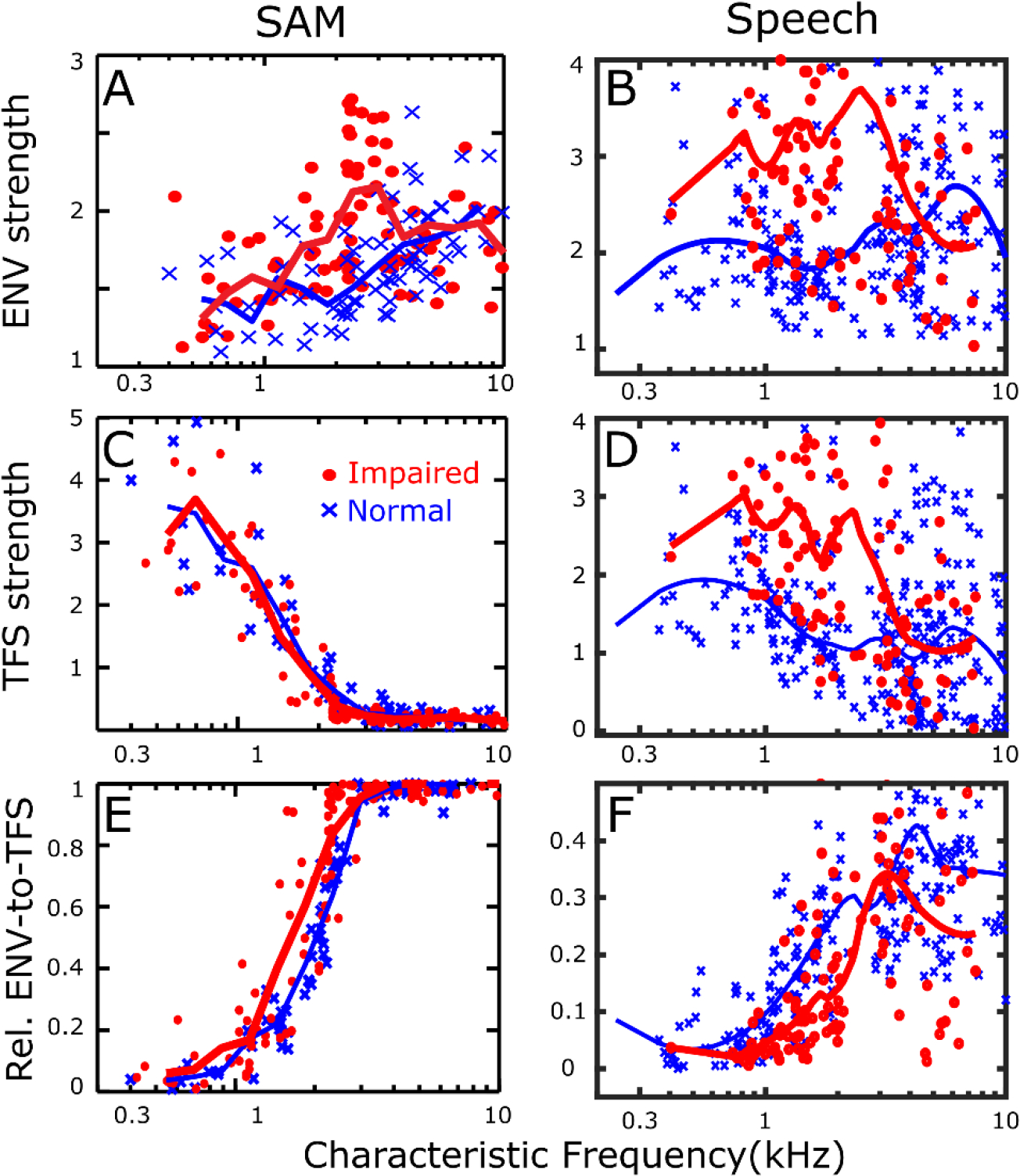
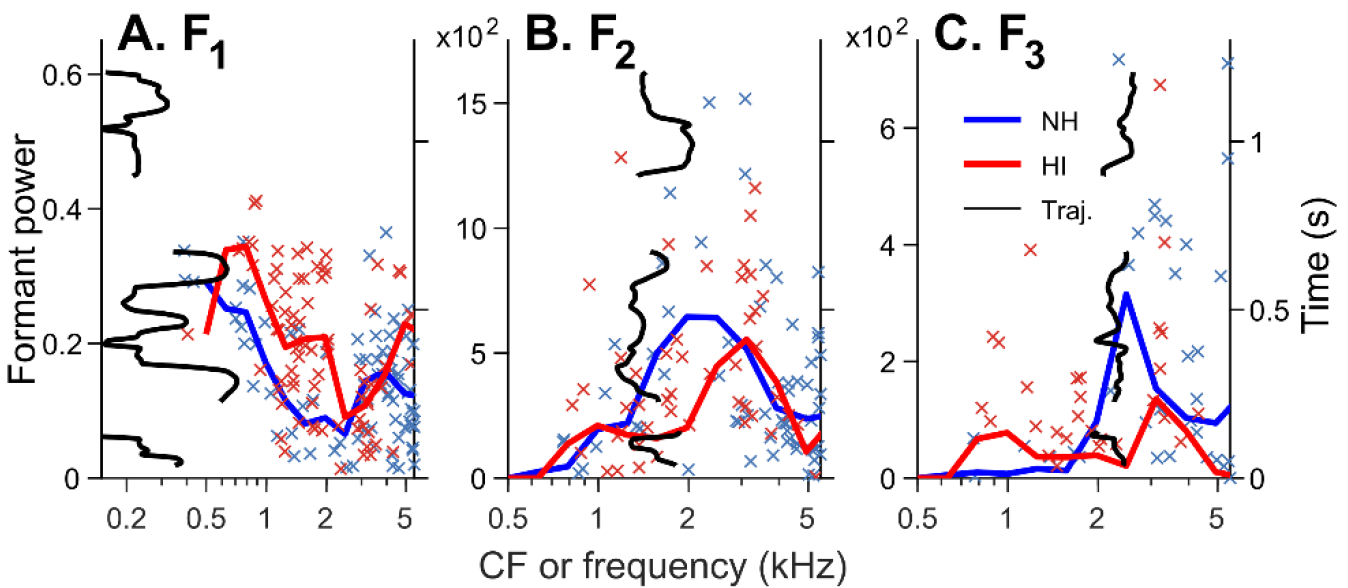
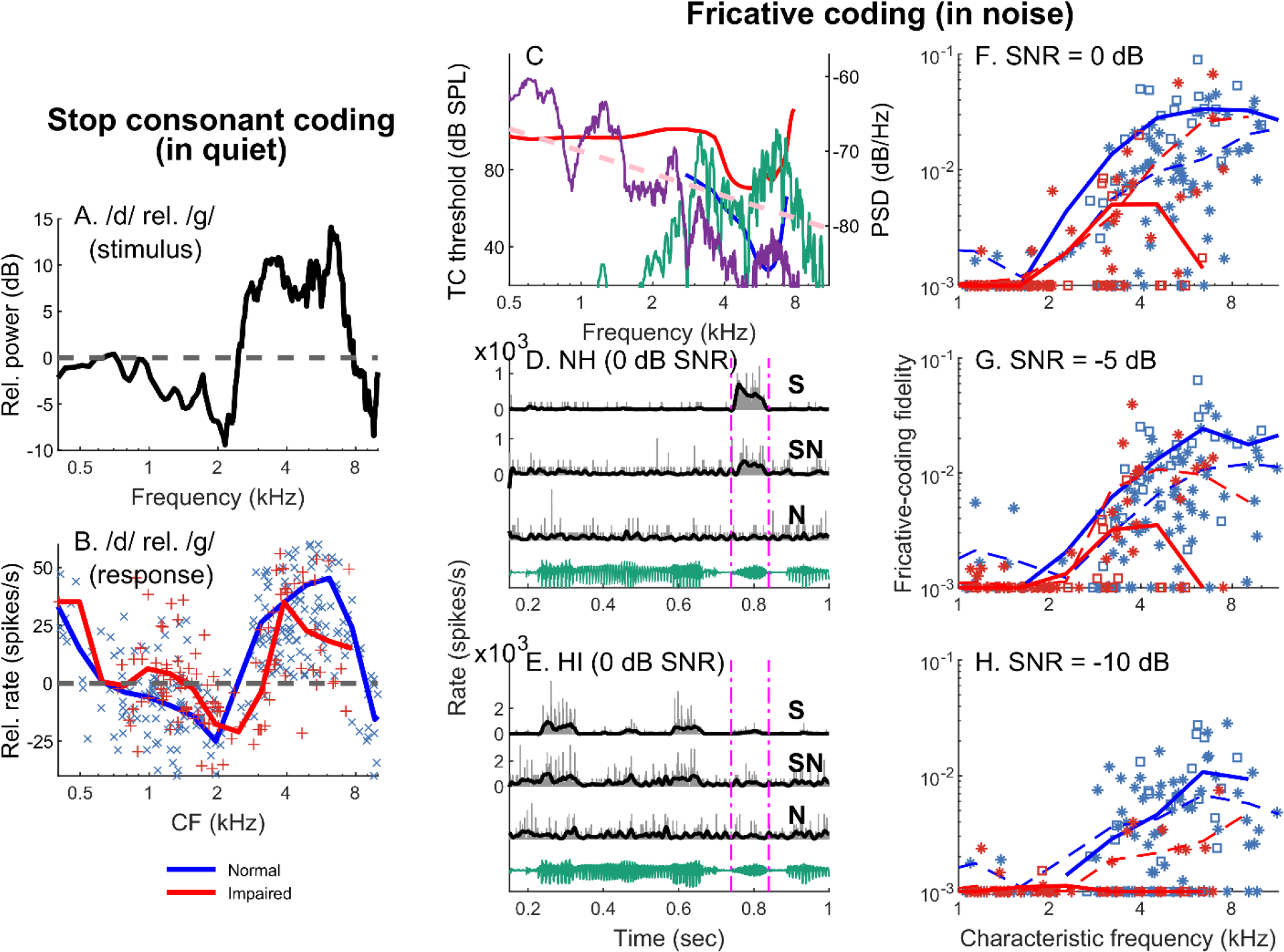
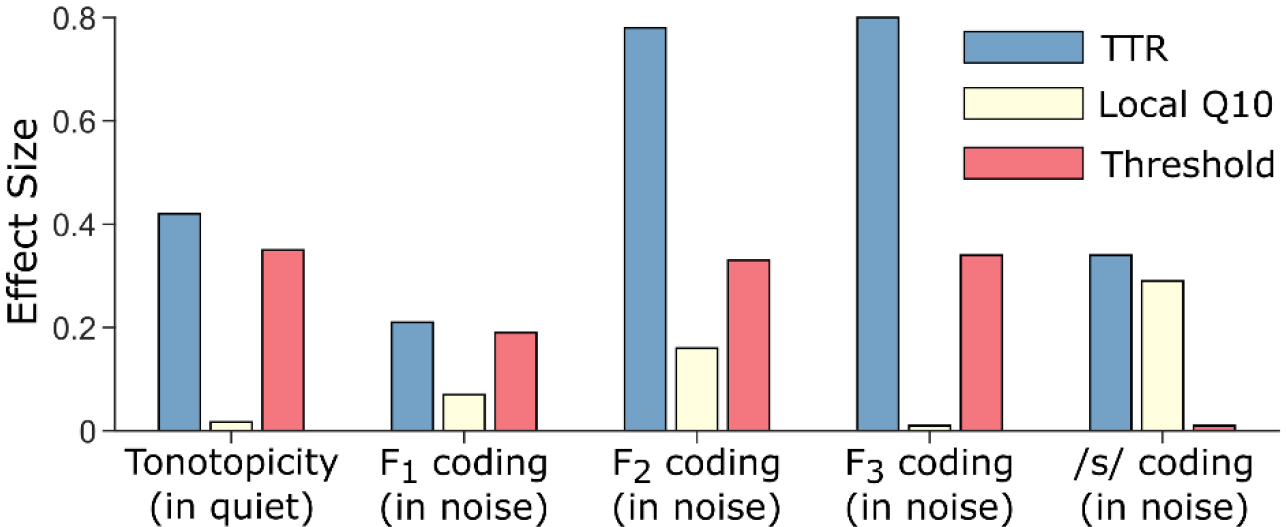
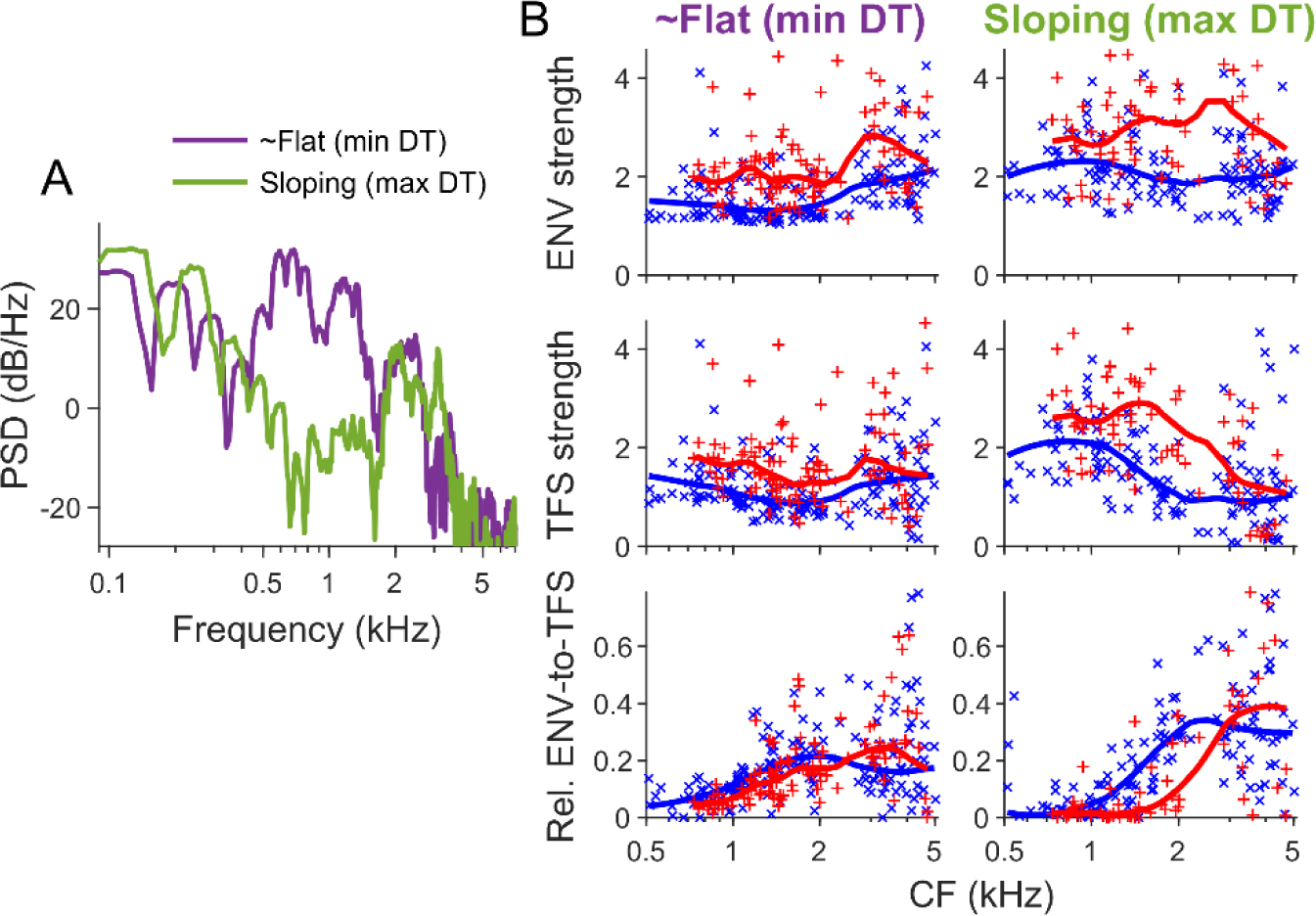
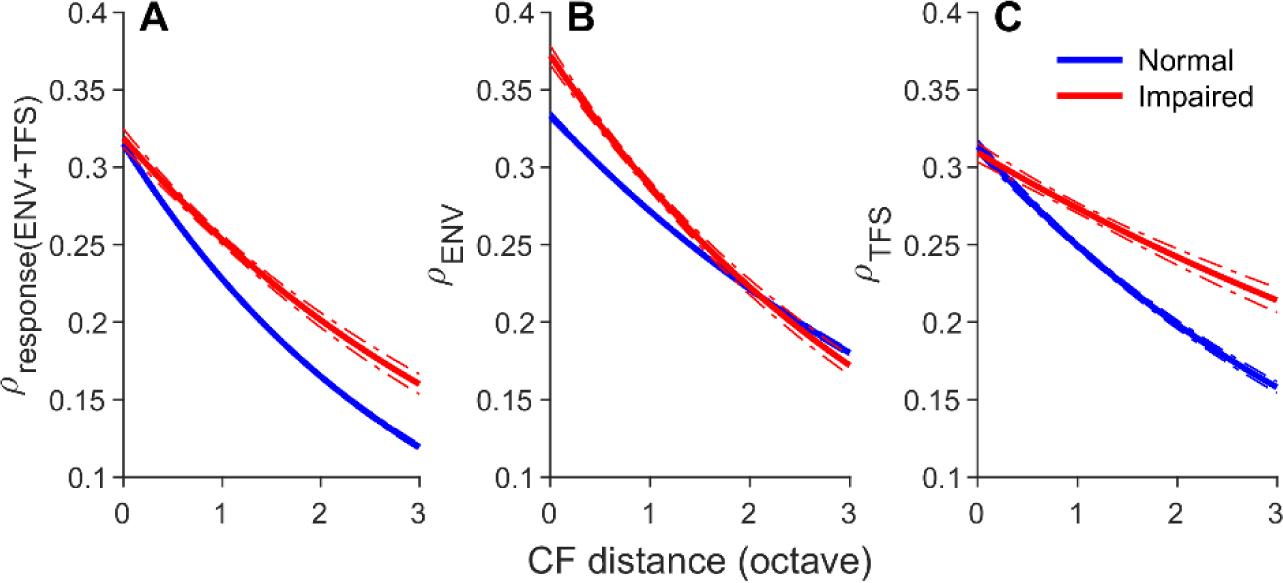
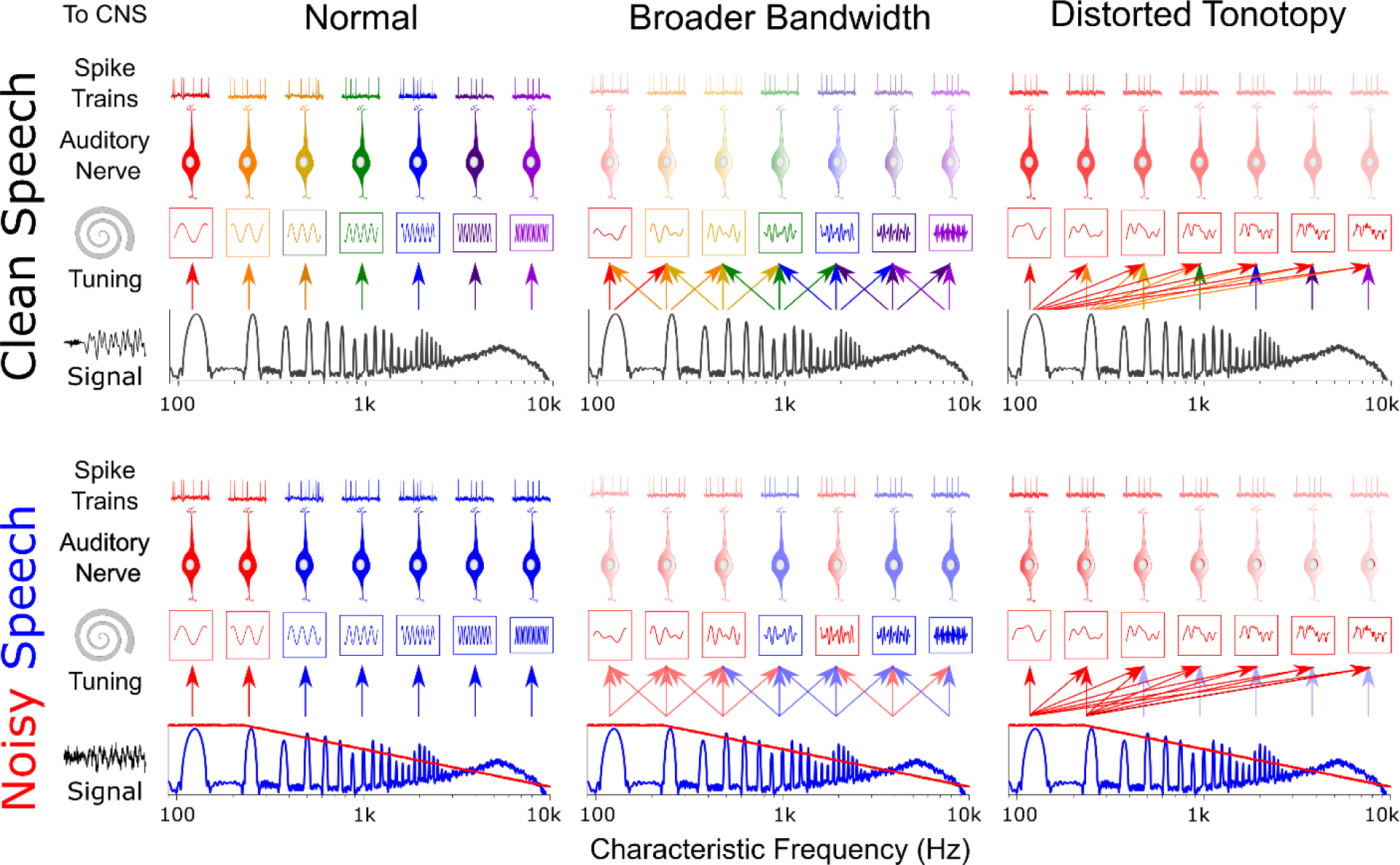
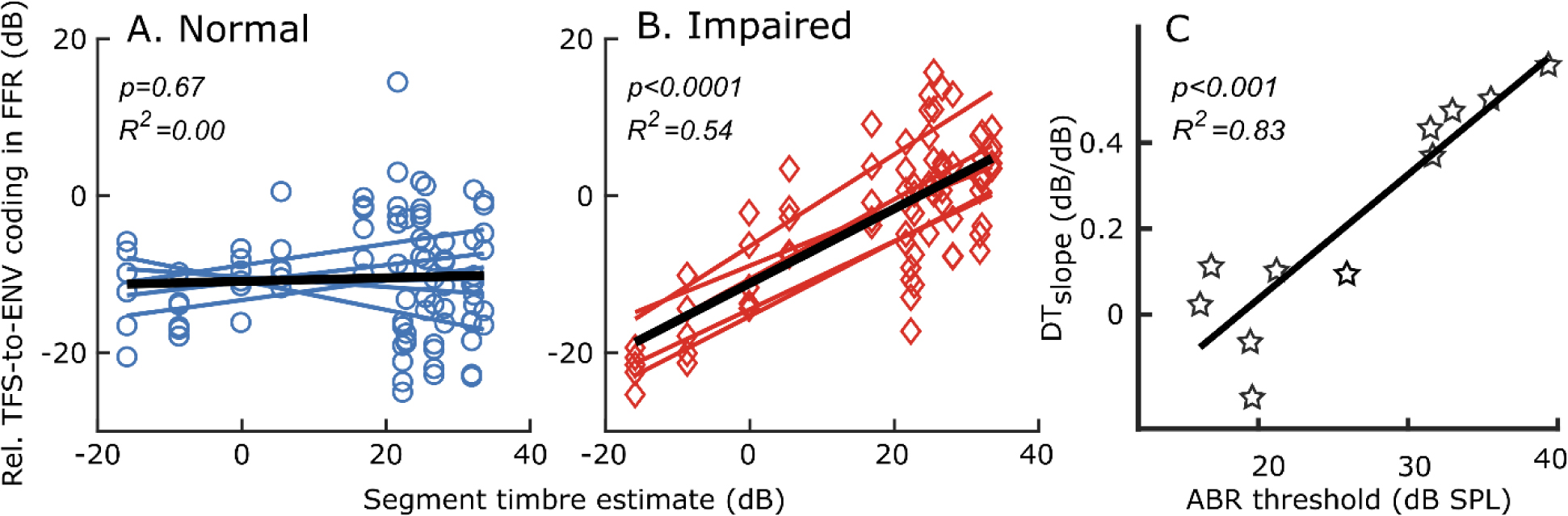
Listeners with sensorineural hearing loss (SNHL) have substantial perceptual deficits, especially in noisy environments. Unfortunately, speech-intelligibility models have limited success in predicting the performance of listeners with hearing loss. A better understanding of the various suprathreshold factors that contribute to neural-coding degradations of speech in noisy conditions will facilitate better modeling and clinical outcomes. Here, we highlight the importance of one physiological factor that has received minimal attention to date, termed distorted tonotopy, which refers to a disruption in the mapping between acoustic frequency and cochlear place that is a hallmark of normal hearing. More so than commonly assumed factors (e.g., threshold elevation, reduced frequency selectivity, diminished temporal coding), distorted tonotopy severely degrades the neural representations of speech (particularly in noise) in single- and across-fiber responses in the auditory nerve following noise-induced hearing loss. Key results include: 1) effects of distorted tonotopy depend on stimulus spectral bandwidth and timbre, 2) distorted tonotopy increases across-fiber correlation and thus reduces information capacity to the brain, and 3) its effects vary across etiologies, which may contribute to individual differences. These results motivate the development and testing of noninvasive measures that can assess the severity of distorted tonotopy in human listeners. The development of such noninvasive measures of distorted tonotopy would advance precision-audiological approaches to improving diagnostics and rehabilitation for listeners with SNHL.
Keywords: Auditory nerve; Distorted tonotopy; Hearing loss; Speech coding; Speech intelligibility; Temporal coding.
Copyright © 2022. Published by Elsevier B.V.
Conflict of interest statement
Declaration of Competing Interest The authors declare no competing interests.
Figures
References
-
- Bharadwaj HM, Verhulst S, Shaheen L, Liberman MC, Shinn-Cunningham BG, 2014. Cochlear neuropathy and the coding of supra-threshold sound. Front. Syst. Neurosci. 8. 10.3389/fnsys.2014.00026 - DOI
-
- Bruce IC, Zilany MSA, 2007. Modelling the effects of cochlear impairment on the neural representation of speech in the auditory nerve and primary auditory cortex. Proceedings of the International Symposium on Auditory and Audiological Research 1, 1–10.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
