

ntHash2: recursive spaced seed hashing for nucleotide sequences
- PMID: 36000872
- PMCID: PMC9563681
- DOI: 10.1093/bioinformatics/btac564
ntHash2: recursive spaced seed hashing for nucleotide sequences
Abstract
Motivation: Spaced seeds are robust alternatives to k-mers in analyzing nucleotide sequences with high base mismatch rates. Hashing is also crucial for efficiently storing abundant sequence data. Here, we introduce ntHash2, a fast algorithm for spaced seed hashing that can be integrated into various bioinformatics tools for efficient sequence analysis with applications in genome research.
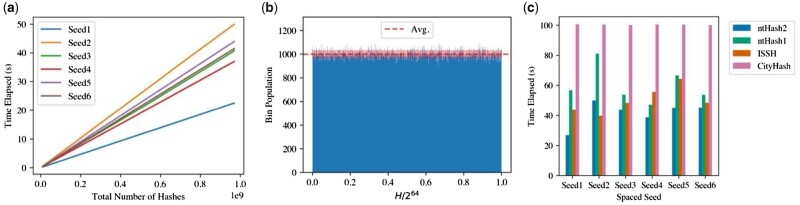
Results: ntHash2 is up to 2.1× faster at hashing various spaced seeds than the previous version and 3.8× faster than conventional hashing algorithms with naïve adaptation. Additionally, we reduced the collision rate of ntHash for longer k-mer lengths and improved the uniformity of the hash distribution by modifying the canonical hashing mechanism.
Availability and implementation: ntHash2 is freely available online at github.com/bcgsc/ntHash under an MIT license.
Supplementary information: Supplementary data are available at Bioinformatics online.
© The Author(s) 2022. Published by Oxford University Press.
Figures
References
-
- Chakravarti I.M. et al. (1967) Handbook of Methods of Applied Statistics. Vol. 1. John Wiley and Sons, New York, pp. 392–394.
-
- Ma B. et al. (2002) PatternHunter: faster and more sensitive homology search. Bioinformatics, 18, 440–445. - PubMed
-
- Petrucci E. et al. (2020) Iterative spaced seed hashing: closing the gap between spaced seed hashing and k-mer Hashing. J. Comput. Biol., 27, 223–233. - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Miscellaneous
