

Robust Effects of Working Memory Demand during Naturalistic Language Comprehension in Language-Selective Cortex
- PMID: 36002263
- PMCID: PMC9525168
- DOI: 10.1523/JNEUROSCI.1894-21.2022
Robust Effects of Working Memory Demand during Naturalistic Language Comprehension in Language-Selective Cortex
Abstract
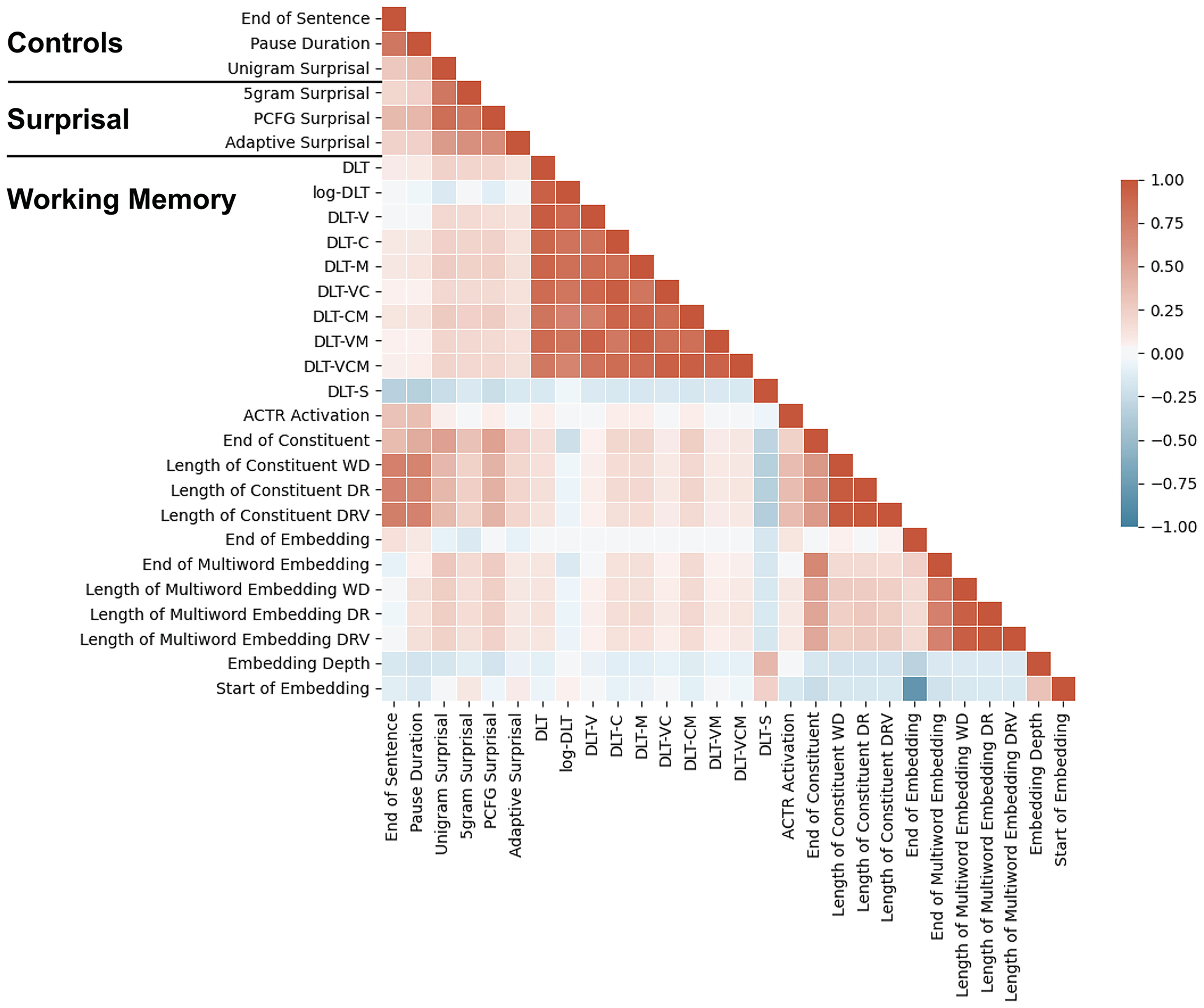
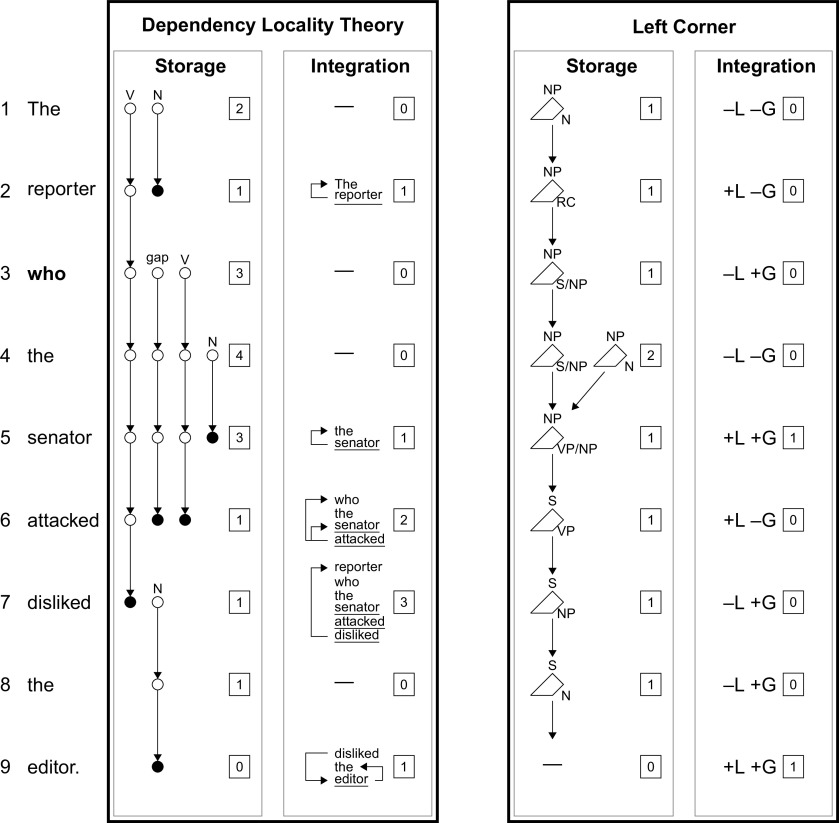
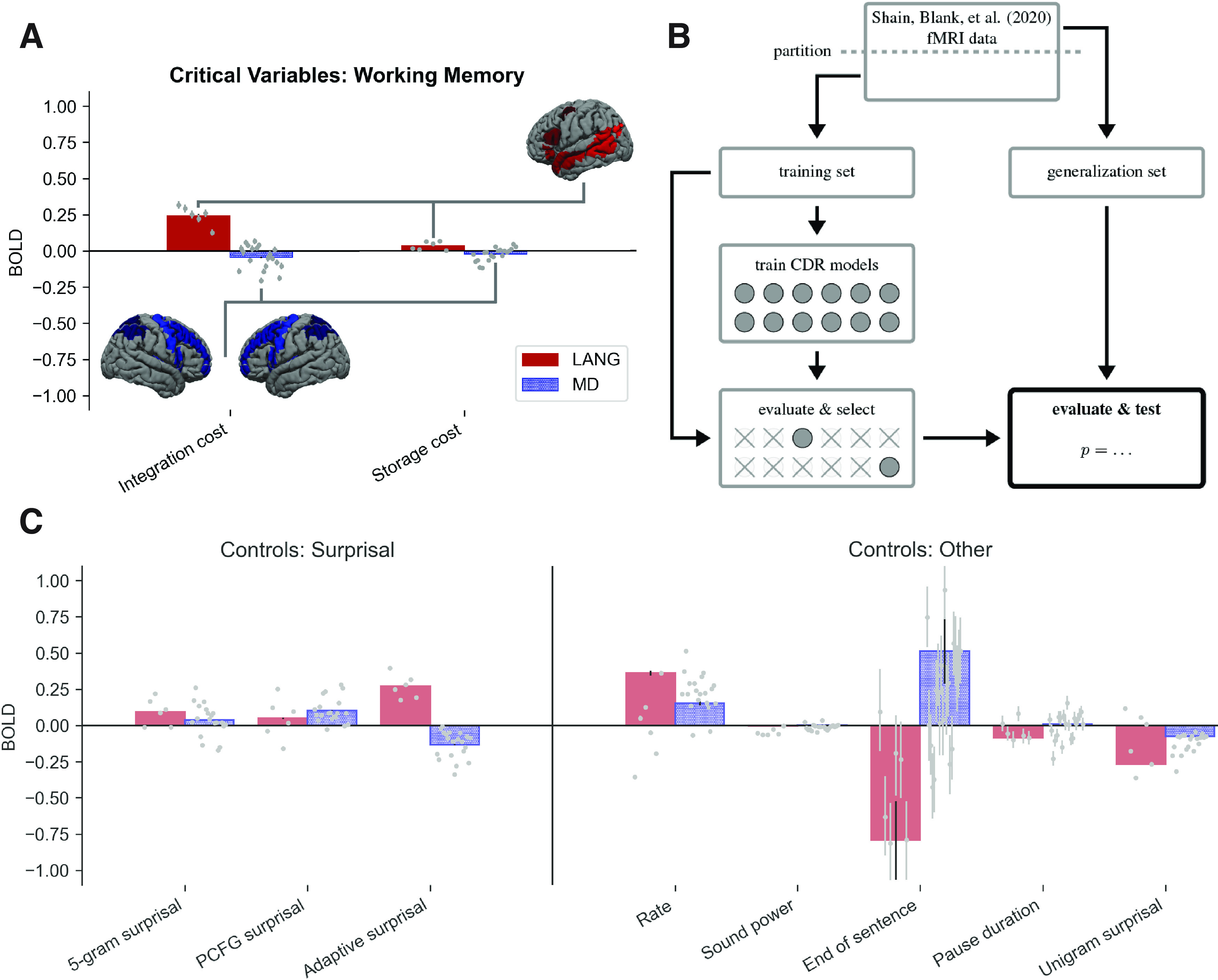
To understand language, we must infer structured meanings from real-time auditory or visual signals. Researchers have long focused on word-by-word structure building in working memory as a mechanism that might enable this feat. However, some have argued that language processing does not typically involve rich word-by-word structure building, and/or that apparent working memory effects are underlyingly driven by surprisal (how predictable a word is in context). Consistent with this alternative, some recent behavioral studies of naturalistic language processing that control for surprisal have not shown clear working memory effects. In this fMRI study, we investigate a range of theory-driven predictors of word-by-word working memory demand during naturalistic language comprehension in humans of both sexes under rigorous surprisal controls. In addition, we address a related debate about whether the working memory mechanisms involved in language comprehension are language specialized or domain general. To do so, in each participant, we functionally localize (1) the language-selective network and (2) the "multiple-demand" network, which supports working memory across domains. Results show robust surprisal-independent effects of memory demand in the language network and no effect of memory demand in the multiple-demand network. Our findings thus support the view that language comprehension involves computationally demanding word-by-word structure building operations in working memory, in addition to any prediction-related mechanisms. Further, these memory operations appear to be primarily conducted by the same neural resources that store linguistic knowledge, with no evidence of involvement of brain regions known to support working memory across domains.SIGNIFICANCE STATEMENT This study uses fMRI to investigate signatures of working memory (WM) demand during naturalistic story listening, using a broad range of theoretically motivated estimates of WM demand. Results support a strong effect of WM demand in the brain that is distinct from effects of word predictability. Further, these WM demands register primarily in language-selective regions, rather than in "multiple-demand" regions that have previously been associated with WM in nonlinguistic domains. Our findings support a core role for WM in incremental language processing, using WM resources that are specialized for language.
Keywords: domain specificity; fMRI; naturalistic; sentence processing; surprisal; working memory.
Copyright © 2022 the authors.
Figures
References
-
- Armeni K, Willems RM, den Bosch A, Schoffelen J-M (2019) Frequency-specific brain dynamics related to prediction during language comprehension. Neuroimage 198:283–295. - PubMed
-
- Aurnhammer C, Frank SL (2019) Evaluating information-theoretic measures of word prediction in naturalistic sentence reading. Neuropsychologia 134:107198. - PubMed