

Brain-phenotype models fail for individuals who defy sample stereotypes
- PMID: 36002572
- PMCID: PMC9433326
- DOI: 10.1038/s41586-022-05118-w
Brain-phenotype models fail for individuals who defy sample stereotypes
Abstract
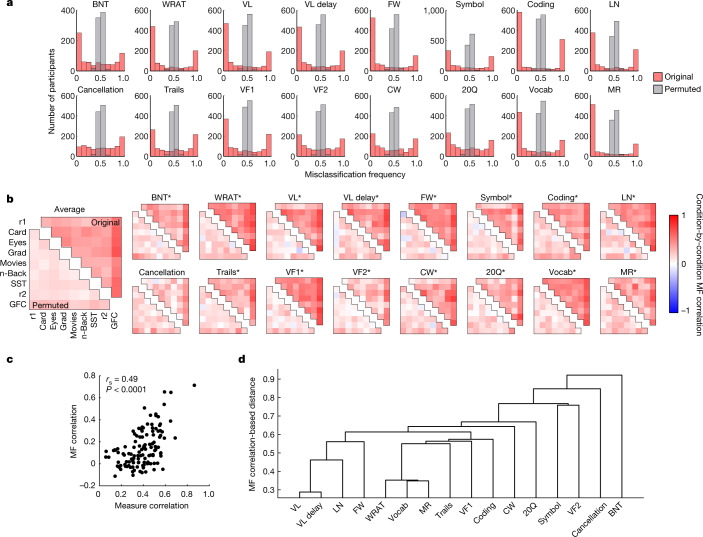
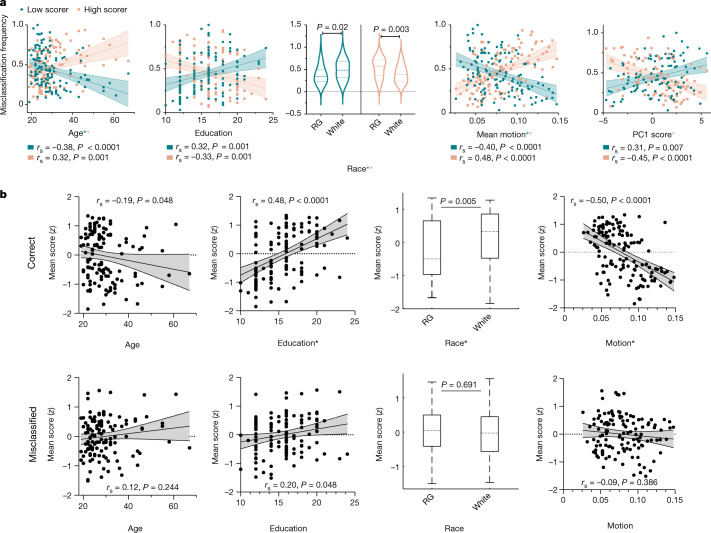
Individual differences in brain functional organization track a range of traits, symptoms and behaviours1-12. So far, work modelling linear brain-phenotype relationships has assumed that a single such relationship generalizes across all individuals, but models do not work equally well in all participants13,14. A better understanding of in whom models fail and why is crucial to revealing robust, useful and unbiased brain-phenotype relationships. To this end, here we related brain activity to phenotype using predictive models-trained and tested on independent data to ensure generalizability15-and examined model failure. We applied this data-driven approach to a range of neurocognitive measures in a new, clinically and demographically heterogeneous dataset, with the results replicated in two independent, publicly available datasets16,17. Across all three datasets, we find that models reflect not unitary cognitive constructs, but rather neurocognitive scores intertwined with sociodemographic and clinical covariates; that is, models reflect stereotypical profiles, and fail when applied to individuals who defy them. Model failure is reliable, phenotype specific and generalizable across datasets. Together, these results highlight the pitfalls of a one-size-fits-all modelling approach and the effect of biased phenotypic measures18-20 on the interpretation and utility of resulting brain-phenotype models. We present a framework to address these issues so that such models may reveal the neural circuits that underlie specific phenotypes and ultimately identify individualized neural targets for clinical intervention.
© 2022. The Author(s).
Conflict of interest statement
In the past two years, G.S. has served as a consultant or scientific advisory board member to Axsome Therapeutics, Biogen, Biohaven Pharmaceuticals, Boehringer Ingelheim International, Bristol-Myers Squibb, Clexio, Cowen, Denovo Biopharma, ECR1, EMA Wellness, Engrail Therapeutics, Gilgamesh, Janssen, Levo, Lundbeck, Merck, Navitor Pharmaceuticals, Neurocrine, Novartis, Noven Pharmaceuticals, Perception Neuroscience, Praxis Therapeutics, Sage Pharmaceuticals, Seelos Pharmaceuticals, Vistagen Therapeutics and XW Labs; and received research contracts from Johnson & Johnson (Janssen), Merck and Usona. G.S. holds equity in Biohaven Pharmaceuticals and is a co-inventor on a US patent (8,778,979) held by Yale University and a co-inventor on US provisional patent application no. 047162-7177P1 (00754), filed on 20 August 2018 by Yale University Office of Cooperative Research. Yale University has a financial relationship with Janssen Pharmaceuticals and may receive financial benefits from this relationship. The University has put multiple measures in place to mitigate this institutional conflict of interest. Questions about the details of these measures should be directed to Yale University’s Conflict of Interest office. V.H.S. has served as a scientific advisory board member to Takeda and Janssen. The remaining authors declare no competing interests.
Figures









Similar articles
-
Right care, first time: a highly personalised and measurement-based care model to manage youth mental health.Med J Aust. 2019 Nov;211 Suppl 9:S3-S46. doi: 10.5694/mja2.50383. Med J Aust. 2019. PMID: 31679171
-
Joint prediction of multiple scores captures better individual traits from brain images.Neuroimage. 2017 Sep;158:145-154. doi: 10.1016/j.neuroimage.2017.06.072. Epub 2017 Jul 1. Neuroimage. 2017. PMID: 28676298
-
The future of Cochrane Neonatal.Early Hum Dev. 2020 Nov;150:105191. doi: 10.1016/j.earlhumdev.2020.105191. Epub 2020 Sep 12. Early Hum Dev. 2020. PMID: 33036834
-
A developmental intergroup theory of social stereotypes and prejudice.Adv Child Dev Behav. 2006;34:39-89. doi: 10.1016/s0065-2407(06)80004-2. Adv Child Dev Behav. 2006. PMID: 17120802 Review.
-
Clinical Promise of Brain-Phenotype Modeling: A Review.JAMA Psychiatry. 2023 Aug 1;80(8):848-854. doi: 10.1001/jamapsychiatry.2023.1419. JAMA Psychiatry. 2023. PMID: 37314790 Review.
Cited by
-
Editorial: Insights in Alzheimer's disease and related dementias.Front Aging Neurosci. 2022 Nov 23;14:1068156. doi: 10.3389/fnagi.2022.1068156. eCollection 2022. Front Aging Neurosci. 2022. PMID: 36506469 Free PMC article. No abstract available.
-
Connectome-based machine learning models are vulnerable to subtle data manipulations.Patterns (N Y). 2023 May 15;4(7):100756. doi: 10.1016/j.patter.2023.100756. eCollection 2023 Jul 14. Patterns (N Y). 2023. PMID: 37521052 Free PMC article.
-
Latin American brain-health research requires regional data and tailored models.Nat Aging. 2024 Aug;4(8):1041-1042. doi: 10.1038/s43587-024-00656-6. Nat Aging. 2024. PMID: 38890536 No abstract available.
-
The Transition From Homogeneous to Heterogeneous Machine Learning in Neuropsychiatric Research.Biol Psychiatry Glob Open Sci. 2024 Sep 26;5(1):100397. doi: 10.1016/j.bpsgos.2024.100397. eCollection 2025 Jan. Biol Psychiatry Glob Open Sci. 2024. PMID: 39526023 Free PMC article. Review.
-
Viscous dynamics associated with hypoexcitation and structural disintegration in neurodegeneration via generative whole-brain modeling.Alzheimers Dement. 2024 May;20(5):3228-3250. doi: 10.1002/alz.13788. Epub 2024 Mar 19. Alzheimers Dement. 2024. PMID: 38501336 Free PMC article.
References
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
