

Opportunities and Challenges of Data-Driven Virus Discovery
- PMID: 36008967
- PMCID: PMC9406072
- DOI: 10.3390/biom12081073
Opportunities and Challenges of Data-Driven Virus Discovery
Abstract
Virus discovery has been fueled by new technologies ever since the first viruses were discovered at the end of the 19th century. Starting with mechanical devices that provided evidence for virus presence in sick hosts, virus discovery gradually transitioned into a sequence-based scientific discipline, which, nowadays, can characterize virus identity and explore viral diversity at an unprecedented resolution and depth. Sequencing technologies are now being used routinely and at ever-increasing scales, producing an avalanche of novel viral sequences found in a multitude of organisms and environments. In this perspective article, we argue that virus discovery has started to undergo another transformation prompted by the emergence of new approaches that are sequence data-centered and primarily computational, setting them apart from previous technology-driven innovations. The data-driven virus discovery approach is largely uncoupled from the collection and processing of biological samples, and exploits the availability of massive amounts of publicly and freely accessible data from sequencing archives. We discuss open challenges to be solved in order to unlock the full potential of data-driven virus discovery, and we highlight the benefits it can bring to classical (mostly molecular) virology and molecular biology in general.
Keywords: computational virology; data mining; sequencing archives; virosphere in health and disease; virus discovery.
Conflict of interest statement
The authors declare no conflict of interest.
Figures
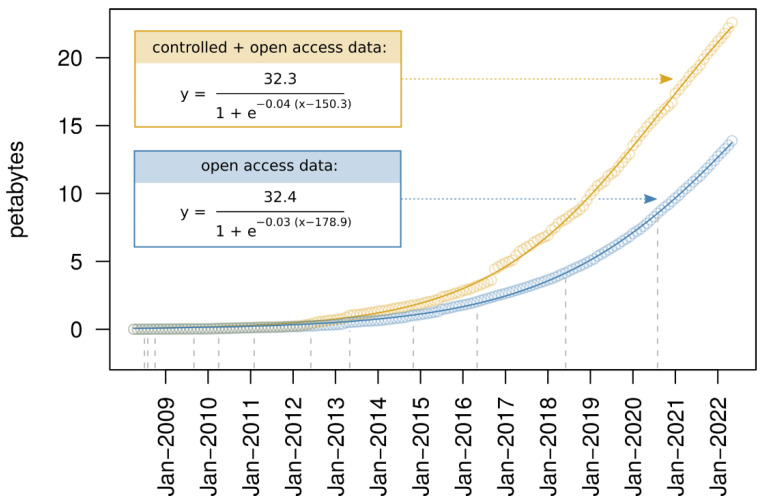
References
-
- Ivanovsky D. Über Die Mosaikkrankheit Der Tabakspflanze. Bull. Acad. Imper. Sci. St. Petersburg. 1892;35:67–70.
-
- Beijerinck M.W. Über Ein Contagium Vivum Fluidum Als Ursache Der Fleckenkrankheit Der Tabaksblätter. Verh Kon Akad Wetensch. 1898;65:3–21.
-
- Chamberland C. A Filter Permitting to Obtain Physiologically Pure Water. Compt. Rend. Acad. Sci. 1884;99:247–248.
-
- Löffler F., Frosch P. Summarischer Bericht Über Die Ergebnisse Der Untersuchungen Der Commission Zur Erforschung Der Maul-Und Klauenseuche. Cent. Bakt. Parasit. 1898;23:371–391.
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
