

An Efficient Ensemble Deep Learning Approach for Semantic Point Cloud Segmentation Based on 3D Geometric Features and Range Images
- PMID: 36015964
- PMCID: PMC9416655
- DOI: 10.3390/s22166210
An Efficient Ensemble Deep Learning Approach for Semantic Point Cloud Segmentation Based on 3D Geometric Features and Range Images
Abstract
Mobile light detection and ranging (LiDAR) sensor point clouds are used in many fields such as road network management, architecture and urban planning, and 3D High Definition (HD) city maps for autonomous vehicles. Semantic segmentation of mobile point clouds is critical for these tasks. In this study, we present a robust and effective deep learning-based point cloud semantic segmentation method. Semantic segmentation is applied to range images produced from point cloud with spherical projection. Irregular 3D mobile point clouds are transformed into regular form by projecting the clouds onto the plane to generate 2D representation of the point cloud. This representation is fed to the proposed network that produces semantic segmentation. The local geometric feature vector is calculated for each point. Optimum parameter experiments were also performed to obtain the best results for semantic segmentation. The proposed technique, called SegUNet3D, is an ensemble approach based on the combination of U-Net and SegNet algorithms. SegUNet3D algorithm has been compared with five different segmentation algorithms on two challenging datasets. SemanticPOSS dataset includes the urban area, whereas RELLIS-3D includes the off-road environment. As a result of the study, it was demonstrated that the proposed approach is superior to other methods in terms of mean Intersection over Union (mIoU) in both datasets. The proposed method was able to improve the mIoU metric by up to 15.9% in the SemanticPOSS dataset and up to 5.4% in the RELLIS-3D dataset.
Keywords: autonomous driving; deep learning; light detection and ranging (LiDAR); point cloud; semantic segmentation.
Conflict of interest statement
The authors declare no conflict of interest.
Figures





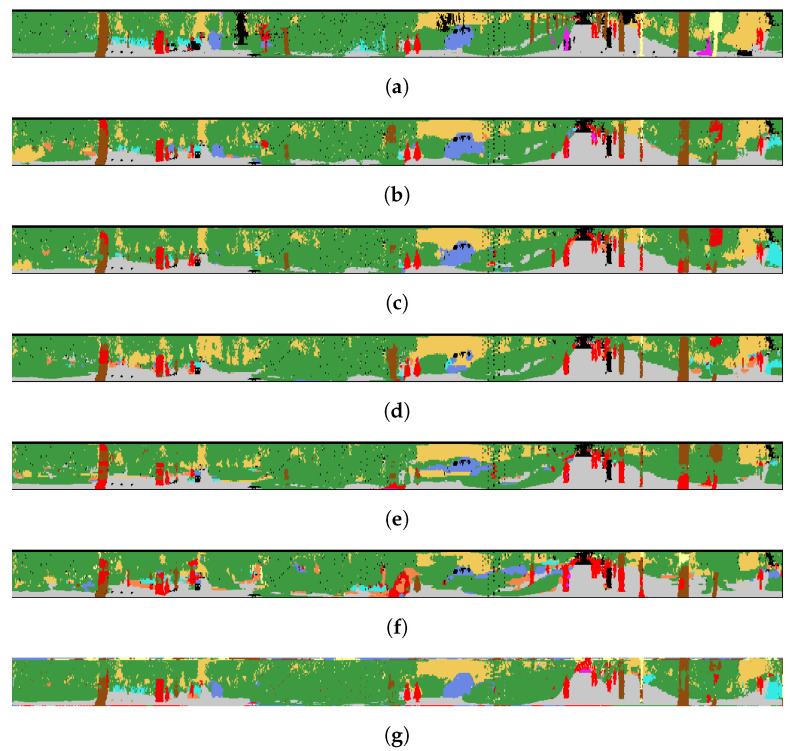


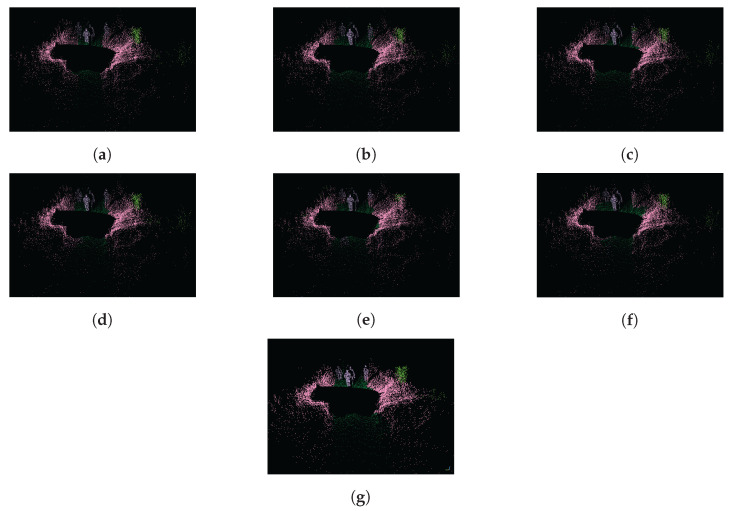
References
-
- Wu B., Zhou X., Zhao S., Yue X., Keutzer K. SqueezeSegV2: Improved model structure and unsupervised domain adaptation for road-object segmentation from a LiDAR point cloud; Proceedings of the 2019 International Conference on Robotics and Automation (ICRA); Montreal, QC, Canada. 20–24 May 2019; - DOI
-
- Biasutti P., Lepetit V., Aujol J.F., Bredif M., Bugeau A. LU-net: An efficient network for 3D LiDAR point cloud semantic segmentation based on end-to-end-learned 3D features and U-net; Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops; Seoul, Korea. 27–28 October 2019; - DOI
-
- Nagy B., Benedek C. 3D CNN-based semantic labeling approach for mobile laser scanning data. IEEE Sens. J. 2019;19:10034–10045. doi: 10.1109/JSEN.2019.2927269. - DOI
Grants and funding
LinkOut - more resources
Full Text Sources
Research Materials
