

GeneralizedDTA: combining pre-training and multi-task learning to predict drug-target binding affinity for unknown drug discovery
- PMID: 36071406
- PMCID: PMC9449940
- DOI: 10.1186/s12859-022-04905-6
GeneralizedDTA: combining pre-training and multi-task learning to predict drug-target binding affinity for unknown drug discovery
Abstract
Background: Accurately predicting drug-target binding affinity (DTA) in silico plays an important role in drug discovery. Most of the computational methods developed for predicting DTA use machine learning models, especially deep neural networks, and depend on large-scale labelled data. However, it is difficult to learn enough feature representation from tens of millions of compounds and hundreds of thousands of proteins only based on relatively limited labelled drug-target data. There are a large number of unknown drugs, which never appear in the labelled drug-target data. This is a kind of out-of-distribution problems in bio-medicine. Some recent studies adopted self-supervised pre-training tasks to learn structural information of amino acid sequences for enhancing the feature representation of proteins. However, the task gap between pre-training and DTA prediction brings the catastrophic forgetting problem, which hinders the full application of feature representation in DTA prediction and seriously affects the generalization capability of models for unknown drug discovery.
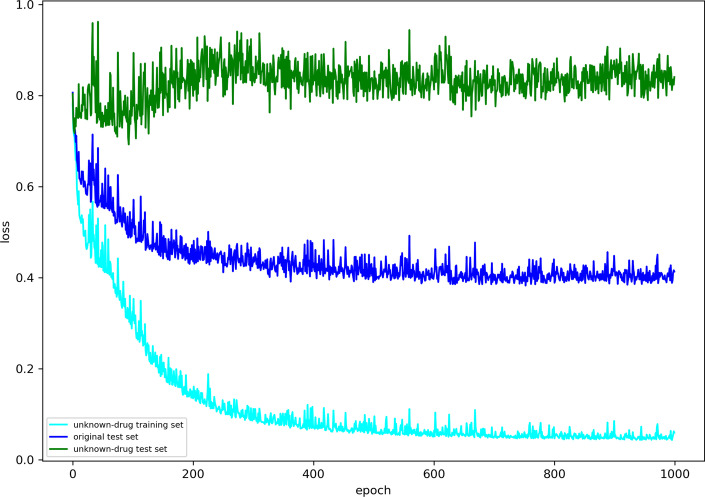
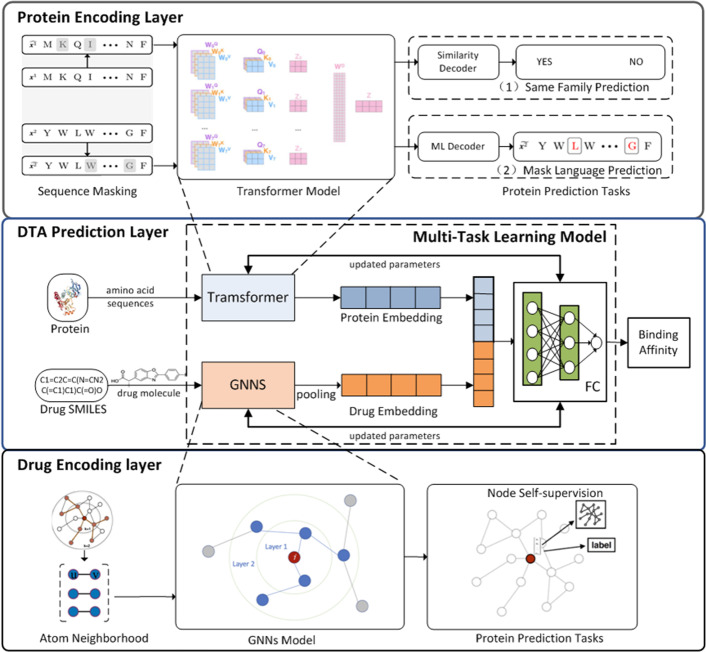
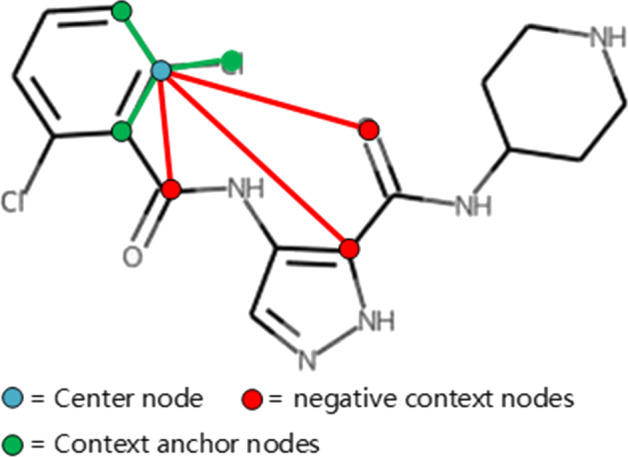
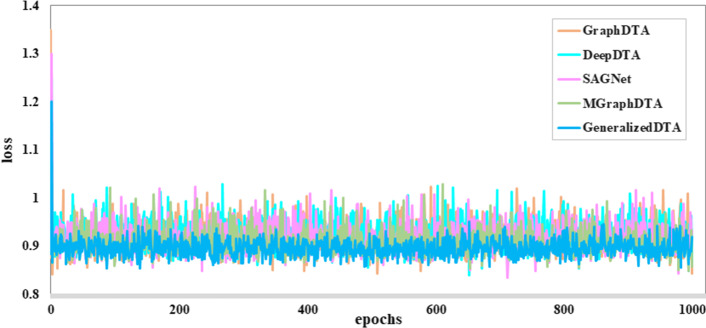
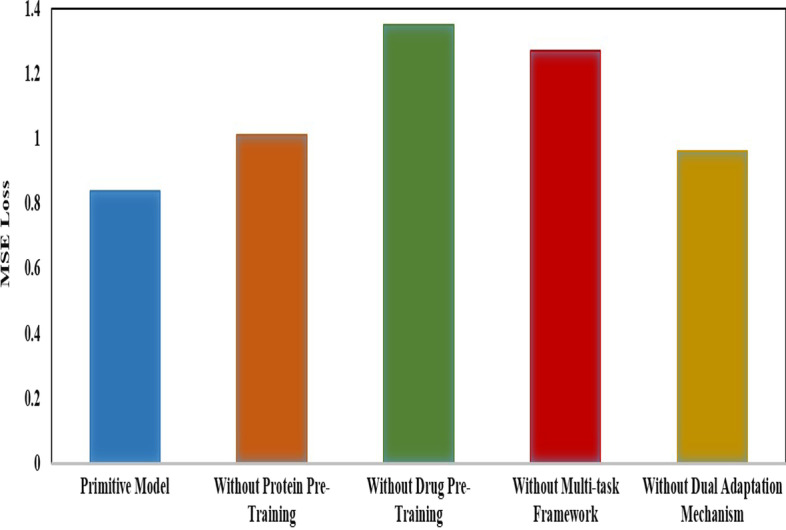
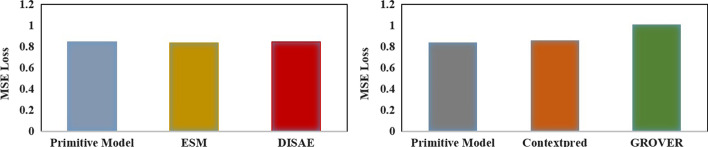
Results: To address these problems, we propose the GeneralizedDTA, which is a new DTA prediction model oriented to unknown drug discovery, by combining pre-training and multi-task learning. We introduce self-supervised protein and drug pre-training tasks to learn richer structural information from amino acid sequences of proteins and molecular graphs of drug compounds, in order to alleviate the problem of high variance caused by encoding based on deep neural networks and accelerate the convergence of prediction model on small-scale labelled data. We also develop a multi-task learning framework with a dual adaptation mechanism to narrow the task gap between pre-training and prediction for preventing overfitting and improving the generalization capability of DTA prediction model on unknown drug discovery. To validate the effectiveness of our model, we construct an unknown drug data set to simulate the scenario of unknown drug discovery. Compared with existing DTA prediction models, the experimental results show that our model has the higher generalization capability in the DTA prediction of unknown drugs.
Conclusions: The advantages of our model are mainly attributed to two kinds of pre-training tasks and the multi-task learning framework, which can learn richer structural information of proteins and drugs from large-scale unlabeled data, and then effectively integrate it into the downstream prediction task for obtaining a high-quality DTA prediction in unknown drug discovery.
Keywords: DTA prediction; Dual adaptation mechanism; Multi-task learning; Pre-training task.
© 2022. The Author(s).
Conflict of interest statement
The authors declare that they have no competing interests.
Figures
References
-
- Ezzat A, Wu M, Li X-L, Kwoh C-K. Computational prediction of drug-target interactions using chemogenomic approaches: an empirical survey. Brief Bioinform. 2018;20:1337–1357. - PubMed
-
- Mullard A. New drugs cost us \$2.6 billion to develop. Nat Rev Drug Discov. 2014;13(12):877.
-
- Mongia A, Jain V, Chouzenoux E, Majumdar A. Deep latent factor model for predicting drug target interactions. 2019. p. 1254–1258.
MeSH terms
Substances
Grants and funding
- 2020YFB2104402/National Key Research and Development Program of China
- 2020YFB2104402/National Key Research and Development Program of China
- 2020YFB2104402/National Key Research and Development Program of China
- 4222022/Beijing Municipal Natural Science Foundation
- 4222022/Beijing Municipal Natural Science Foundation
LinkOut - more resources
Full Text Sources
Miscellaneous
