

A densely interconnected network for deep learning accelerated MRI
- PMID: 36103029
- PMCID: PMC9992260
- DOI: 10.1007/s10334-022-01041-3
A densely interconnected network for deep learning accelerated MRI
Abstract
Objective: To improve accelerated MRI reconstruction through a densely connected cascading deep learning reconstruction framework.
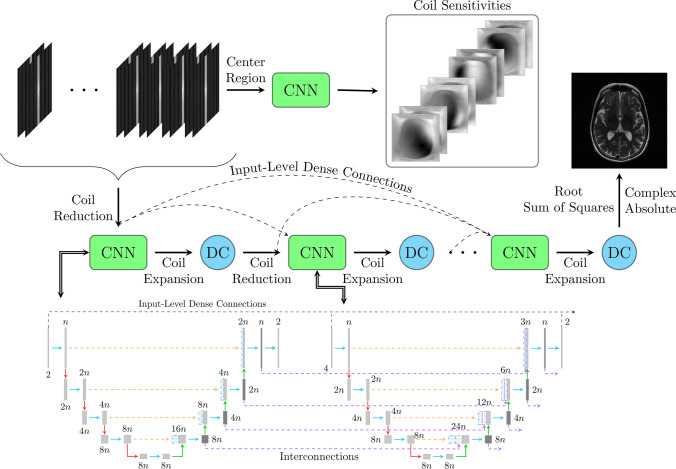
Materials and methods: A cascading deep learning reconstruction framework (reference model) was modified by applying three architectural modifications: input-level dense connections between cascade inputs and outputs, an improved deep learning sub-network, and long-range skip-connections between subsequent deep learning networks. An ablation study was performed, where five model configurations were trained on the NYU fastMRI neuro dataset with an end-to-end scheme conjunct on four- and eightfold acceleration. The trained models were evaluated by comparing their respective structural similarity index measure (SSIM), normalized mean square error (NMSE), and peak signal to noise ratio (PSNR).
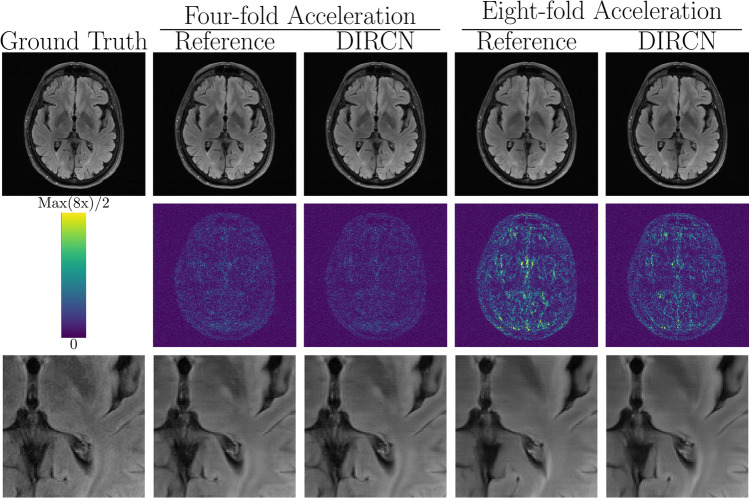
Results: The proposed densely interconnected residual cascading network (DIRCN), utilizing all three suggested modifications achieved a SSIM improvement of 8% and 11%, a NMSE improvement of 14% and 23%, and a PSNR improvement of 2% and 3% for four- and eightfold acceleration, respectively. In an ablation study, the individual architectural modifications all contributed to this improvement for both acceleration factors, by improving the SSIM, NMSE, and PSNR with approximately 2-4%, 4-9%, and 0.5-1%, respectively.
Conclusion: The proposed architectural modifications allow for simple adjustments on an already existing cascading framework to further improve the resulting reconstructions.
Keywords: Deep learning; Image reconstruction; MRI.
© 2022. The Author(s).
Conflict of interest statement
M.W.A. Caan is shareholder of Nico.lab International Ltd.
Figures









References
-
- Pruessmann KP, Weiger M, Scheidegger MB, Boesiger P (1999) SENSE: Sensitivity encoding for fast MRI. Magn Reson Med 42:952–962. 10.1002/(SICI)1522-2594(199911)42:5 - PubMed
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
