

Expert-level detection of pathologies from unannotated chest X-ray images via self-supervised learning
- PMID: 36109605
- PMCID: PMC9792370
- DOI: 10.1038/s41551-022-00936-9
Expert-level detection of pathologies from unannotated chest X-ray images via self-supervised learning
Abstract
In tasks involving the interpretation of medical images, suitably trained machine-learning models often exceed the performance of medical experts. Yet such a high-level of performance typically requires that the models be trained with relevant datasets that have been painstakingly annotated by experts. Here we show that a self-supervised model trained on chest X-ray images that lack explicit annotations performs pathology-classification tasks with accuracies comparable to those of radiologists. On an external validation dataset of chest X-rays, the self-supervised model outperformed a fully supervised model in the detection of three pathologies (out of eight), and the performance generalized to pathologies that were not explicitly annotated for model training, to multiple image-interpretation tasks and to datasets from multiple institutions.
© 2022. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures
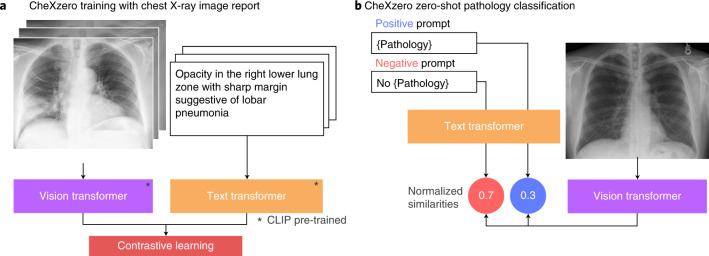
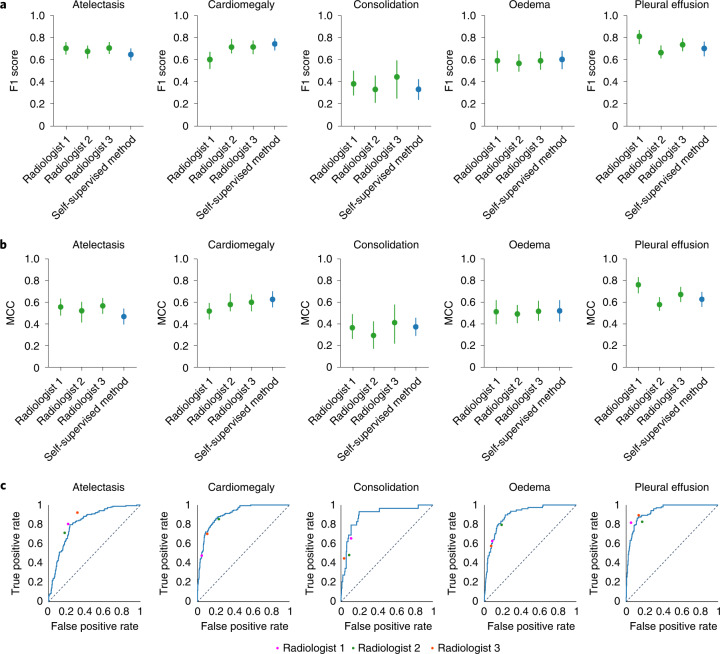
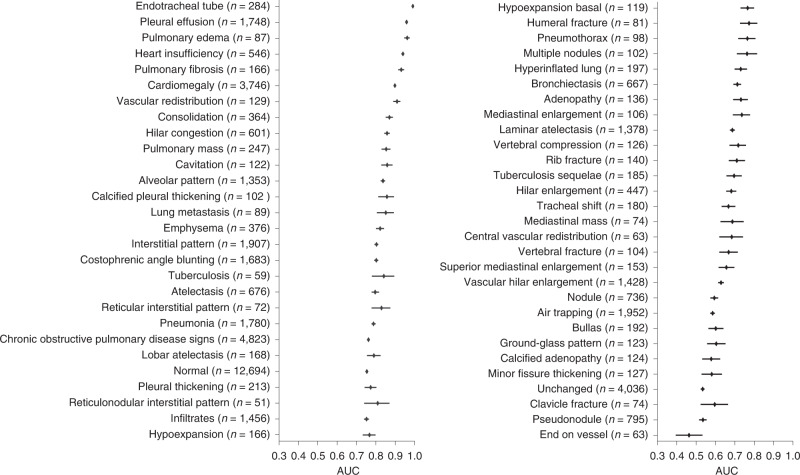
References
-
- Rajpurkar, P., et al. 2017. CheXNet: radiologist-level pneumonia detection on chest X-Rays with deep learning. arXiv10.48550/arXiv.1711.05225 (2017).
-
- Litjens, G. et al. A survey on deep learning in medical image analysis. Med. Image Anal.42, 60–88 (2017). - PubMed
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
