

A Comprehensive Survey of Depth Completion Approaches
- PMID: 36146318
- PMCID: PMC9506233
- DOI: 10.3390/s22186969
A Comprehensive Survey of Depth Completion Approaches
Abstract
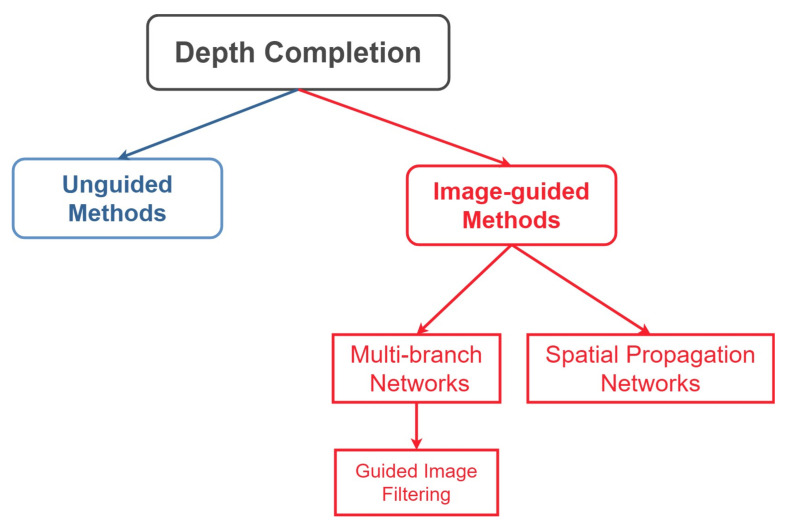
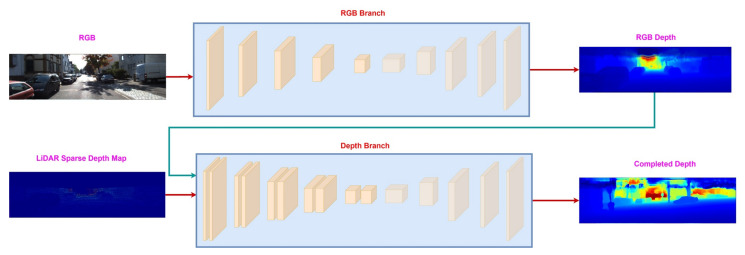
Depth maps produced by LiDAR-based approaches are sparse. Even high-end LiDAR sensors produce highly sparse depth maps, which are also noisy around the object boundaries. Depth completion is the task of generating a dense depth map from a sparse depth map. While the earlier approaches focused on directly completing this sparsity from the sparse depth maps, modern techniques use RGB images as a guidance tool to resolve this problem. Whilst many others rely on affinity matrices for depth completion. Based on these approaches, we have divided the literature into two major categories; unguided methods and image-guided methods. The latter is further subdivided into multi-branch and spatial propagation networks. The multi-branch networks further have a sub-category named image-guided filtering. In this paper, for the first time ever we present a comprehensive survey of depth completion methods. We present a novel taxonomy of depth completion approaches, review in detail different state-of-the-art techniques within each category for depth completion of LiDAR data, and provide quantitative results for the approaches on KITTI and NYUv2 depth completion benchmark datasets.
Keywords: depth completion; depth maps; image-guidance.
Conflict of interest statement
The authors declare no conflict of interest.
Figures







References
-
- Cui Z., Heng L., Yeo Y.C., Geiger A., Pollefeys M., Sattler T. Real-time dense mapping for self-driving vehicles using fisheye cameras; Proceedings of the 2019 International Conference on Robotics and Automation (ICRA); Montreal, QC, Canada. 20–24 May 2019; pp. 6087–6093.
-
- Häne C., Heng L., Lee G.H., Fraundorfer F., Furgale P., Sattler T., Pollefeys M. 3D visual perception for self-driving cars using a multi-camera system: Calibration, mapping, localization, and obstacle detection. Image Vis. Comput. 2017;68:14–27. doi: 10.1016/j.imavis.2017.07.003. - DOI
-
- Wang K., Zhang Z., Yan Z., Li X., Xu B., Li J., Yang J. Regularizing Nighttime Weirdness: Efficient Self-supervised Monocular Depth Estimation in the Dark; Proceedings of the IEEE/CVF International Conference on Computer Vision; Virtual. 11–17 October 2021; pp. 16055–16064.
-
- Song X., Wang P., Zhou D., Zhu R., Guan C., Dai Y., Su H., Li H., Yang R. Apollocar3d: A large 3d car instance understanding benchmark for autonomous driving; Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition; Long Beach, CA, USA. 16–17 June 2019; pp. 5452–5462.
-
- Liao Y., Huang L., Wang Y., Kodagoda S., Yu Y., Liu Y. Parse geometry from a line: Monocular depth estimation with partial laser observation; Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA); Singapore. 29 May–3 June 2017; pp. 5059–5066.
Publication types
LinkOut - more resources
Full Text Sources
