

FASTAptameR 2.0: A web tool for combinatorial sequence selections
- PMID: 36159593
- PMCID: PMC9464650
- DOI: 10.1016/j.omtn.2022.08.030
FASTAptameR 2.0: A web tool for combinatorial sequence selections
Abstract
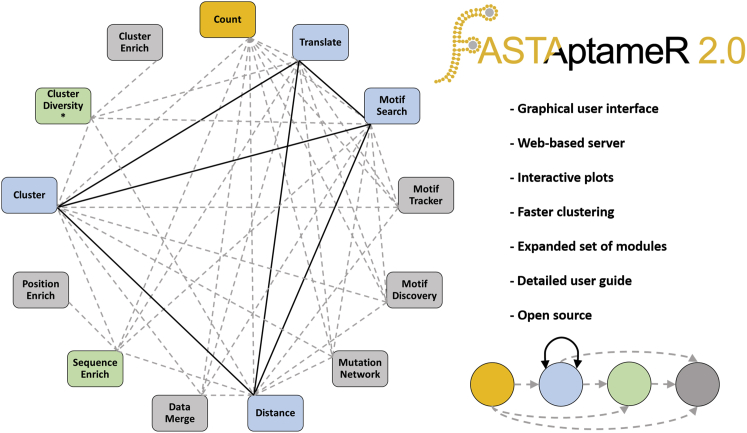
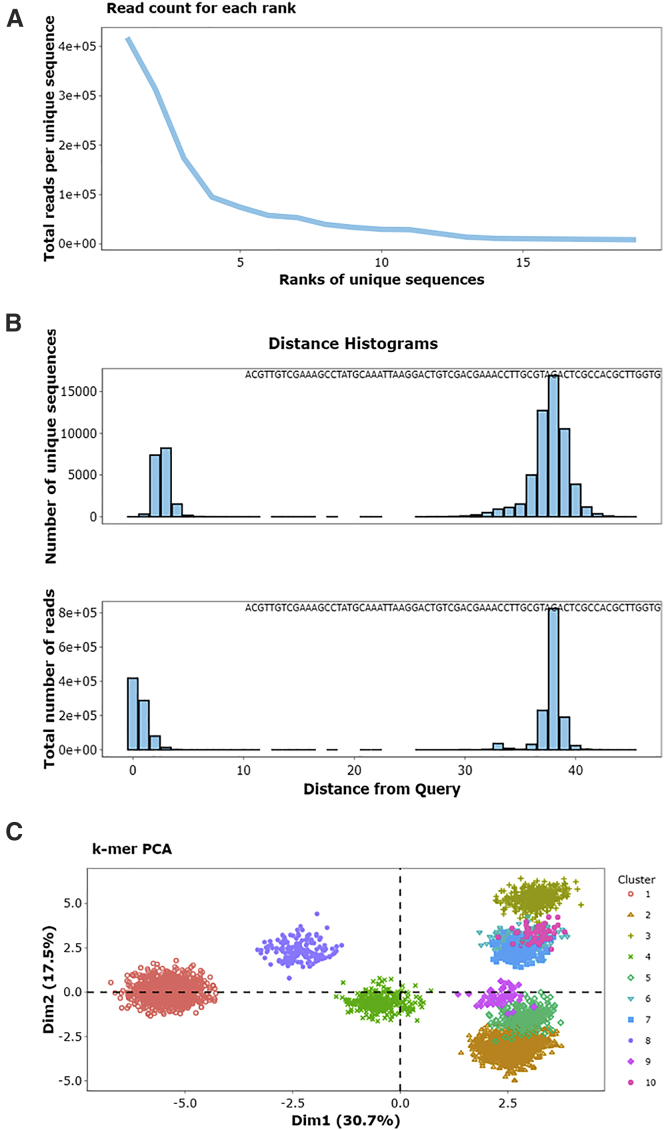
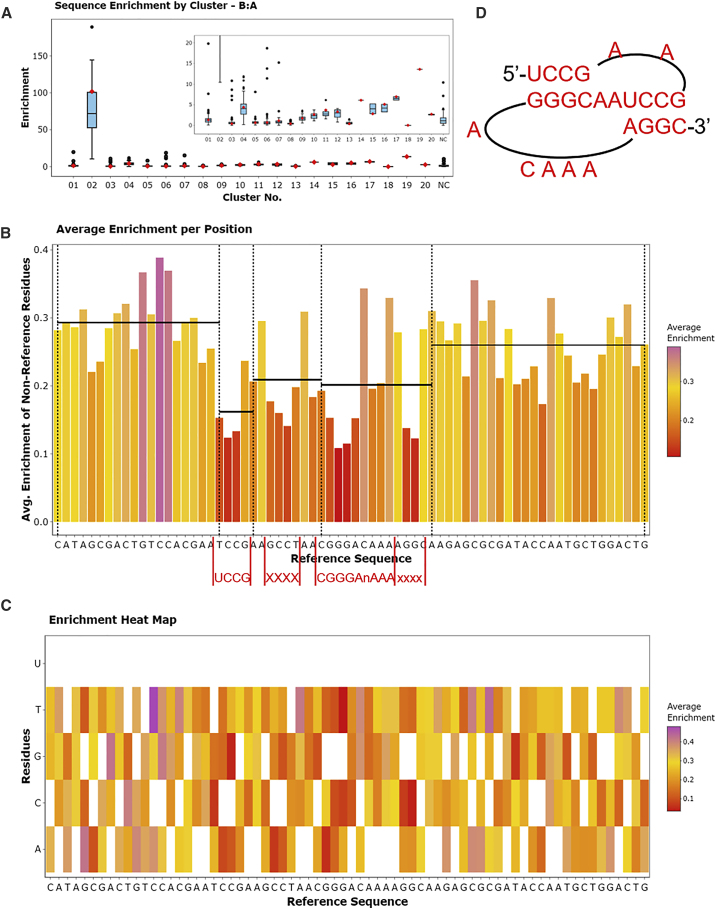
Combinatorial selections are powerful strategies for identifying biopolymers with specific biological, biomedical, or chemical characteristics. Unfortunately, most available software tools for high-throughput sequencing analysis have high entrance barriers for many users because they require extensive programming expertise. FASTAptameR 2.0 is an R-based reimplementation of FASTAptamer designed to minimize this barrier while maintaining the ability to answer complex sequence-level and population-level questions. This open-source toolkit features a user-friendly web tool, interactive graphics, up to 100 times faster clustering, an expanded module set, and an extensive user guide. FASTAptameR 2.0 accepts diverse input polymer types and can be applied to any sequence-encoded selection.
Keywords: MT: Bioinformatics; Next-generation sequencing; SELEX; aptamer; combinatorial selection; directed evolution; phage display; ribozyme; sequence analysis; synthetic biology.
© 2022 The Authors.
Conflict of interest statement
The authors declare no competing interests.
Figures

References
LinkOut - more resources
Full Text Sources
