

Structural basis for the interaction between the first SURP domain of the SF3A1 subunit in U2 snRNP and the human splicing factor SF1
- PMID: 36173164
- PMCID: PMC9514218
- DOI: 10.1002/pro.4437
Structural basis for the interaction between the first SURP domain of the SF3A1 subunit in U2 snRNP and the human splicing factor SF1
Abstract
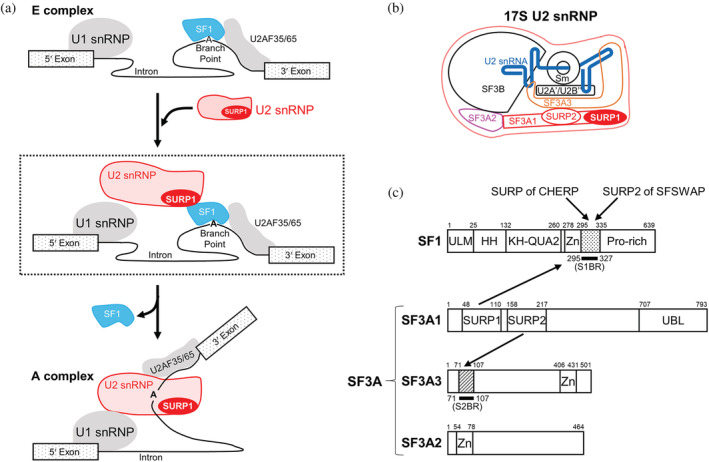
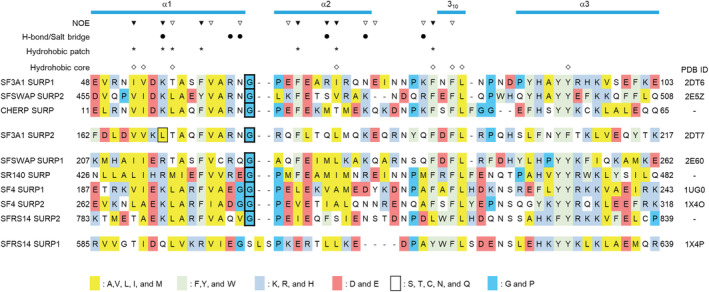
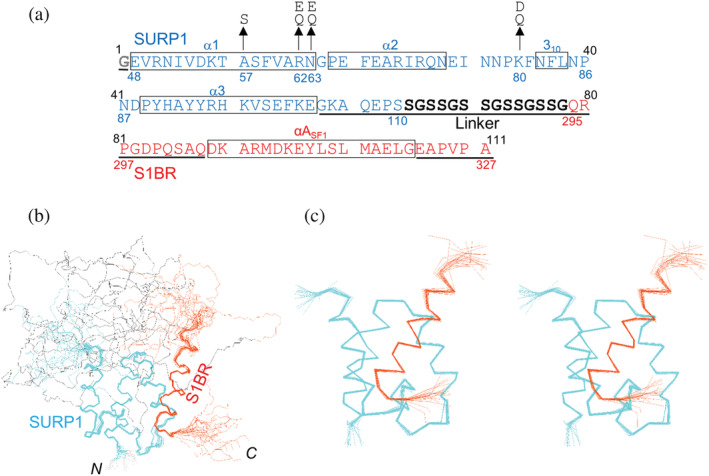
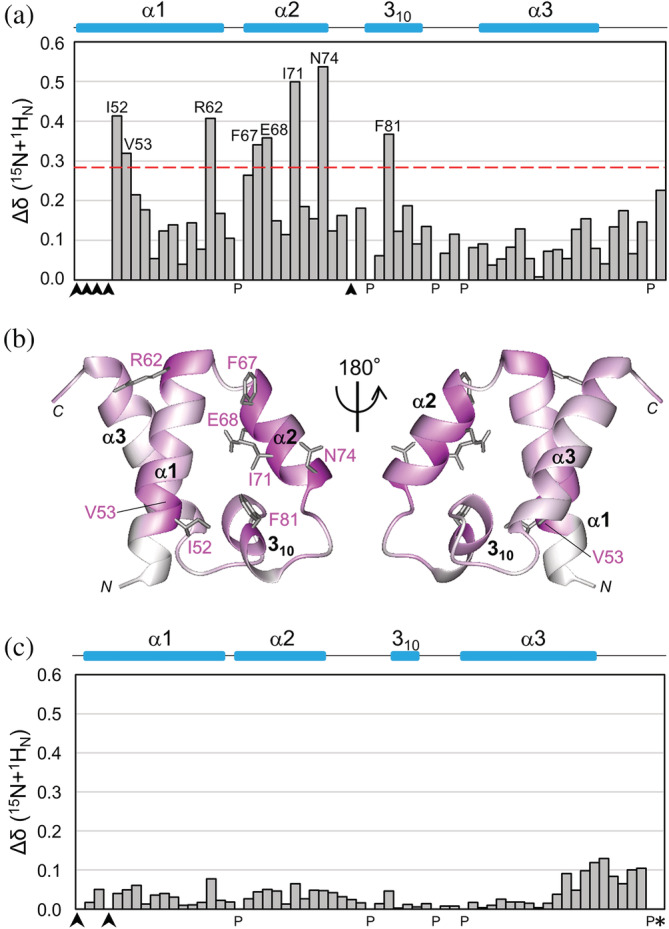
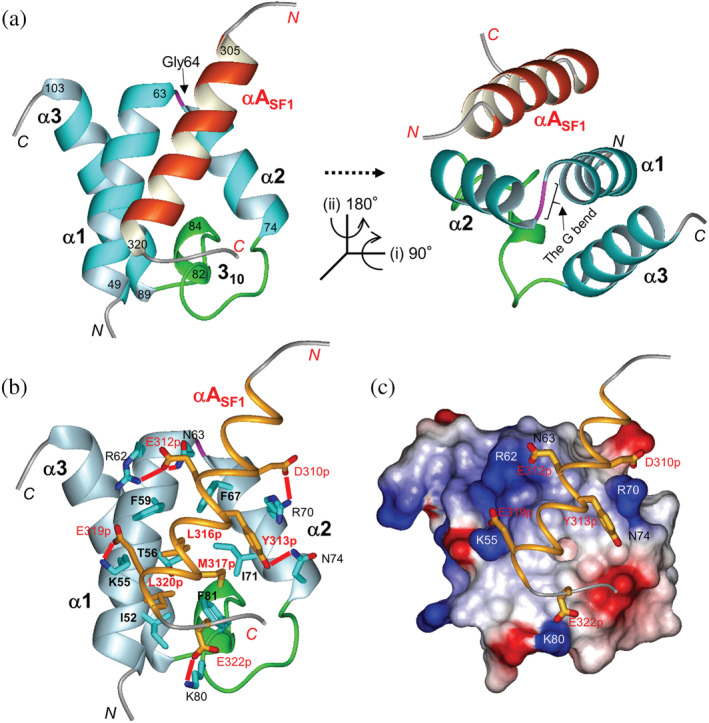
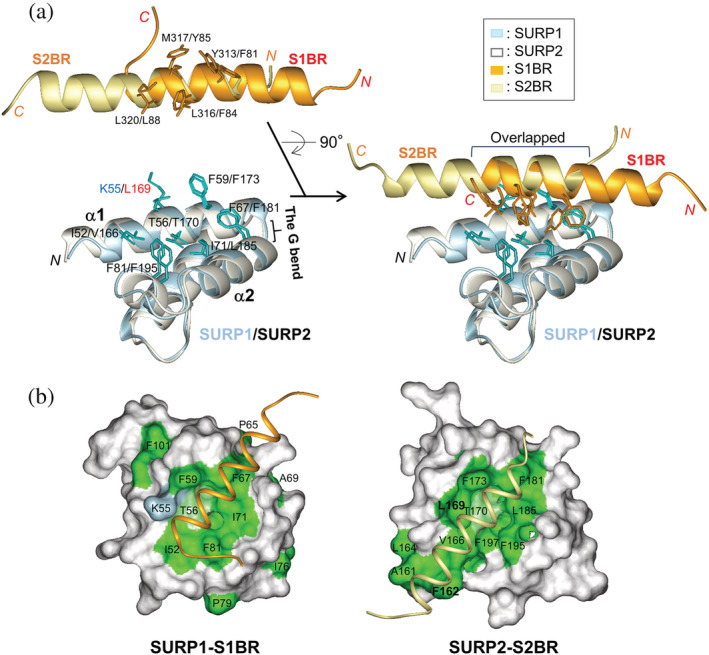
SURP domains are exclusively found in splicing-related proteins in all eukaryotes. SF3A1, a component of the U2 snRNP, has two tandem SURP domains, SURP1, and SURP2. SURP2 is permanently associated with a specific short region of SF3A3 within the SF3A protein complex whereas, SURP1 binds to the splicing factor SF1 for recruitment of U2 snRNP to the early spliceosomal complex, from which SF1 is dissociated during complex conversion. Here, we determined the solution structure of the complex of SURP1 and the human SF1 fragment using nuclear magnetic resonance (NMR) methods. SURP1 adopts the canonical topology of α1-α2-310 -α3, in which α1 and α2 are connected by a single glycine residue in a particular backbone conformation, allowing the two α-helices to be fixed at an acute angle. A hydrophobic patch, which is part of the characteristic surface formed by α1 and α2, specifically contacts a hydrophobic cluster on a 16-residue α-helix of the SF1 fragment. Furthermore, whereas only hydrophobic interactions occurred between SURP2 and the SF3A3 fragment, several salt bridges and hydrogen bonds were found between the residues of SURP1 and the SF1 fragment. This finding was confirmed through mutational studies using bio-layer interferometry. The study also revealed that the dissociation constant between SURP1 and the SF1 fragment peptide was approximately 20 μM, indicating a weak or transient interaction. Collectively, these results indicate that the interplay between U2 snRNP and SF1 involves a transient interaction of SURP1, and this transient interaction appears to be common to most SURP domains, except for SURP2.
Keywords: NMR; SF1; SF3A1; SF3a120; SURP; SWAP; U2 snRNP; bio-layer interferometry; complex structure; splicing.
© 2022 The Authors. Protein Science published by Wiley Periodicals LLC on behalf of The Protein Society.
Conflict of interest statement
The authors declare no conflict of interests.
Figures
References
-
- Wahl MC, Will CL, Lührmann R. The spliceosome: Design principles of a dynamic RNP machine. Cell. 2009;136:701–718. - PubMed
-
- Liu Z, Luyten I, Bottomley MJ, et al. Structural basis for recognition of the intron branch site RNA by splicing factor 1. Science. 2001;294:1098–1102. - PubMed
-
- Das R, Zhou Z, Reed R. Functional association of U2 snRNP with the ATP‐independent spliceosomal complex E. Mol Cell. 2000;5:779–787. - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Molecular Biology Databases
