

Deep language algorithms predict semantic comprehension from brain activity
- PMID: 36175483
- PMCID: PMC9522791
- DOI: 10.1038/s41598-022-20460-9
Deep language algorithms predict semantic comprehension from brain activity
Abstract
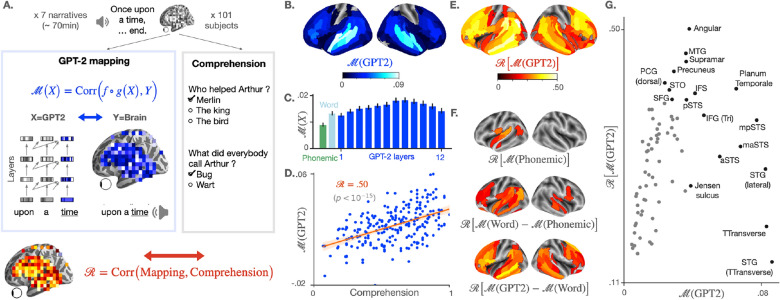
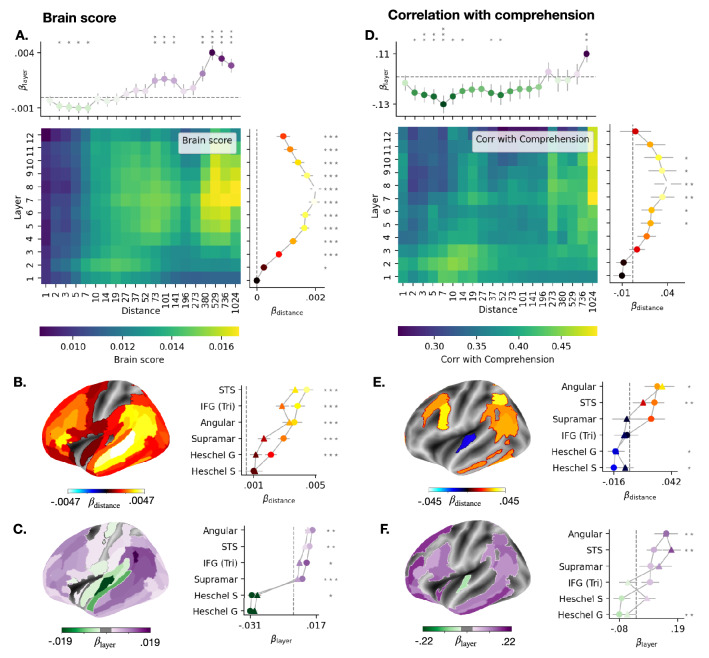
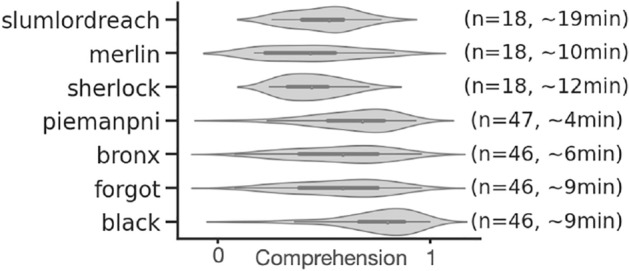
Deep language algorithms, like GPT-2, have demonstrated remarkable abilities to process text, and now constitute the backbone of automatic translation, summarization and dialogue. However, whether these models encode information that relates to human comprehension still remains controversial. Here, we show that the representations of GPT-2 not only map onto the brain responses to spoken stories, but they also predict the extent to which subjects understand the corresponding narratives. To this end, we analyze 101 subjects recorded with functional Magnetic Resonance Imaging while listening to 70 min of short stories. We then fit a linear mapping model to predict brain activity from GPT-2's activations. Finally, we show that this mapping reliably correlates ([Formula: see text]) with subjects' comprehension scores as assessed for each story. This effect peaks in the angular, medial temporal and supra-marginal gyri, and is best accounted for by the long-distance dependencies generated in the deep layers of GPT-2. Overall, this study shows how deep language models help clarify the brain computations underlying language comprehension.
© 2022. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures
References
-
- Radford A, Wu J, Child R, Luan D, Amodei D, Sutskever I. Language models are unsupervised multitask learners. OpenAI blog. 2019;1(8):9.
-
- Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv:1810.04805 [cs], (2019).
-
- Yang, Z., Dai, Z., Yang, Y., Carbonell, J., Salakhutdinov, R. R., & Le, Q. V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. arXiv:1906.08237 [cs], (2020).
-
- Caucheteux, C., Gramfort, A., & King, J. R. Model-based analysis of brain activity reveals the hierarchy of language in 305 subjects. In EMNLP 2021-Conference on Empirical Methods in Natural Language Processing, (2021a).
-
- Toneva, M. & Wehbe, L. Interpreting and improving natural-language processing (in machines) with natural language-processing (in the brain). arXiv:1905.11833 [cs, q-bio], (2019).
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
