

Investigation of independent reinforcement learning algorithms in multi-agent environments
- PMID: 36204598
- PMCID: PMC9530713
- DOI: 10.3389/frai.2022.805823
Investigation of independent reinforcement learning algorithms in multi-agent environments
Abstract
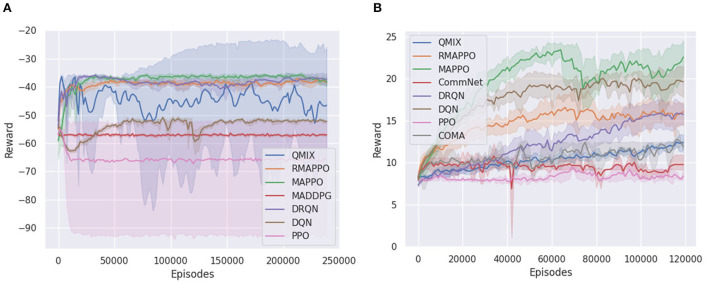
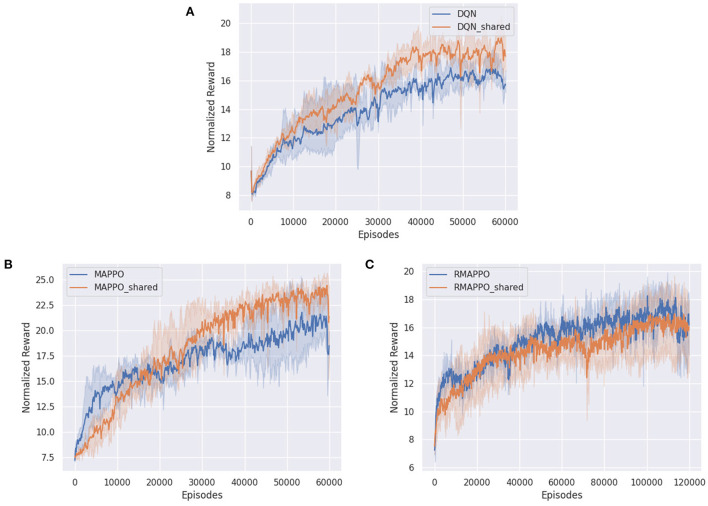
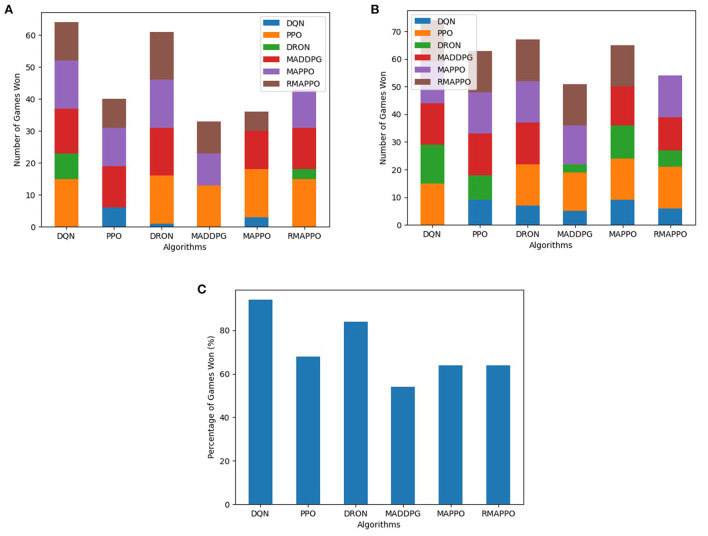
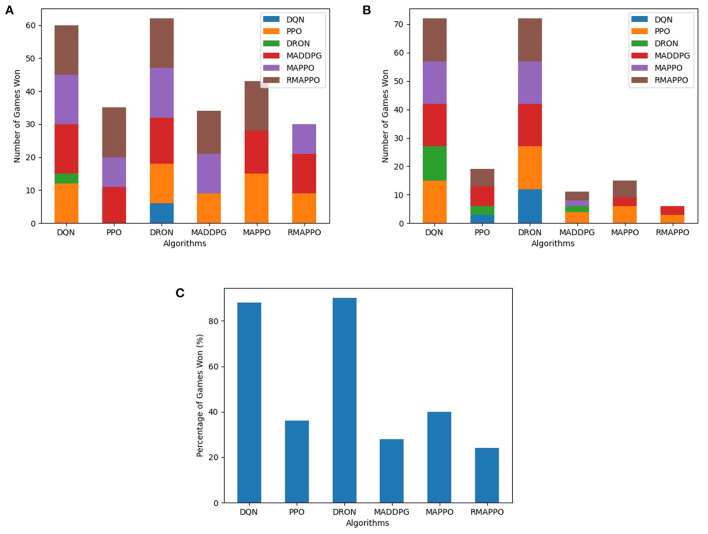
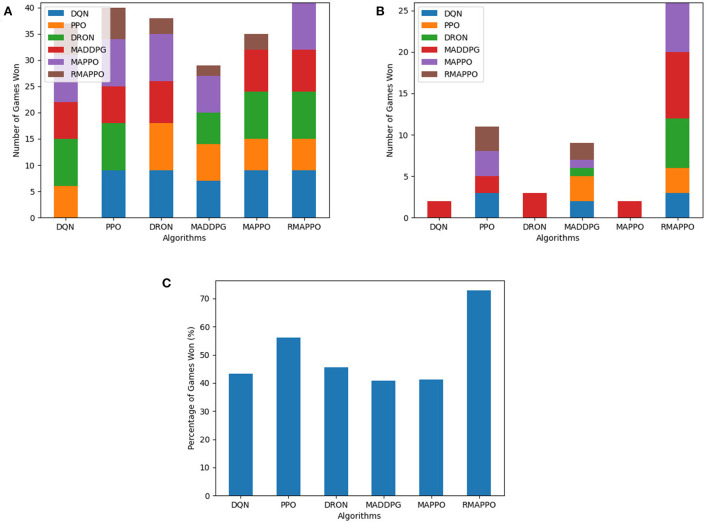
Independent reinforcement learning algorithms have no theoretical guarantees for finding the best policy in multi-agent settings. However, in practice, prior works have reported good performance with independent algorithms in some domains and bad performance in others. Moreover, a comprehensive study of the strengths and weaknesses of independent algorithms is lacking in the literature. In this paper, we carry out an empirical comparison of the performance of independent algorithms on seven PettingZoo environments that span the three main categories of multi-agent environments, i.e., cooperative, competitive, and mixed. For the cooperative setting, we show that independent algorithms can perform on par with multi-agent algorithms in fully-observable environments, while adding recurrence improves the learning of independent algorithms in partially-observable environments. In the competitive setting, independent algorithms can perform on par or better than multi-agent algorithms, even in more challenging environments. We also show that agents trained via independent algorithms learn to perform well individually, but fail to learn to cooperate with allies and compete with enemies in mixed environments.
Keywords: artificial intelligence; deep learning; machine learning; multi-agent reinforcement learning; reinforcement learning.
Copyright © 2022 Lee, Ganapathi Subramanian and Crowley.
Conflict of interest statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Figures
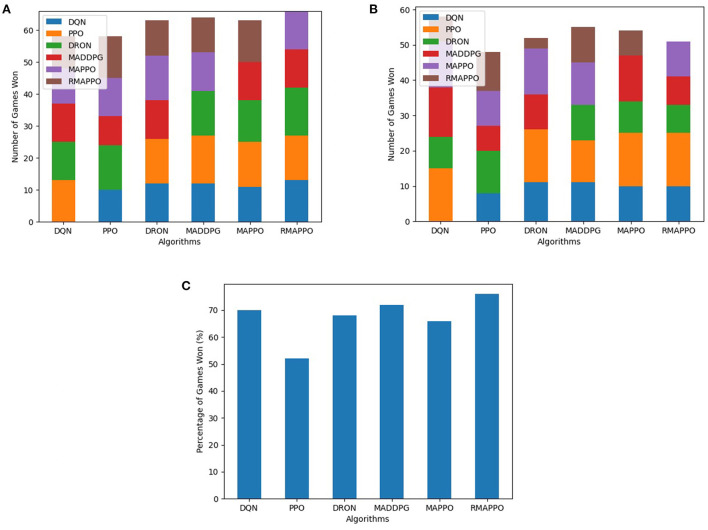
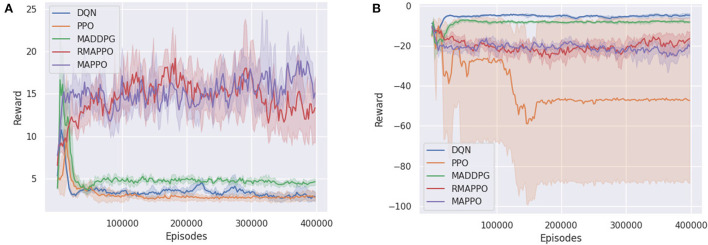
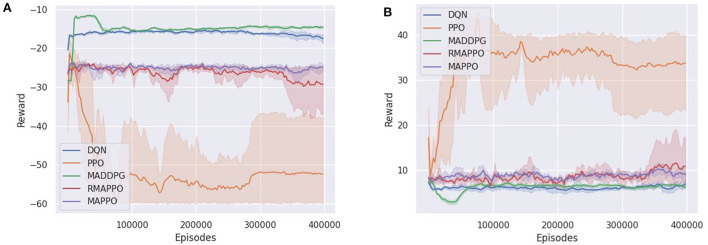
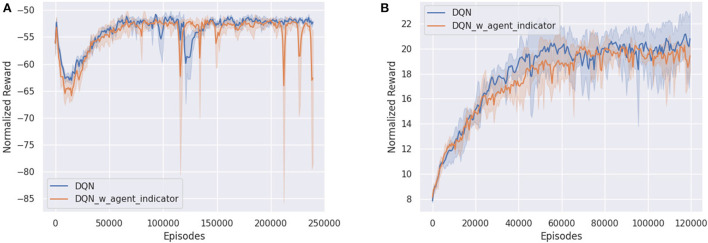
Similar articles
-
MACRPO: Multi-agent cooperative recurrent policy optimization.Front Robot AI. 2024 Dec 20;11:1394209. doi: 10.3389/frobt.2024.1394209. eCollection 2024. Front Robot AI. 2024. PMID: 39760046 Free PMC article.
-
LJIR: Learning Joint-Action Intrinsic Reward in cooperative multi-agent reinforcement learning.Neural Netw. 2023 Oct;167:450-459. doi: 10.1016/j.neunet.2023.08.016. Epub 2023 Aug 22. Neural Netw. 2023. PMID: 37683459
-
IHG-MA: Inductive heterogeneous graph multi-agent reinforcement learning for multi-intersection traffic signal control.Neural Netw. 2021 Jul;139:265-277. doi: 10.1016/j.neunet.2021.03.015. Epub 2021 Mar 22. Neural Netw. 2021. PMID: 33838602
-
A review on utilizing machine learning technology in the fields of electronic emergency triage and patient priority systems in telemedicine: Coherent taxonomy, motivations, open research challenges and recommendations for intelligent future work.Comput Methods Programs Biomed. 2021 Sep;209:106357. doi: 10.1016/j.cmpb.2021.106357. Epub 2021 Aug 16. Comput Methods Programs Biomed. 2021. PMID: 34438223 Review.
-
Deep learning, reinforcement learning, and world models.Neural Netw. 2022 Aug;152:267-275. doi: 10.1016/j.neunet.2022.03.037. Epub 2022 Apr 19. Neural Netw. 2022. PMID: 35569196 Review.
Cited by
-
Multi-Agent Reinforcement Learning in Games: Research and Applications.Biomimetics (Basel). 2025 Jun 6;10(6):375. doi: 10.3390/biomimetics10060375. Biomimetics (Basel). 2025. PMID: 40558344 Free PMC article. Review.
References
-
- Andrychowicz M., Raichuk A., Stańczyk P., Orsini M., Girgin S., Marinier R., et al. . (2020). What matters in on-policy reinforcement learning? a large-scale empirical study. arXiv preprint arXiv:2006.05990. 10.48550/arXiv.2006.05990 - DOI
-
- Bellemare M. G., Naddaf Y., Veness J., Bowling M. (2013). The arcade learning environment: an evaluation platform for general agents. J. Artif. Intell. Res. 47, 253–279. 10.1613/jair.3912 - DOI
-
- Bellman R. (1957). A markovian decision process. J. Math. Mech. 6, 679–684. 10.1512/iumj.1957.6.56038 - DOI
-
- Berner C., Brockman G., Chan B., Cheung V., Debiak P., Dennison C., et al. . (2019). Dota 2 with large scale deep reinforcement learning. arXiv preprint arXiv:1912.06680. 10.48550/arXiv.1912.06680 - DOI
LinkOut - more resources
Full Text Sources
Research Materials