

Fast and scalable search of whole-slide images via self-supervised deep learning
- PMID: 36217022
- PMCID: PMC9792371
- DOI: 10.1038/s41551-022-00929-8
Fast and scalable search of whole-slide images via self-supervised deep learning
Abstract
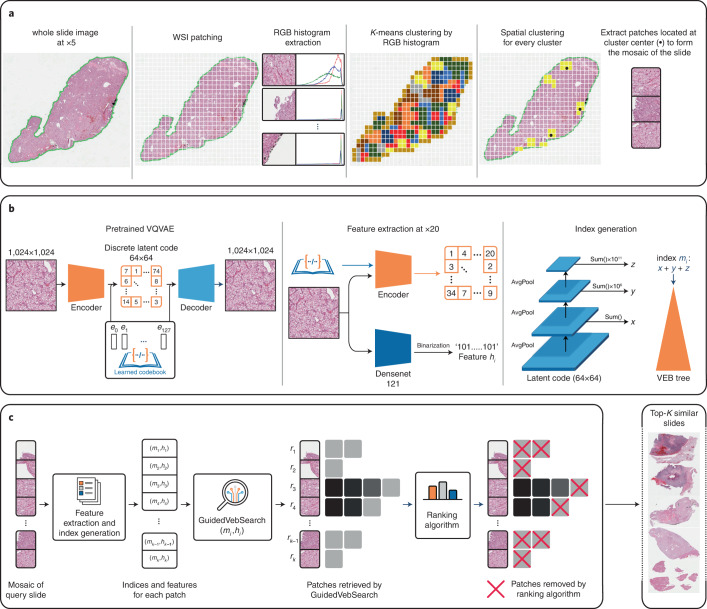
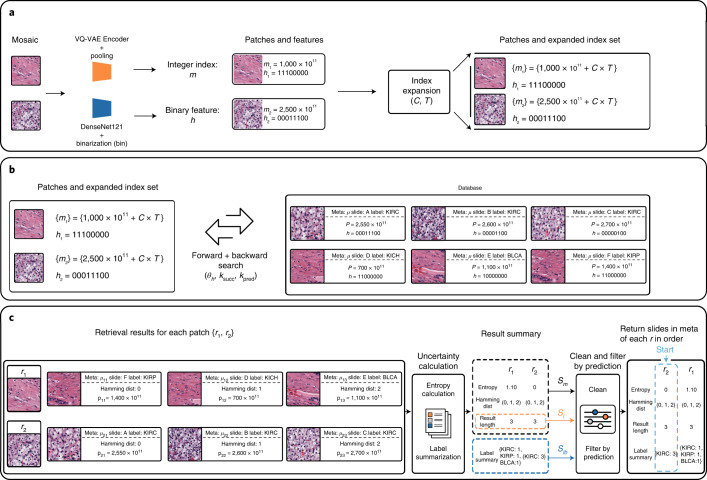
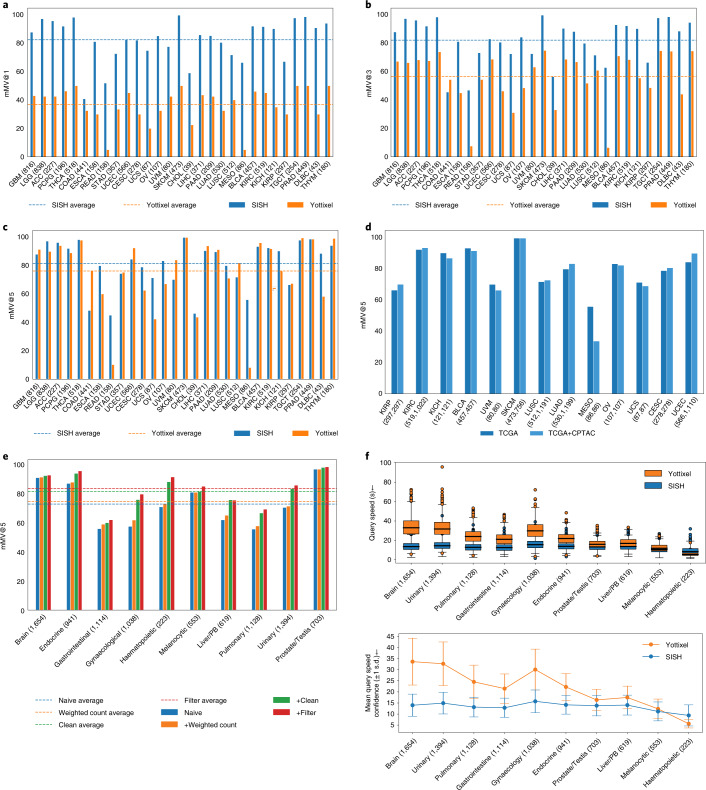
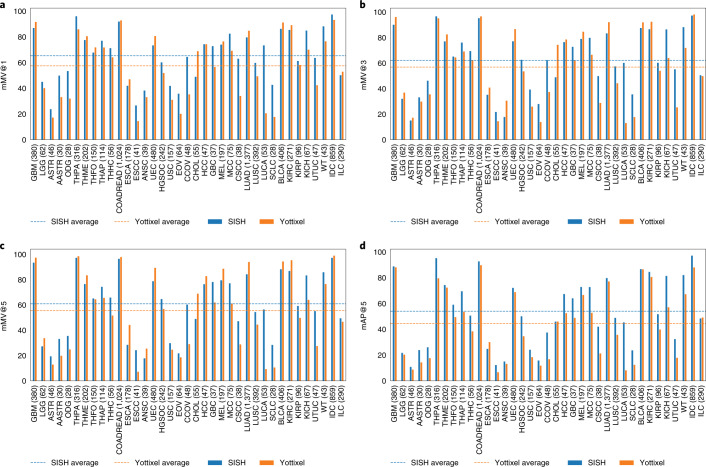
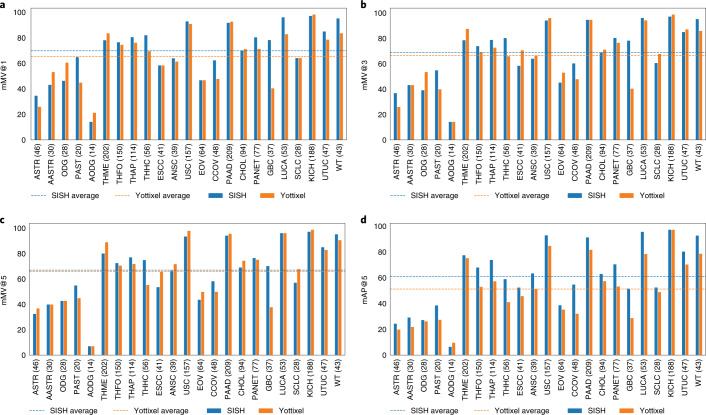
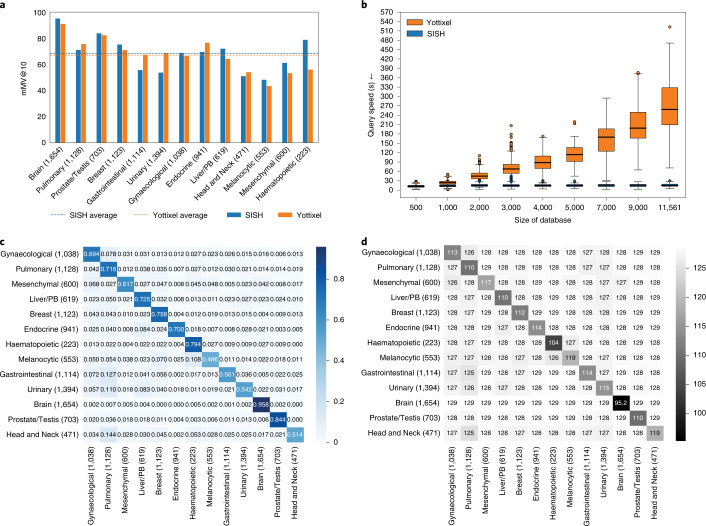
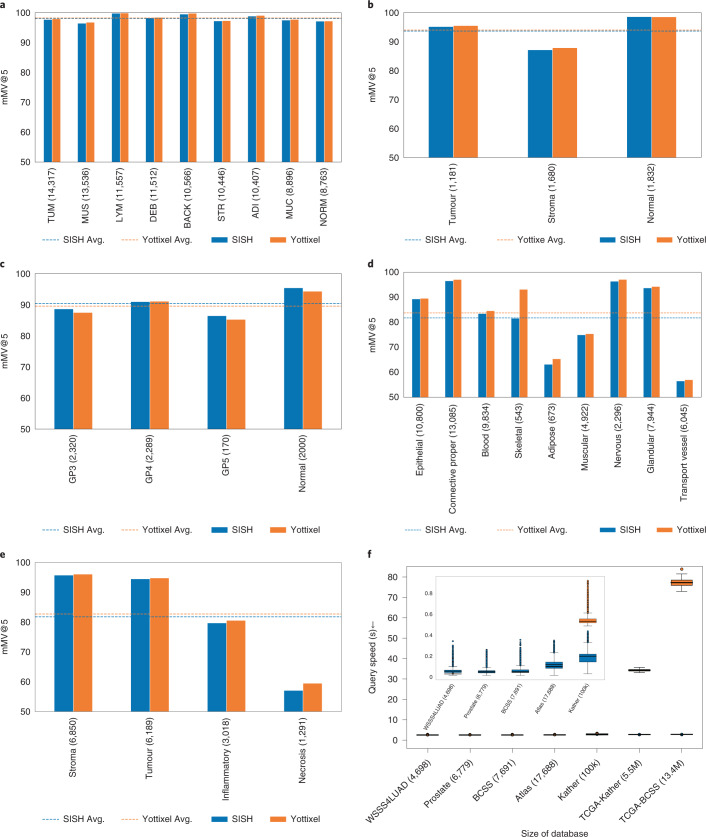
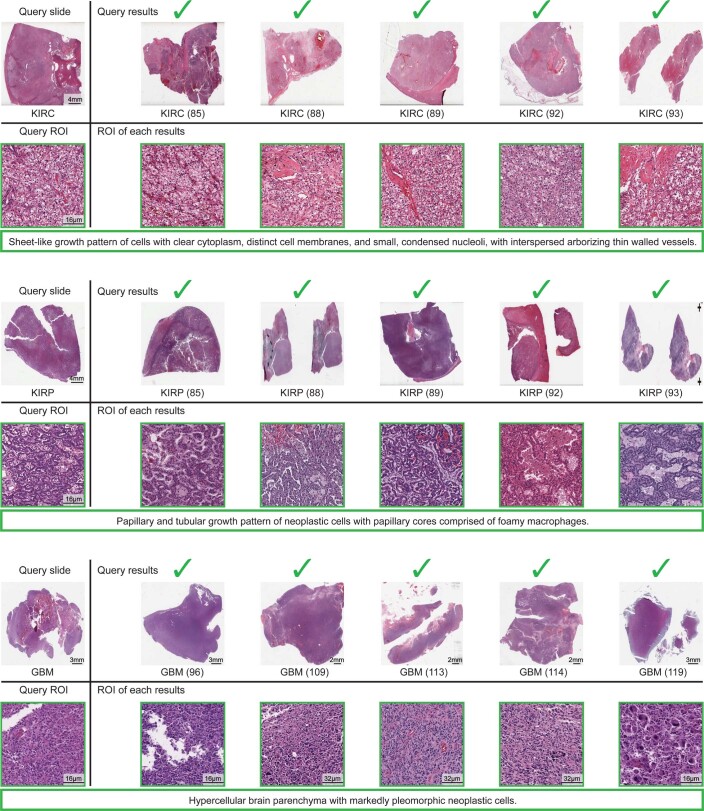
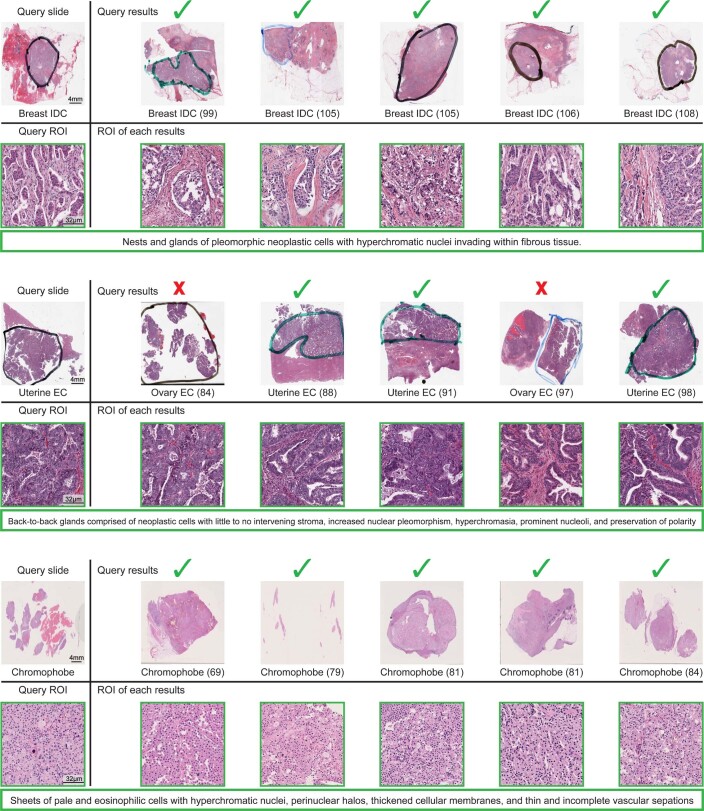
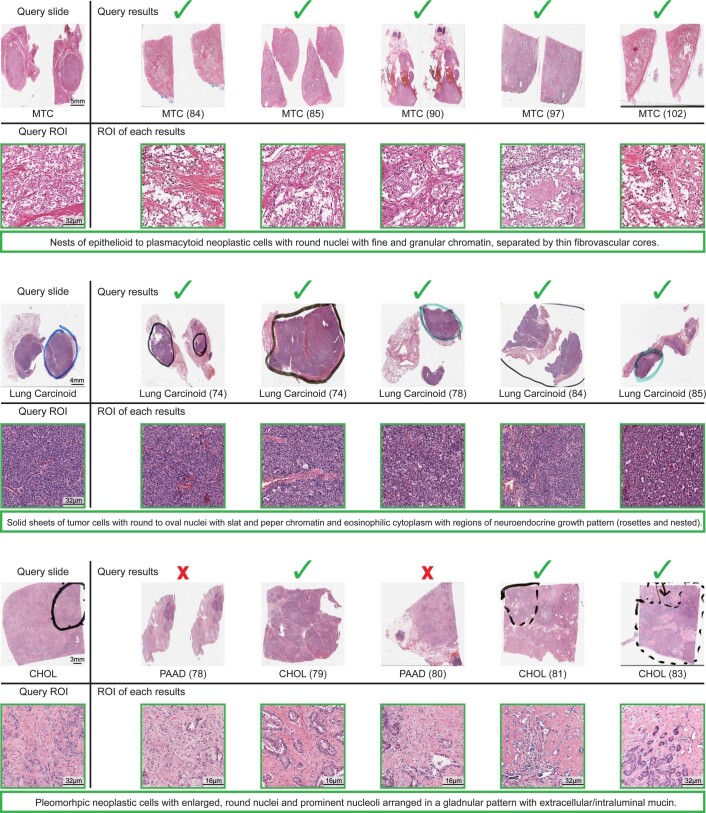
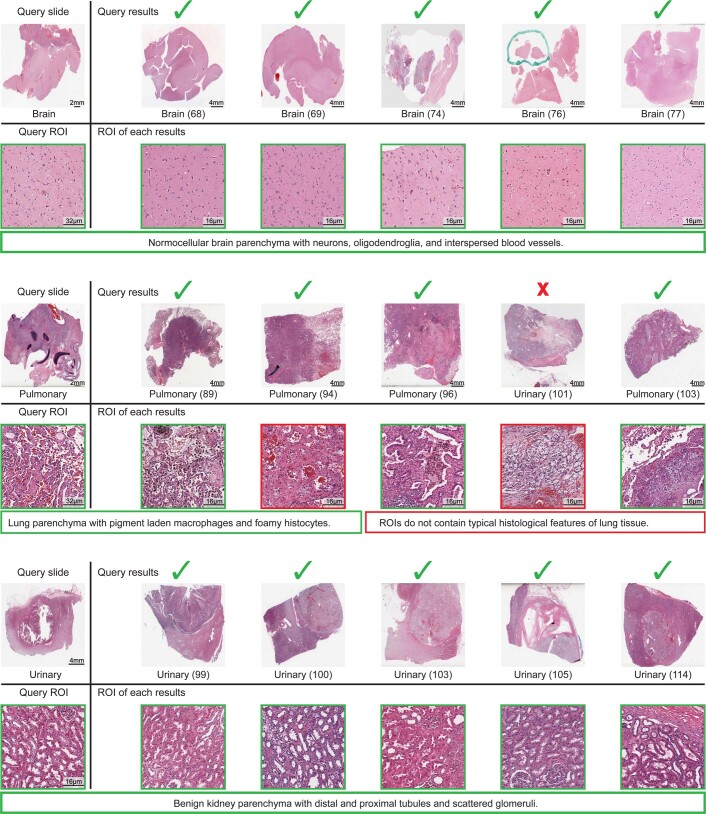
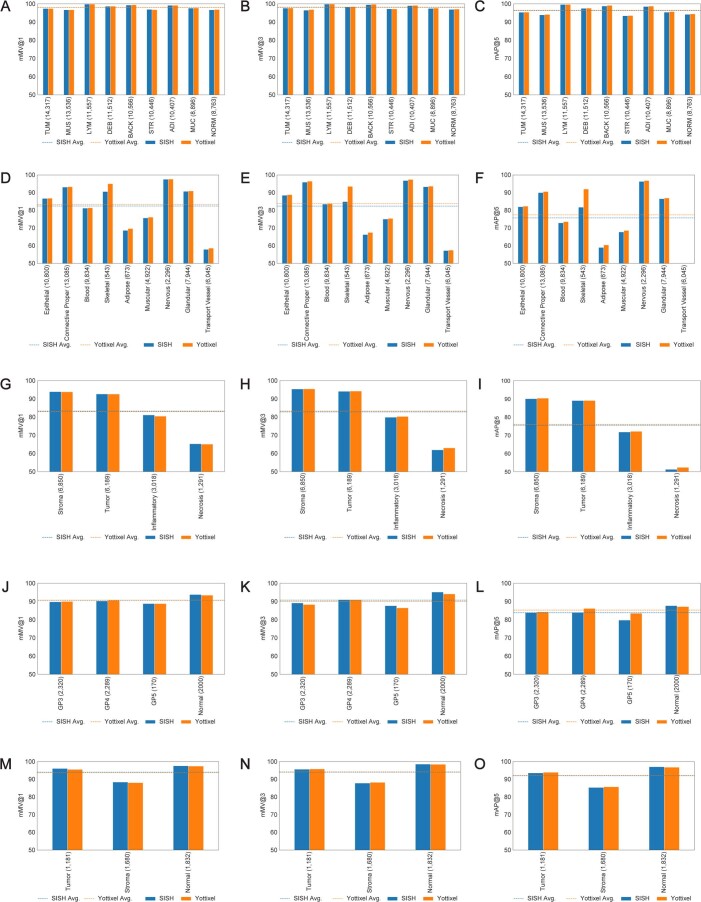
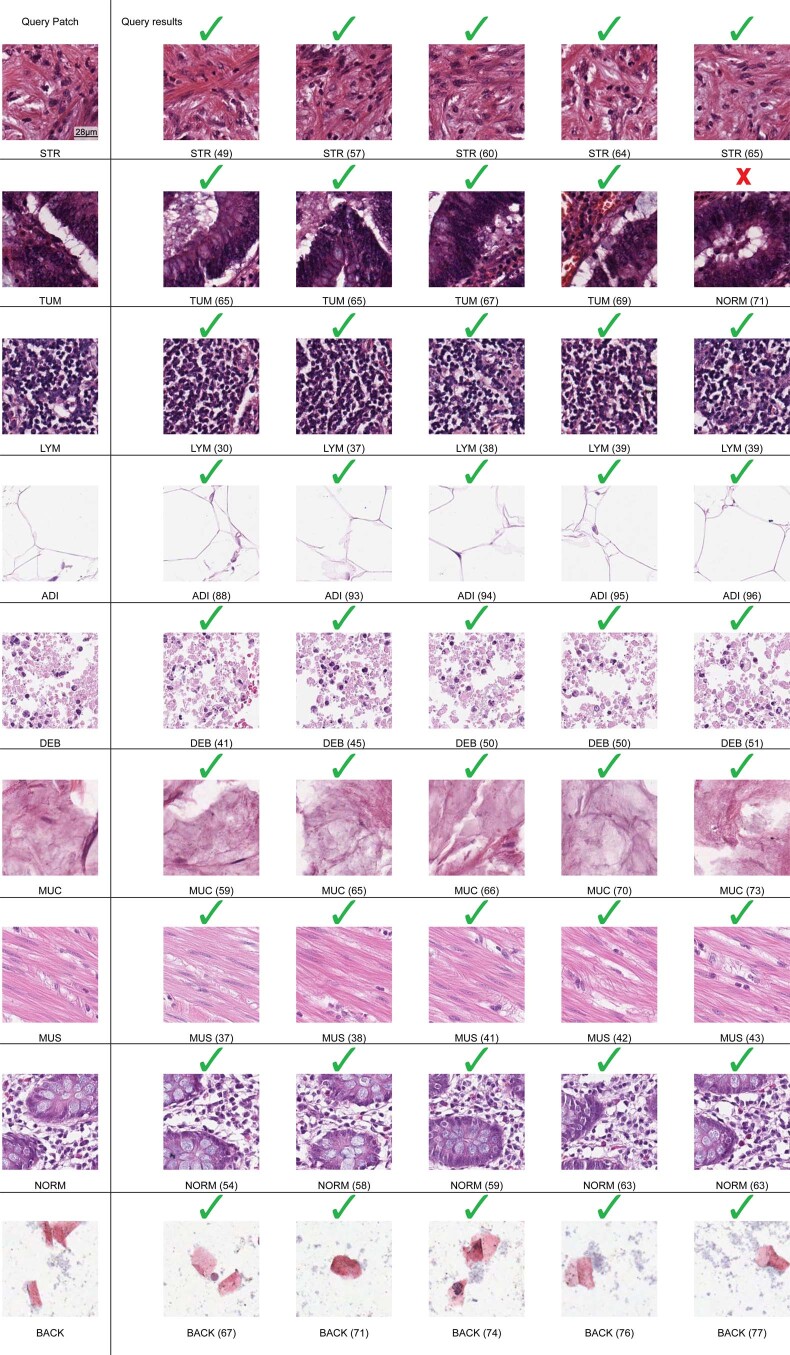
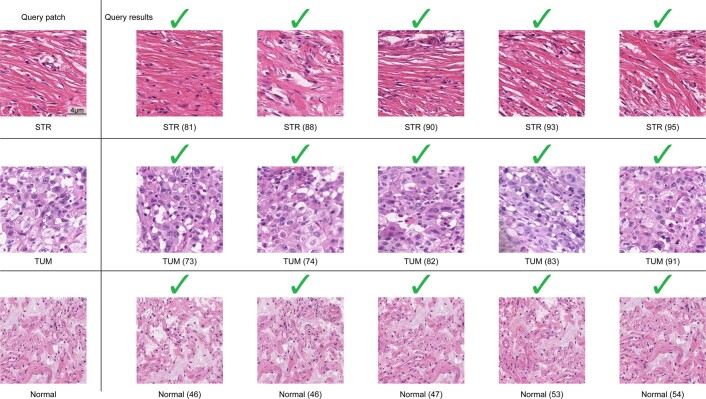
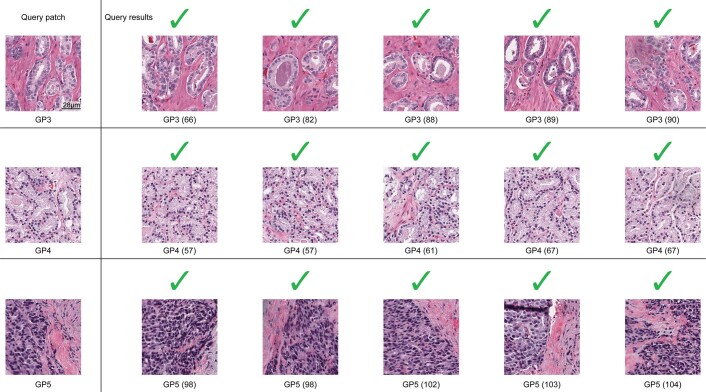
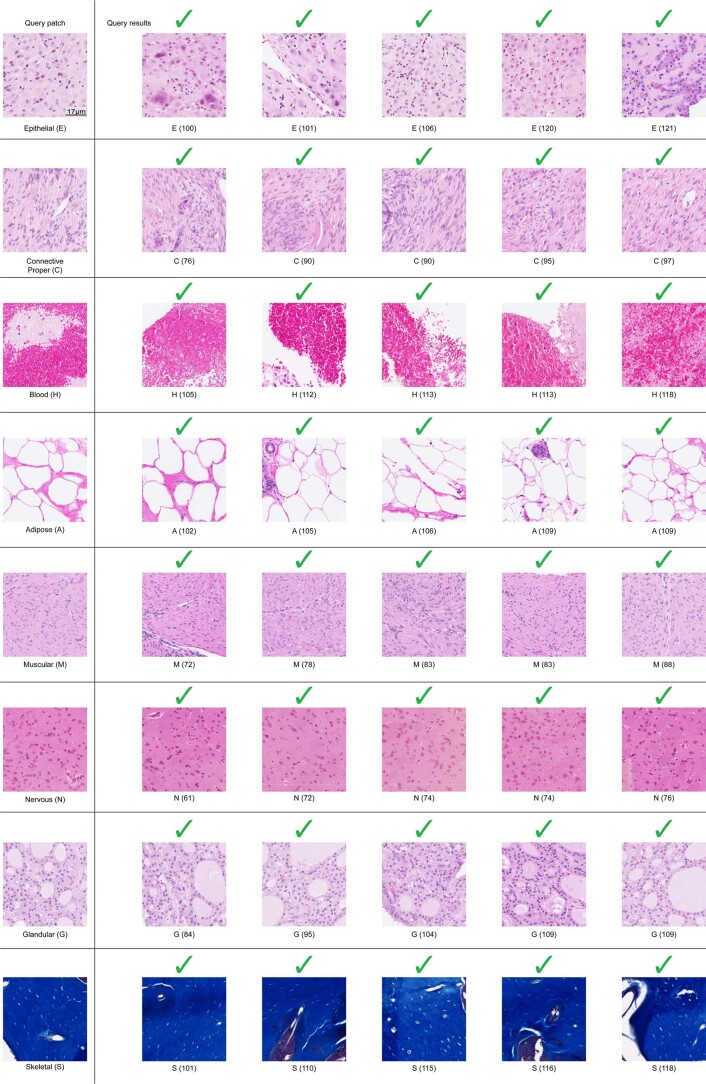
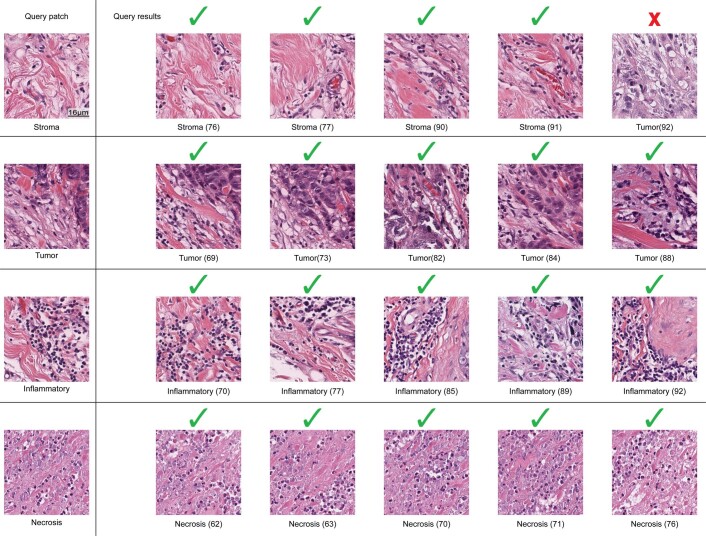
The adoption of digital pathology has enabled the curation of large repositories of gigapixel whole-slide images (WSIs). Computationally identifying WSIs with similar morphologic features within large repositories without requiring supervised training can have significant applications. However, the retrieval speeds of algorithms for searching similar WSIs often scale with the repository size, which limits their clinical and research potential. Here we show that self-supervised deep learning can be leveraged to search for and retrieve WSIs at speeds that are independent of repository size. The algorithm, which we named SISH (for self-supervised image search for histology) and provide as an open-source package, requires only slide-level annotations for training, encodes WSIs into meaningful discrete latent representations and leverages a tree data structure for fast searching followed by an uncertainty-based ranking algorithm for WSI retrieval. We evaluated SISH on multiple tasks (including retrieval tasks based on tissue-patch queries) and on datasets spanning over 22,000 patient cases and 56 disease subtypes. SISH can also be used to aid the diagnosis of rare cancer types for which the number of available WSIs is often insufficient to train supervised deep-learning models.
© 2022. The Author(s).
Conflict of interest statement
F.M. receives research support from Leidos Biomedical Research, Inc. for projects unrelated to this study. The authors declare no other competing interests.
Figures
References
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
