

Emerging Approaches to DNA Data Storage: Challenges and Prospects
- PMID: 36256971
- PMCID: PMC9706676
- DOI: 10.1021/acsnano.2c06748
Emerging Approaches to DNA Data Storage: Challenges and Prospects
Abstract
With the total amount of worldwide data skyrocketing, the global data storage demand is predicted to grow to 1.75 × 1014 GB by 2025. Traditional storage methods have difficulties keeping pace given that current storage media have a maximum density of 103 GB/mm3. As such, data production will far exceed the capacity of currently available storage methods. The costs of maintaining and transferring data, as well as the limited lifespans and significant data losses associated with current technologies also demand advanced solutions for information storage. Nature offers a powerful alternative through the storage of information that defines living organisms in unique orders of four bases (A, T, C, G) located in molecules called deoxyribonucleic acid (DNA). DNA molecules as information carriers have many advantages over traditional storage media. Their high storage density, potentially low maintenance cost, ease of synthesis, and chemical modification make them an ideal alternative for information storage. To this end, rapid progress has been made over the past decade by exploiting user-defined DNA materials to encode information. In this review, we discuss the most recent advances of DNA-based data storage with a major focus on the challenges that remain in this promising field, including the current intrinsic low speed in data writing and reading and the high cost per byte stored. Alternatively, data storage relying on DNA nanostructures (as opposed to DNA sequence) as well as on other combinations of nanomaterials and biomolecules are proposed with promising technological and economic advantages. In summarizing the advances that have been made and underlining the challenges that remain, we provide a roadmap for the ongoing research in this rapidly growing field, which will enable the development of technological solutions to the global demand for superior storage methodologies.
Keywords: DNA; DNA nanostructure; DNA preservation; costs; data storage; decoding; error correction; random access; reading; sequencing.
Conflict of interest statement
The authors declare no competing financial interest.
Figures
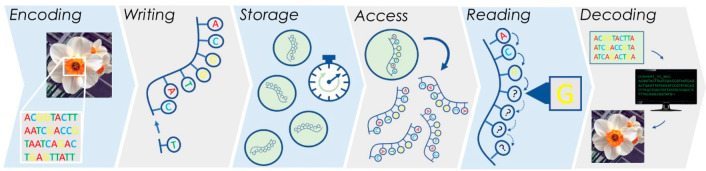
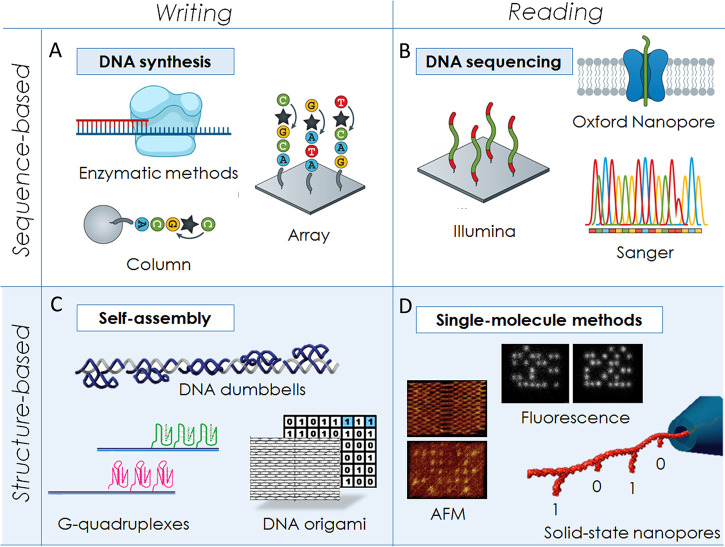
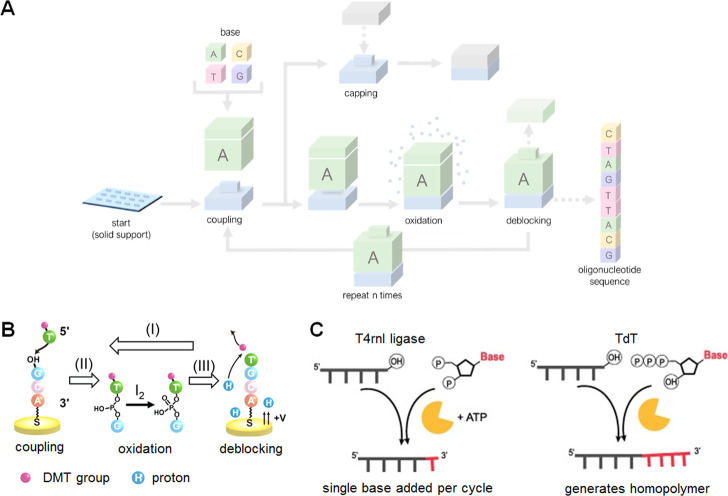
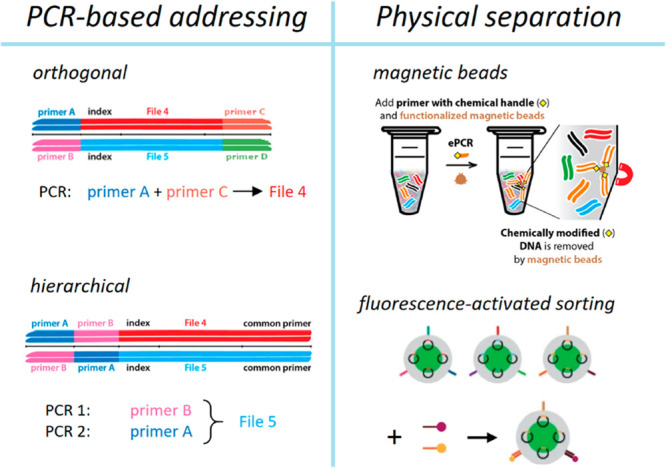
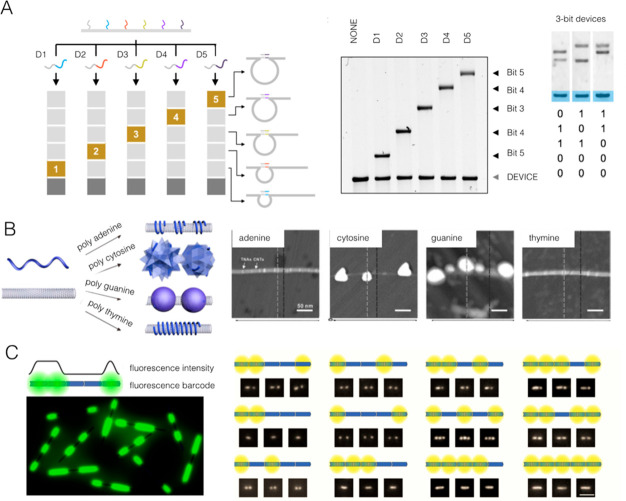
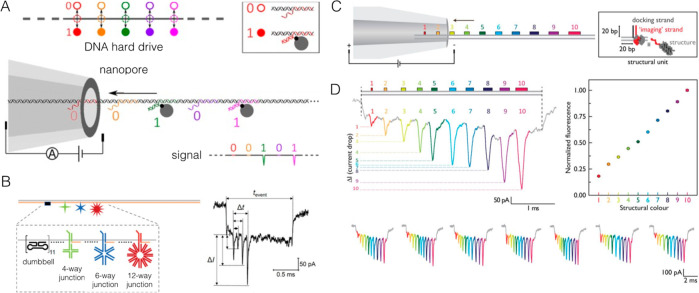
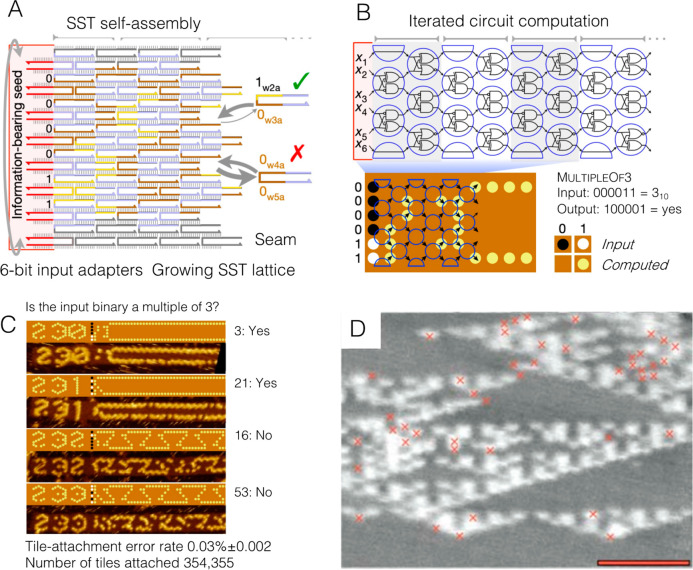
Comment in
-
Comment on "Emerging Approaches to DNA Data Storage: Challenges and Prospects".ACS Nano. 2022 Dec 27;16(12):19612-19613. doi: 10.1021/acsnano.2c11397. ACS Nano. 2022. PMID: 36598758 No abstract available.
References
-
- Gu M.; Li X.; Cao Y. Optical Storage Arrays: A Perspective for Future Big Data Storage. Light Sci. Appl. 2014, 3 (5), e177. 10.1038/lsa.2014.58. - DOI
-
- Carmean D.; Ceze L.; Seelig G.; Stewart K.; Strauss K.; Willsey M. DNA Data Storage and Hybrid Molecular-Electronic Computing. Proceedings of the IEEE 2019, 107 (1), 63–72. 10.1109/JPROC.2018.2875386. - DOI
-
- Dabney J.; Knapp M.; Glocke I.; Gansauge M. T.; Weihmann A.; Nickel B.; Valdiosera C.; García N.; Pääbo S.; Arsuaga J. L.; Meyer M. Complete Mitochondrial Genome Sequence of a Middle Pleistocene Cave Bear Reconstructed from Ultrashort DNA Fragments. Proc. Natl. Acad. Sci. U. S. A. 2013, 110 (39), 15758–15763. 10.1073/pnas.1314445110. - DOI - PMC - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials
Miscellaneous
