

Technology readiness levels for machine learning systems
- PMID: 36266298
- PMCID: PMC9585100
- DOI: 10.1038/s41467-022-33128-9
Technology readiness levels for machine learning systems
Abstract
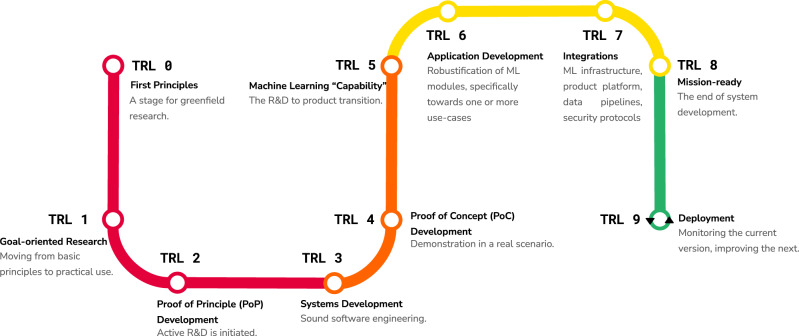
The development and deployment of machine learning systems can be executed easily with modern tools, but the process is typically rushed and means-to-an-end. Lack of diligence can lead to technical debt, scope creep and misaligned objectives, model misuse and failures, and expensive consequences. Engineering systems, on the other hand, follow well-defined processes and testing standards to streamline development for high-quality, reliable results. The extreme is spacecraft systems, with mission critical measures and robustness throughout the process. Drawing on experience in both spacecraft engineering and machine learning (research through product across domain areas), we've developed a proven systems engineering approach for machine learning and artificial intelligence: the Machine Learning Technology Readiness Levels framework defines a principled process to ensure robust, reliable, and responsible systems while being streamlined for machine learning workflows, including key distinctions from traditional software engineering, and a lingua franca for people across teams and organizations to work collaboratively on machine learning and artificial intelligence technologies. Here we describe the framework and elucidate with use-cases from physics research to computer vision apps to medical diagnostics.
© 2022. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures




References
-
- Henderson, P. et al. Deep reinforcement learning that matters. In Proc. AAAI Conference on Artificial Intelligence (2018).
-
- de la Tour, A., Portincaso, M., Blank, K. & Goeldel, N. The Dawn of the Deep Tech Ecosystem. Technical Report (The Boston Consulting Group, 2019).
-
- NASA. The NASA Systems Engineering Handbook (NASA, 2003).
-
- United States Department of Defense. Defense Acquisition Guidebook (U.S. Department of Defense, 2004).
-
- Leslie, D. Understanding artificial intelligence ethics and safety: A guide for the responsible design and implementation of AI systems in the public sector. The Alan Turing Institute. 10.5281/zenodo.3240529 (2019).
MeSH terms
LinkOut - more resources
Full Text Sources
