

Discovery of 42 genome-wide significant loci associated with dyslexia
- PMID: 36266505
- PMCID: PMC9649434
- DOI: 10.1038/s41588-022-01192-y
Discovery of 42 genome-wide significant loci associated with dyslexia
Erratum in
-
Author Correction: Discovery of 42 genome-wide significant loci associated with dyslexia.Nat Genet. 2023 Mar;55(3):520. doi: 10.1038/s41588-023-01336-8. Nat Genet. 2023. PMID: 36823321 Free PMC article. No abstract available.
Abstract
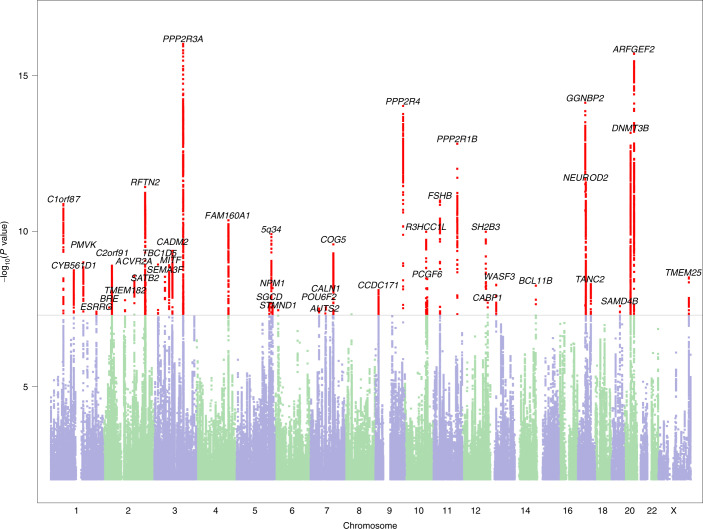
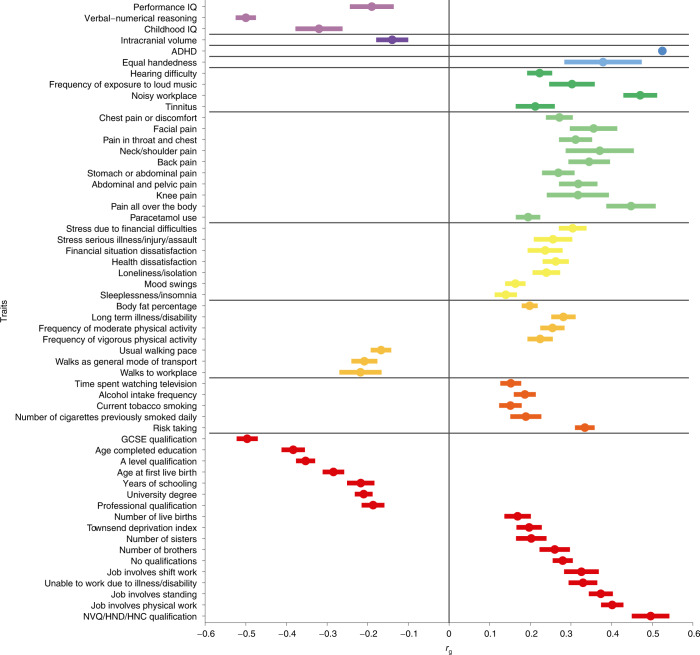
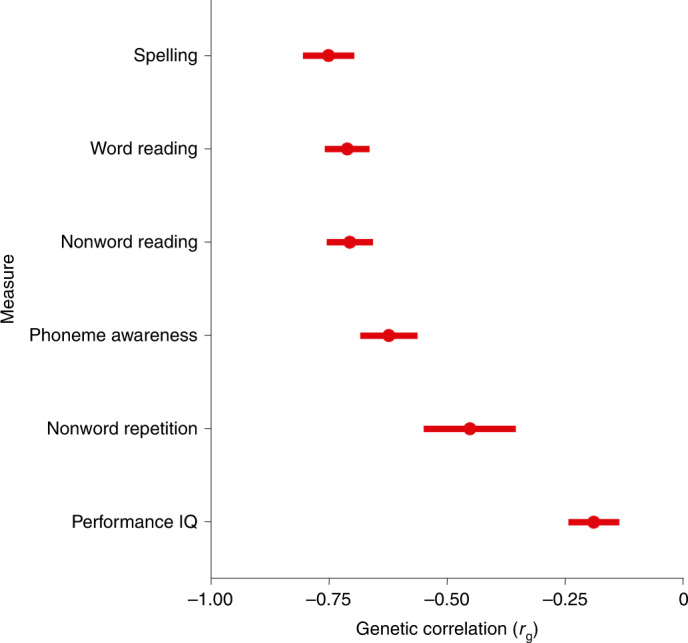
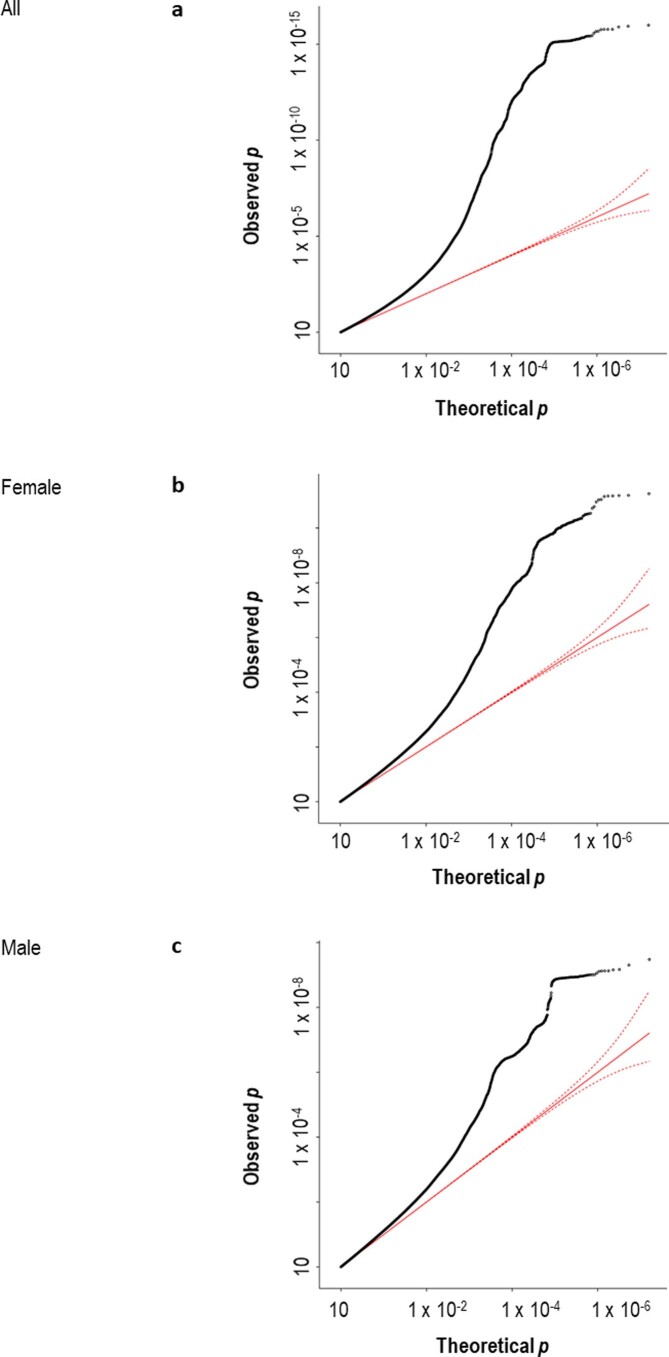
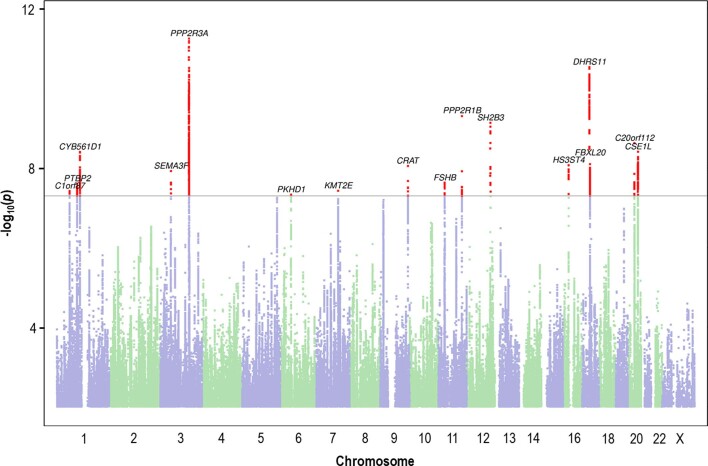
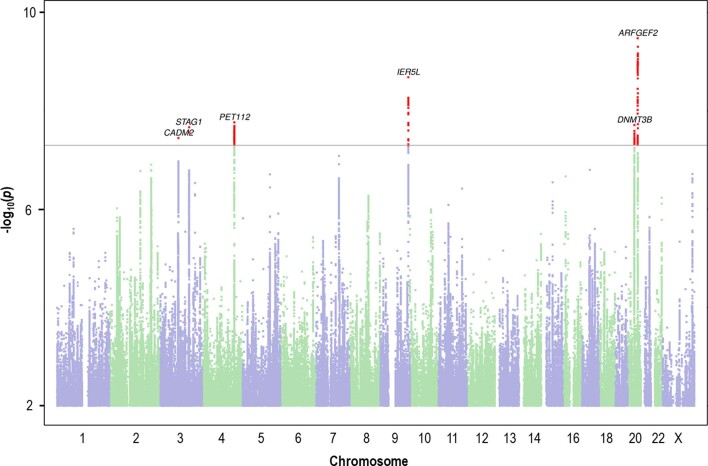
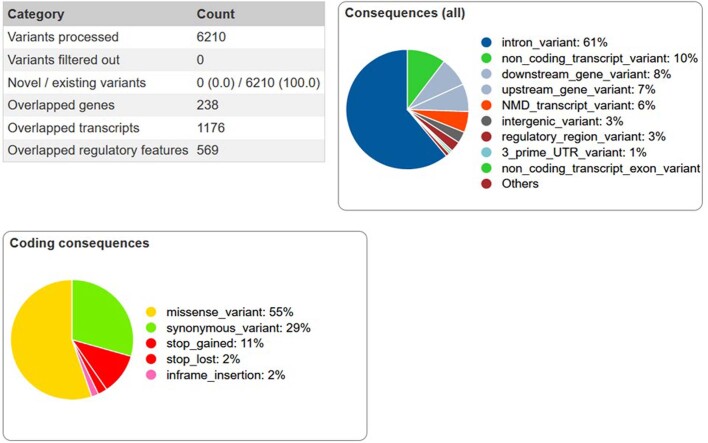
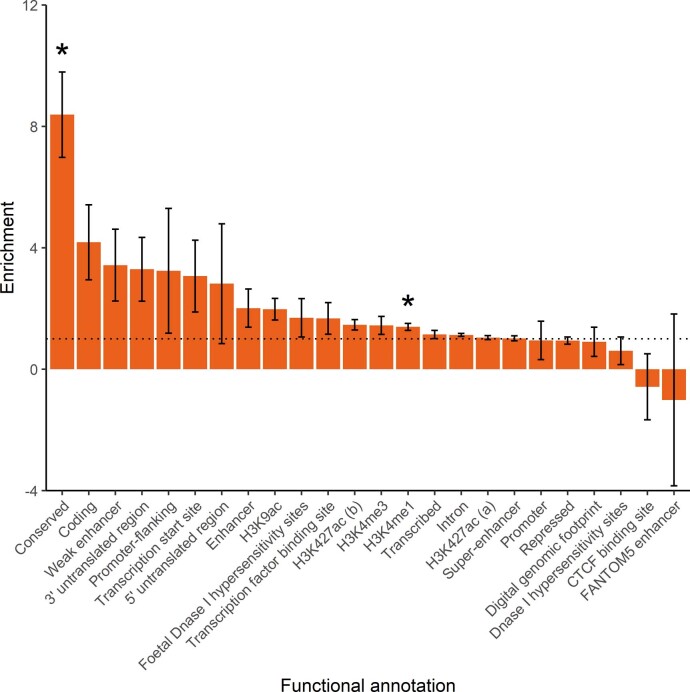
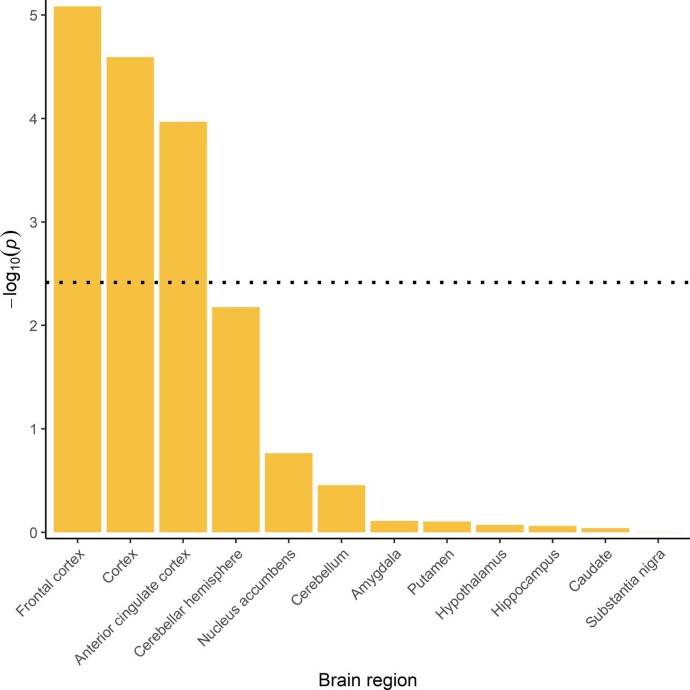
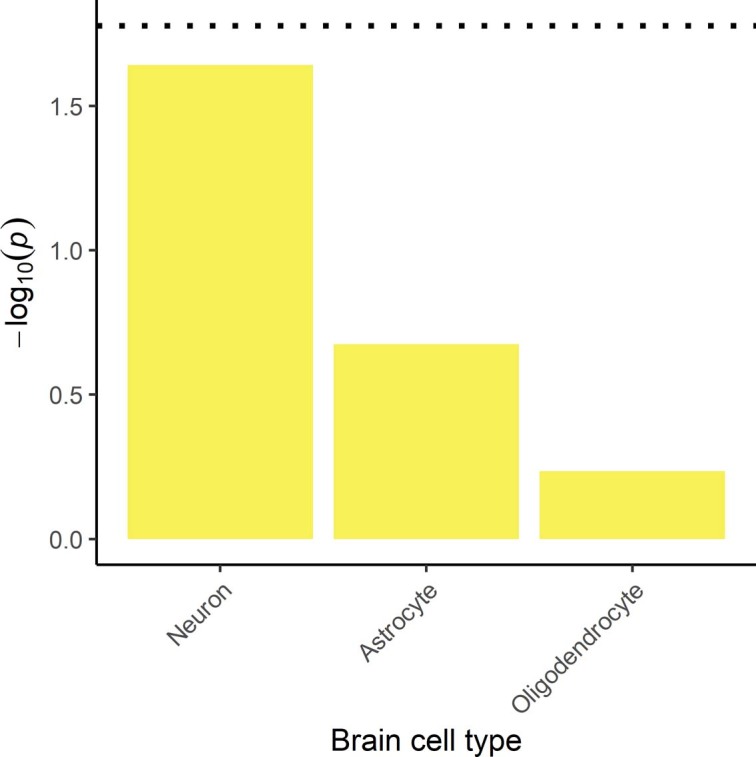
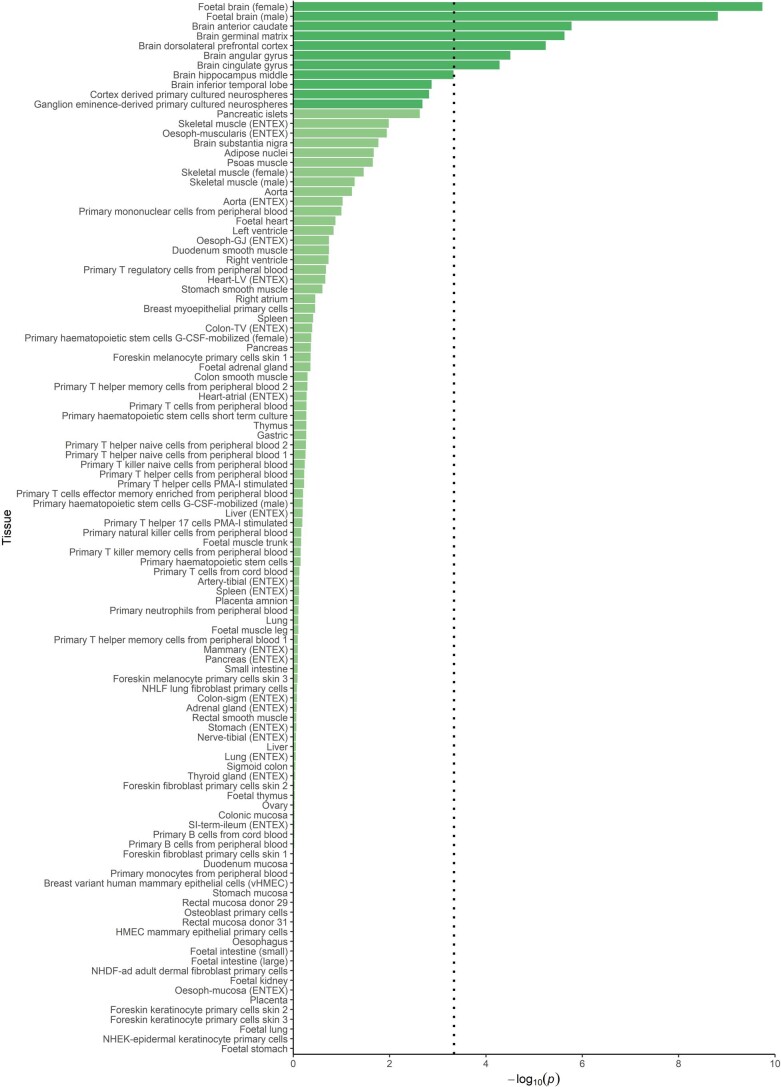
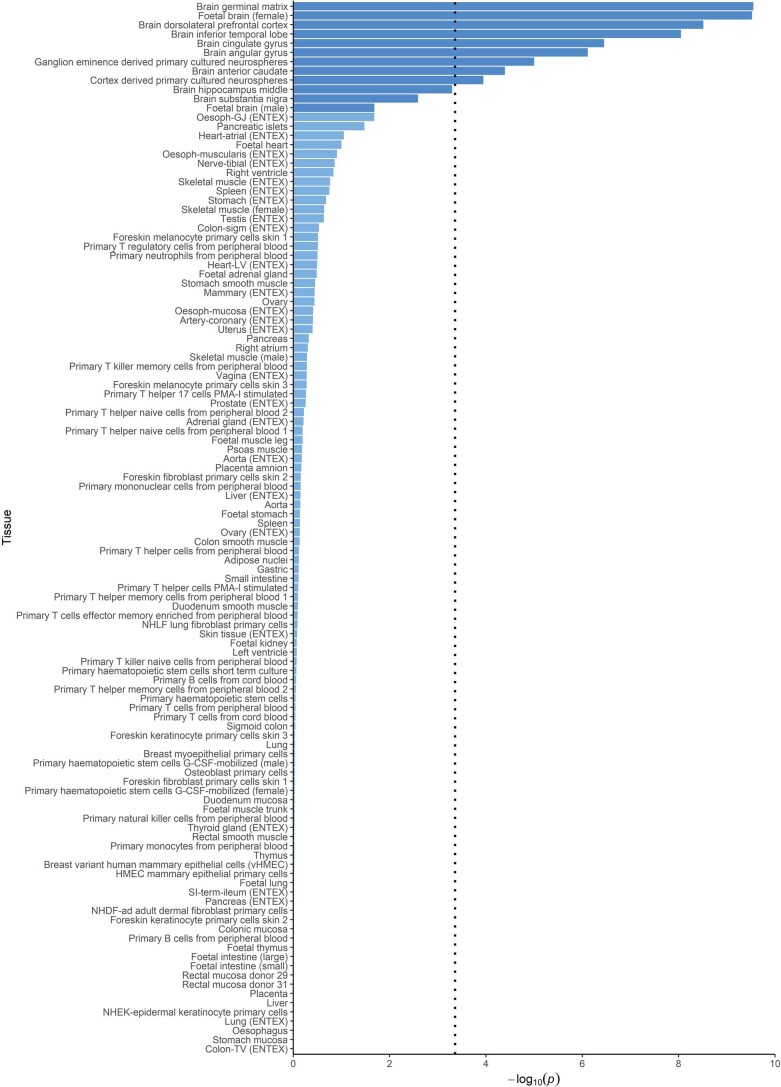
Reading and writing are crucial life skills but roughly one in ten children are affected by dyslexia, which can persist into adulthood. Family studies of dyslexia suggest heritability up to 70%, yet few convincing genetic markers have been found. Here we performed a genome-wide association study of 51,800 adults self-reporting a dyslexia diagnosis and 1,087,070 controls and identified 42 independent genome-wide significant loci: 15 in genes linked to cognitive ability/educational attainment, and 27 new and potentially more specific to dyslexia. We validated 23 loci (13 new) in independent cohorts of Chinese and European ancestry. Genetic etiology of dyslexia was similar between sexes, and genetic covariance with many traits was found, including ambidexterity, but not neuroanatomical measures of language-related circuitry. Dyslexia polygenic scores explained up to 6% of variance in reading traits, and might in future contribute to earlier identification and remediation of dyslexia.
© 2022. The Author(s).
Conflict of interest statement
P.F., A.A. and the 23andMe Research Team are employed by and hold stock or stock options in 23andMe, Inc. The remaining authors declare no competing interests.
Figures
References
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
