

Experimentally validated memristive memory augmented neural network with efficient hashing and similarity search
- PMID: 36271072
- PMCID: PMC9587027
- DOI: 10.1038/s41467-022-33629-7
Experimentally validated memristive memory augmented neural network with efficient hashing and similarity search
Abstract
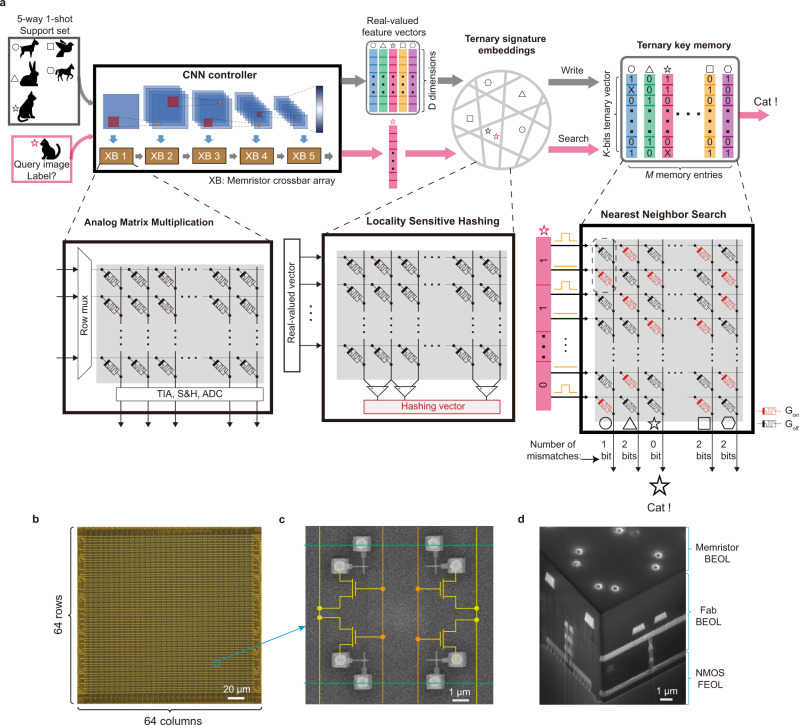
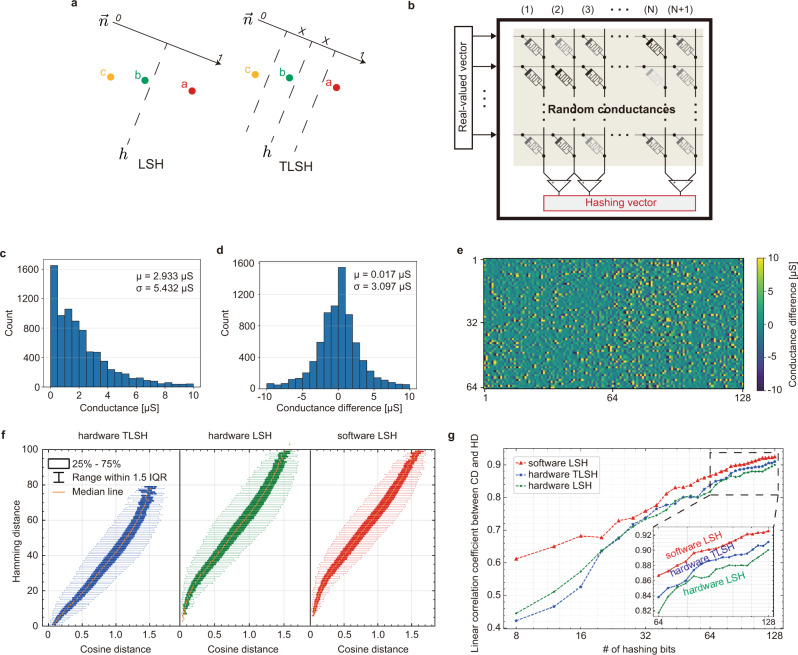
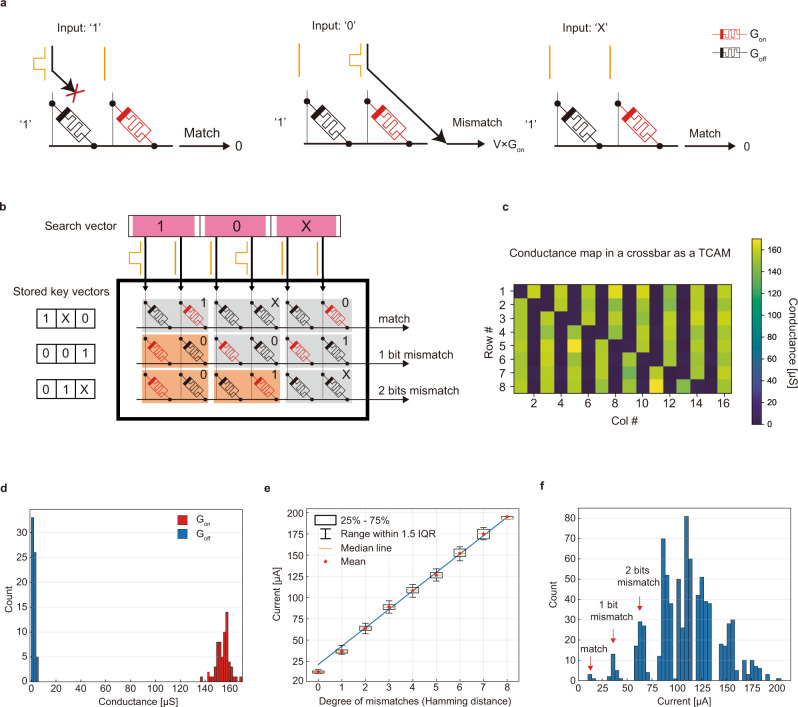
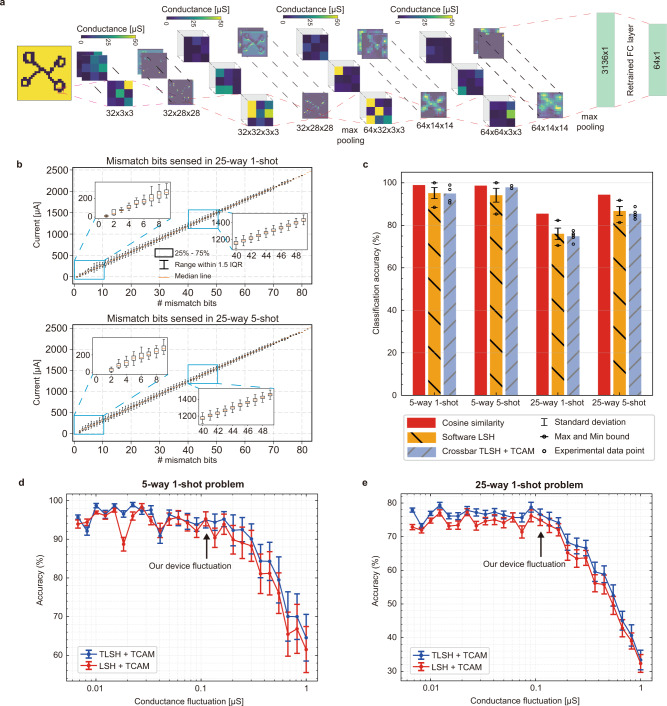
Lifelong on-device learning is a key challenge for machine intelligence, and this requires learning from few, often single, samples. Memory-augmented neural networks have been proposed to achieve the goal, but the memory module must be stored in off-chip memory, heavily limiting the practical use. In this work, we experimentally validated that all different structures in the memory-augmented neural network can be implemented in a fully integrated memristive crossbar platform with an accuracy that closely matches digital hardware. The successful demonstration is supported by implementing new functions in crossbars, including the crossbar-based content-addressable memory and locality sensitive hashing exploiting the intrinsic stochasticity of memristor devices. Simulations show that such an implementation can be efficiently scaled up for one-shot learning on more complex tasks. The successful demonstration paves the way for practical on-device lifelong learning and opens possibilities for novel attention-based algorithms that were not possible in conventional hardware.
© 2022. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures

References
-
- Santoro, A., Bartunov, S., Botvinick, M., Wierstra, D. & Lillicrap, T. Meta-learning with memory-augmented neural networks. In Balcan, M. F. & Weinberger, K. Q. (eds.) Proceedings of The 33rd International Conference on Machine Learning, vol. 48 of Proceedings of Machine Learning Research, 1842-1850 (PMLR, New York, New York, USA, 2016). http://proceedings.mlr.press/v48/santoro16.html.
-
- Stevens, J. R., Ranjan, A., Das, D., Kaul, B. & Raghunathan, A. Manna: An accelerator for memory-augmented neural networks. In Proceedings of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture, 794-806 (2019).
-
- Rae, J. W. et al. Scaling memory-augmented neural networks with sparse reads and writes (2016). 1610.09027.
-
- Von Neumann J. First draft of a report on the edvac. IEEE Annals Hist. Comput. 1993;15:27–75. doi: 10.1109/85.238389. - DOI
-
- Strubell, E., Ganesh, A. & McCallum, A. Energy and policy considerations for deep learning in NLP. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 3645-3650 (Association for Computational Linguistics, Florence, Italy, 2019). https://www.aclweb.org/anthology/P19-1355.
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
