

Camera Motion Agnostic Method for Estimating 3D Human Poses
- PMID: 36298324
- PMCID: PMC9607787
- DOI: 10.3390/s22207975
Camera Motion Agnostic Method for Estimating 3D Human Poses
Abstract
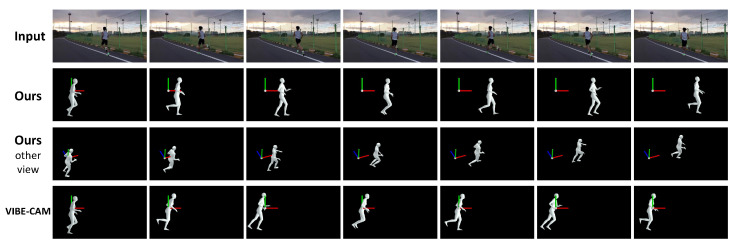
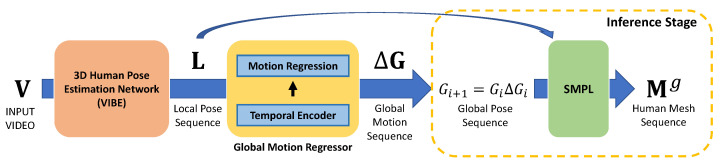
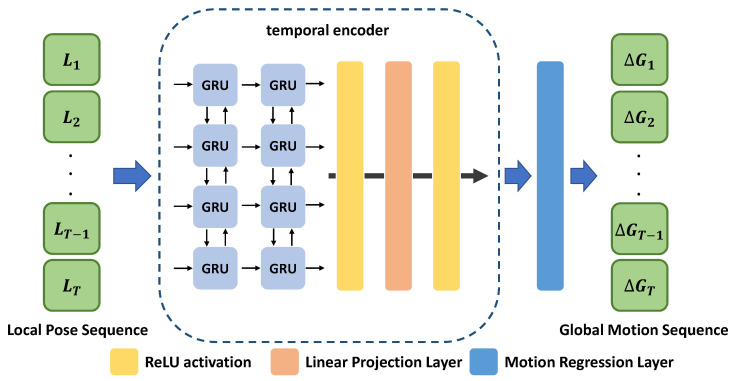
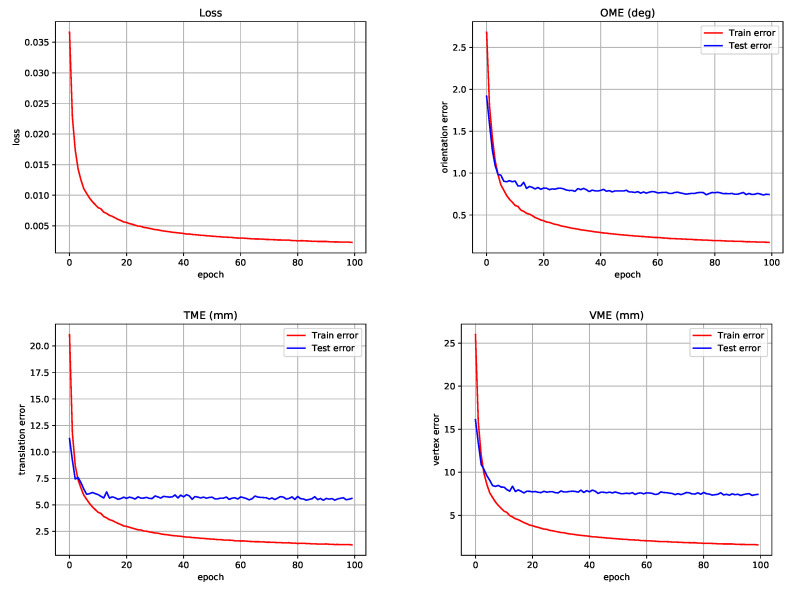
Although the performance of 3D human pose and shape estimation methods has improved considerably in recent years, existing approaches typically generate 3D poses defined in a camera or human-centered coordinate system. This makes it difficult to estimate a person's pure pose and motion in a world coordinate system for a video captured using a moving camera. To address this issue, this paper presents a camera motion agnostic approach for predicting 3D human pose and mesh defined in the world coordinate system. The core idea of the proposed approach is to estimate the difference between two adjacent global poses (i.e., global motion) that is invariant to selecting the coordinate system, instead of the global pose coupled to the camera motion. To this end, we propose a network based on bidirectional gated recurrent units (GRUs) that predicts the global motion sequence from the local pose sequence consisting of relative rotations of joints called global motion regressor (GMR). We use 3DPW and synthetic datasets, which are constructed in a moving-camera environment, for evaluation. We conduct extensive experiments and prove the effectiveness of the proposed method empirically.
Keywords: 3D human pose estimation; 3D human shape reconstruction; statistical shape model.
Conflict of interest statement
The authors declare no conflict of interest.
Figures



References
-
- Huang Y., Bogo F., Lassner C., Kanazawa A., Gehler P.V., Romero J., Akhter I., Black M.J. Towards accurate marker-less human shape and pose estimation over time; Proceedings of the International Conference on 3D Vision (3DV); Qingdao, China. 10–12 October 2017.
-
- Pavlakos G., Zhou X., Derpanis K.G., Daniilidis K. Coarse-to-fine volumetric prediction for single-image 3D human pose; Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR); Honolulu, HI, USA. 21–26 July 2017.
-
- Martinez J., Hossain R., Romero J., Little J.J. A simple yet effective baseline for 3d human pose estimation; Proceedings of the IEEE International Conference on Computer Vision (ICCV); Venice, Italy. 22–29 October 2017.
-
- Pavllo D., Feichtenhofer C., Grangier D., Auli M. 3D human pose estimation in video with temporal convolutions and semi-supervised training; Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR); Long Beach, CA, USA. 15–20 June 2019.
-
- Kanazawa A., Black M.J., Jacobs D.W., Malik J. End-to-end recovery of human shape and pose; Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR); Salt Lake City, UT, USA. 18–23 June 2018.
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Medical
Research Materials
