

Contrast independent biologically inspired translational optic flow estimation
- PMID: 36303043
- PMCID: PMC9691503
- DOI: 10.1007/s00422-022-00948-3
Contrast independent biologically inspired translational optic flow estimation
Abstract
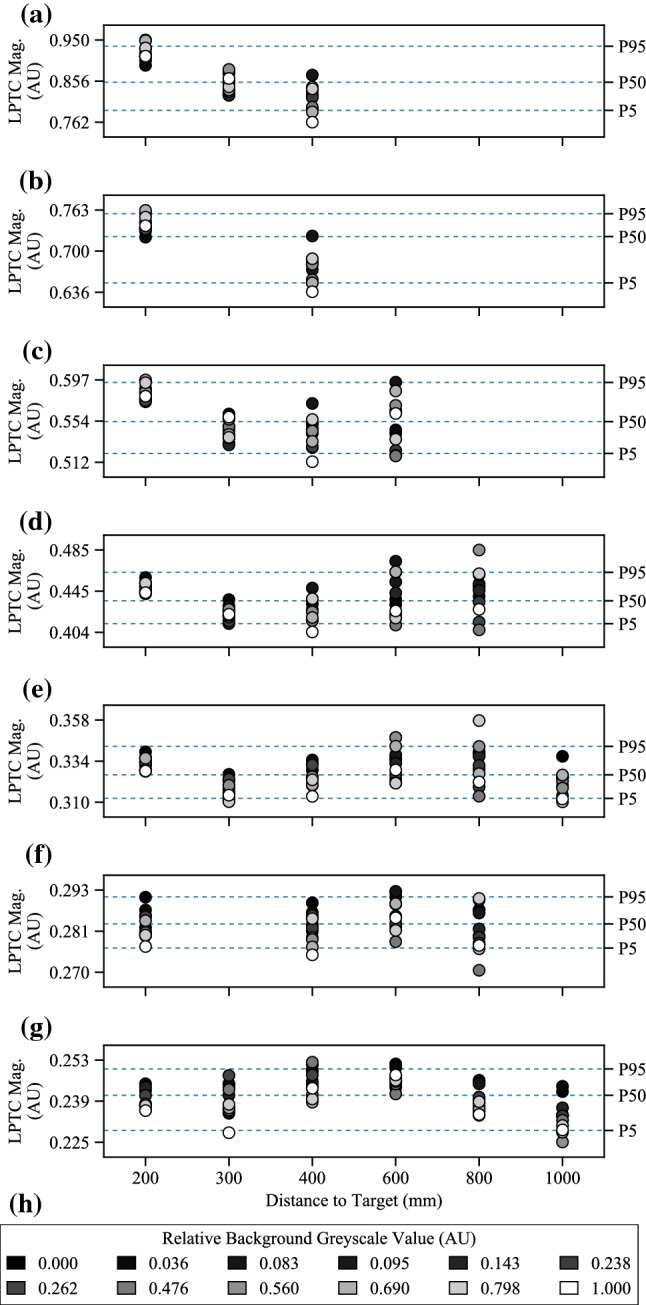
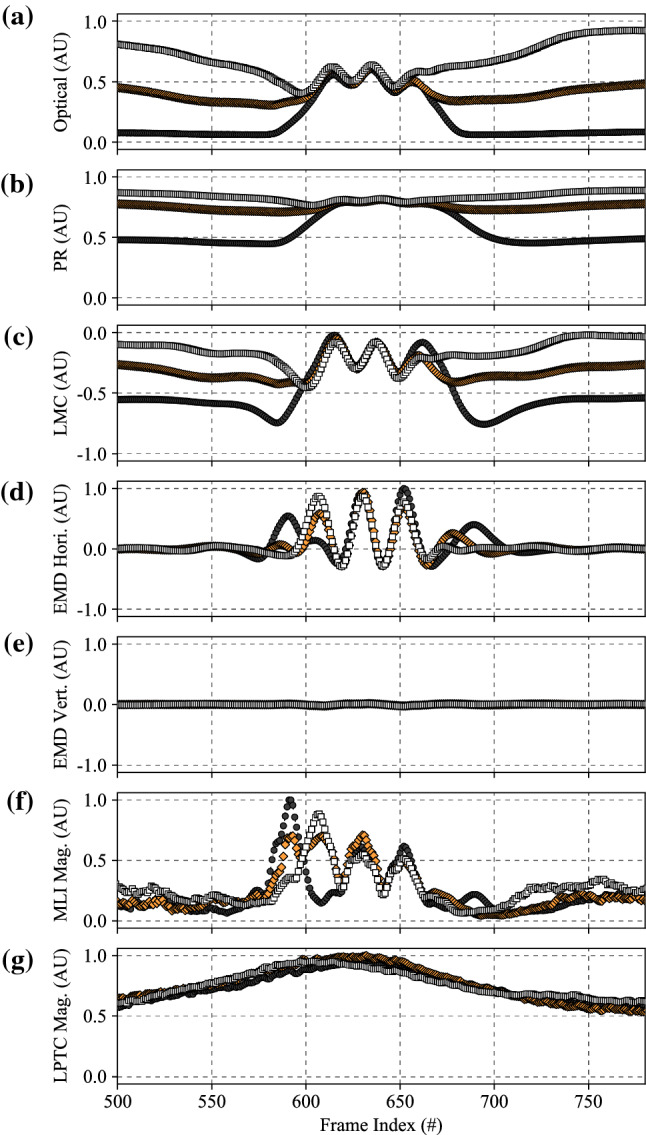
The visual systems of insects are relatively simple compared to humans. However, they enable navigation through complex environments where insects perform exceptional levels of obstacle avoidance. Biology uses two separable modes of optic flow to achieve this: rapid gaze fixation (rotational motion known as saccades); and the inter-saccadic translational motion. While the fundamental process of insect optic flow has been known since the 1950's, so too has its dependence on contrast. The surrounding visual pathways used to overcome environmental dependencies are less well known. Previous work has shown promise for low-speed rotational motion estimation, but a gap remained in the estimation of translational motion, in particular the estimation of the time to impact. To consistently estimate the time to impact during inter-saccadic translatory motion, the fundamental limitation of contrast dependence must be overcome. By adapting an elaborated rotational velocity estimator from literature to work for translational motion, this paper proposes a novel algorithm for overcoming the contrast dependence of time to impact estimation using nonlinear spatio-temporal feedforward filtering. By applying bioinspired processes, approximately 15 points per decade of statistical discrimination were achieved when estimating the time to impact to a target across 360 background, distance, and velocity combinations: a 17-fold increase over the fundamental process. These results show the contrast dependence of time to impact estimation can be overcome in a biologically plausible manner. This, combined with previous results for low-speed rotational motion estimation, allows for contrast invariant computational models designed on the principles found in the biological visual system, paving the way for future visually guided systems.
Keywords: Bioinspired; Computer vision; Contrast dependence; Optical flow; Robotics; Time to impact.
© 2022. The Author(s).
Figures
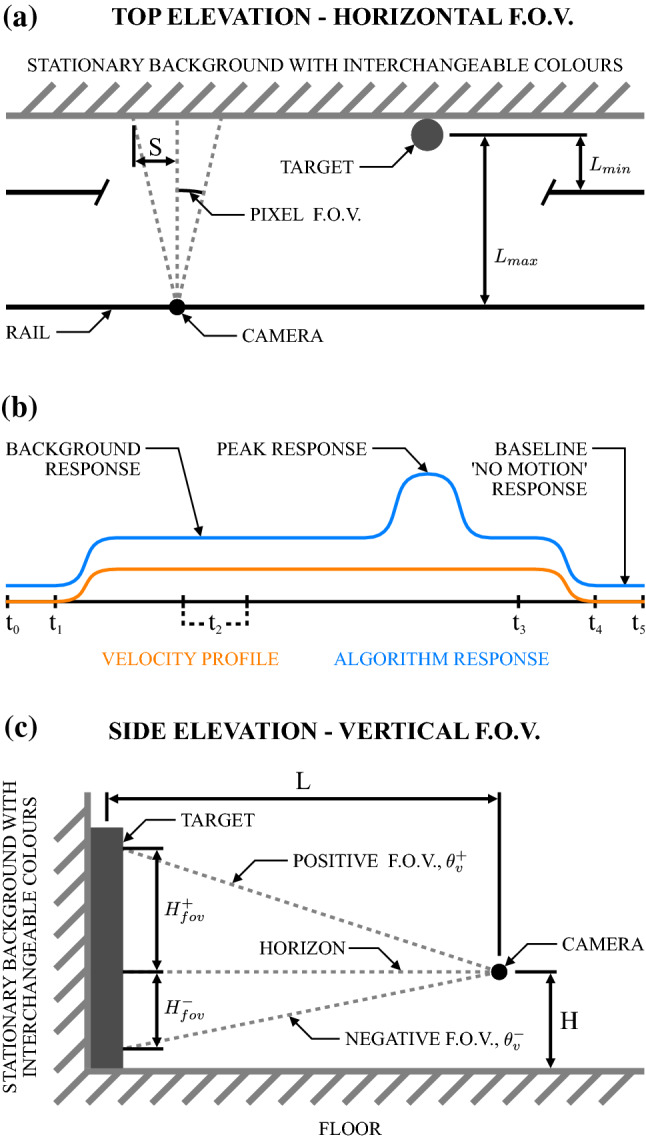

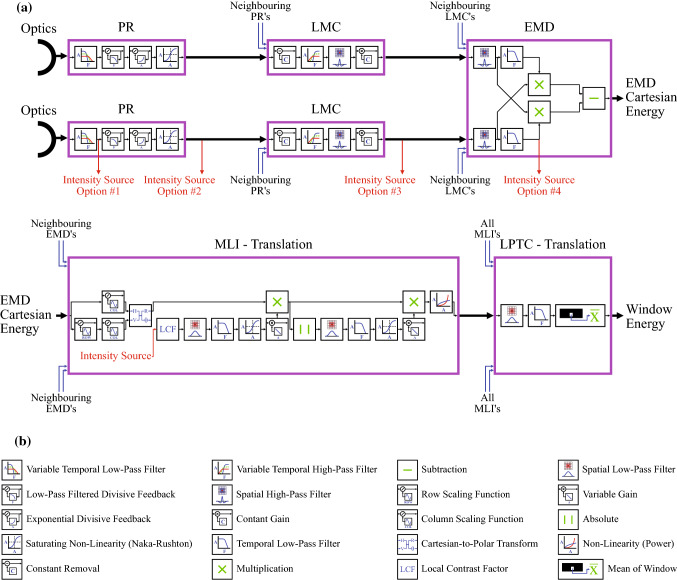




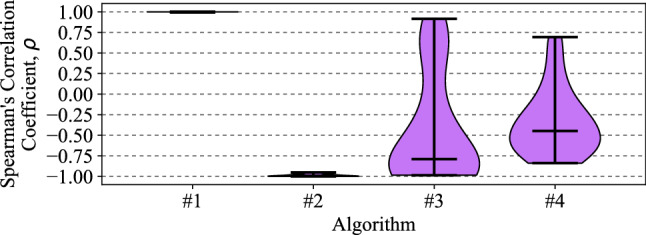
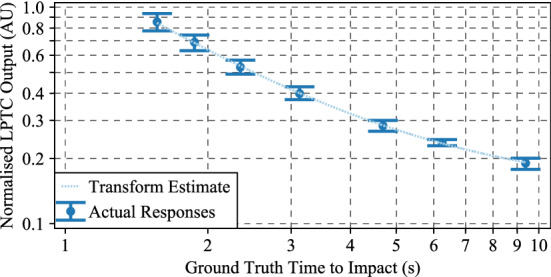


References
-
- Barth FG, Humphrey JA, Srinivasan MV. Frontiers in sensing: from biology to engineering. Amsterdam: Springer Science & Business Media; 2012.
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Miscellaneous
