

A Machine Learning Framework Predicts the Clinical Severity of Hemophilia B Caused by Point-Mutations
- PMID: 36304295
- PMCID: PMC9580853
- DOI: 10.3389/fbinf.2022.912112
A Machine Learning Framework Predicts the Clinical Severity of Hemophilia B Caused by Point-Mutations
Abstract
Blood coagulation is a vital physiological mechanism to stop blood loss following an injury to a blood vessel. This process starts immediately upon damage to the endothelium lining a blood vessel, and results in the formation of a platelet plug that closes the site of injury. In this repair operation, an essential component is the coagulation factor IX (FIX), a serine protease encoded by the F9 gene and whose deficiency causes hemophilia B. If not treated by prophylaxis or gene therapy, patients with this condition are at risk of life-threatening bleeding episodes. In this sense, a deep understanding of the FIX protein and its activated form (FIXa) is essential to develop efficient therapeutics. In this study, we used well-studied structural analysis techniques to create a residue interaction network of the FIXa protein. Here, the nodes are the amino acids of FIXa, and two nodes are connected by an edge if the two residues are in close proximity in the FIXa 3D structure. This representation accurately captured fundamental properties of each amino acid of the FIXa structure, as we found by validating our findings against hundreds of clinical reports about the severity of HB. Finally, we established a machine learning framework named HemB-Class to predict the effect of mutations of all FIXa residues to all other amino acids and used it to disambiguate several conflicting medical reports. Together, these methods provide a comprehensive map of the FIXa protein architecture and establish a robust platform for the rational design of FIX therapeutics.
Keywords: FIX; FIXa; bioinformatics; hemophilia B; machine learning; protein structure; residue network.
Copyright © 2022 Lopes, Nogueira and Rios.
Conflict of interest statement
TL received consulting fees from Pola Chemical Industries, Japan, and speaker honoraria from Sanofi Japan. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Figures
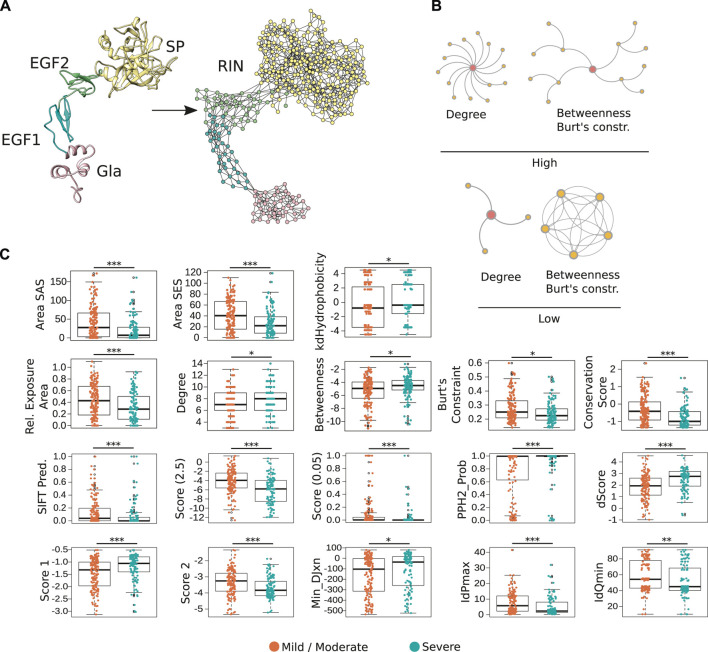
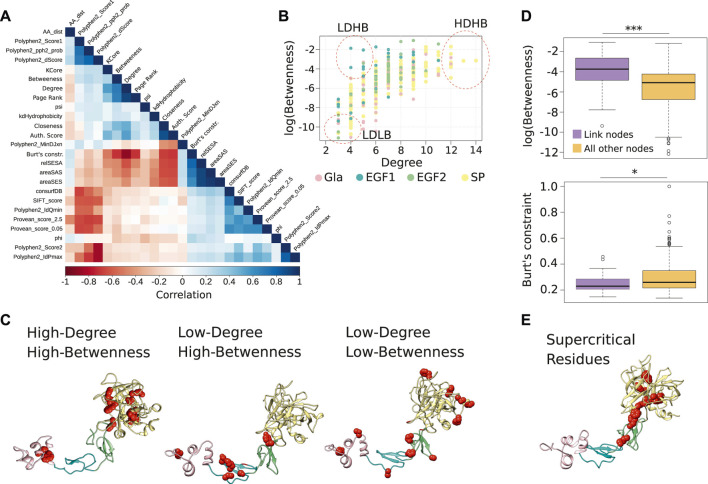
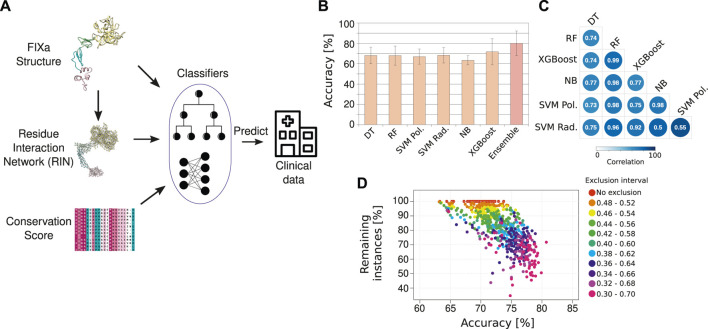
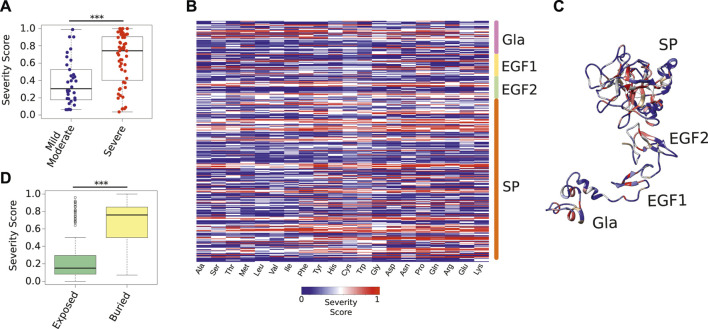
References
-
- Bajaj S. P., Rapaport S. I., Russell W. A. (1983). Redetermination of the Rate-Limiting Step in the Activation of Factor IX by Factor XIa and by Factor VIIa/Tissue Factor. Explanation for Different Electrophoretic Radioactivity Profiles Obtained on Activation of 3H- and 125I-Labeled Factor IX. Biochemistry 22 (17), 4047–4053. 10.1021/bi00286a009 - DOI - PubMed
-
- Bajaj S. P., Schmidt A. E., Mathur A., Padmanabhan K., Zhong D., Mastri M., et al. (2001). Factor IXa:factor VIIIa Interaction. Helix 330-338 of Factor Ixa Interacts with Residues 558-565 and Spatially Adjacent Regions of the A2 Subunit of Factor VIIIa. J. Biol. Chem. 276 (19), 16302–16309. 10.1074/jbc.M011680200 - DOI - PubMed
LinkOut - more resources
Full Text Sources
Miscellaneous