

DNA read count calibration for single-molecule, long-read sequencing
- PMID: 36319642
- PMCID: PMC9626564
- DOI: 10.1038/s41598-022-21606-5
DNA read count calibration for single-molecule, long-read sequencing
Abstract
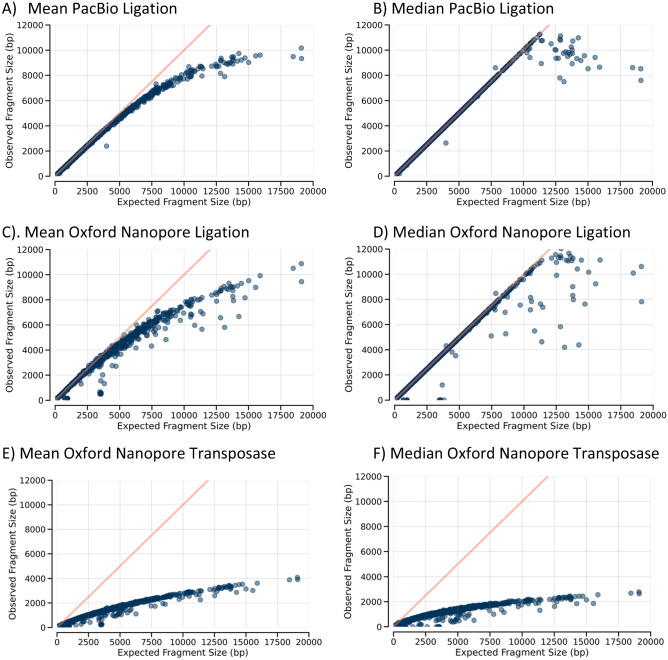
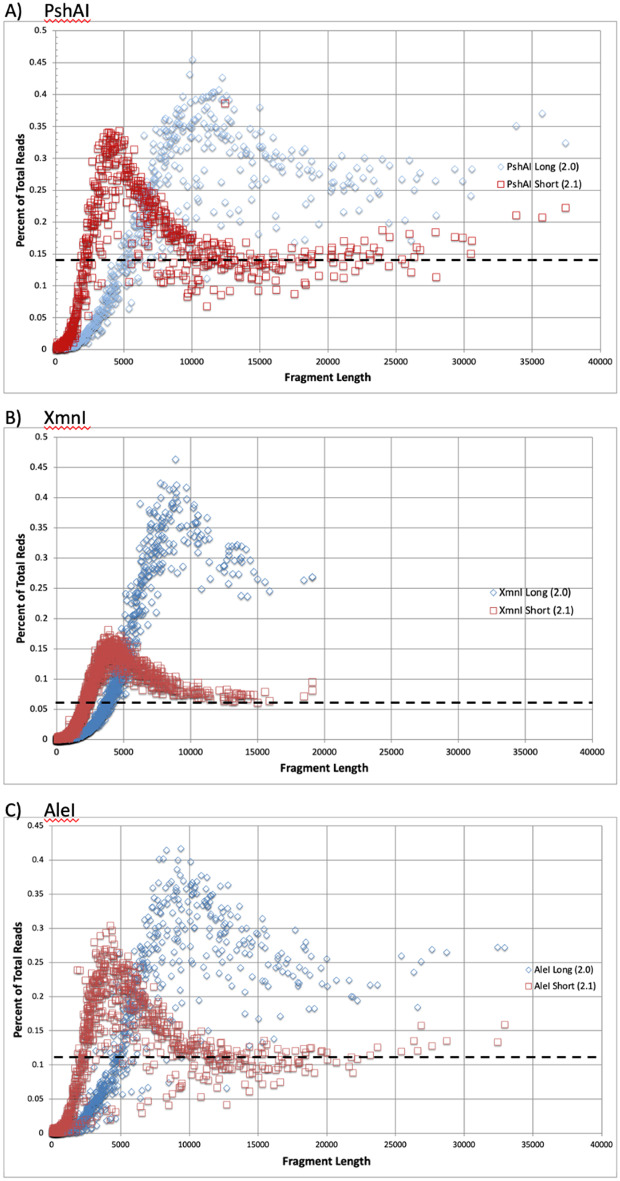
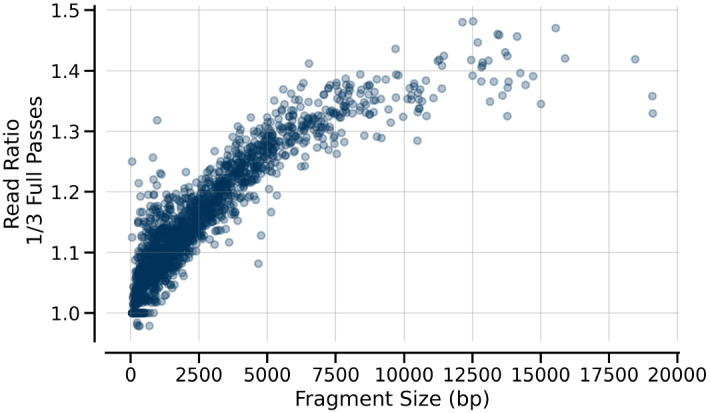
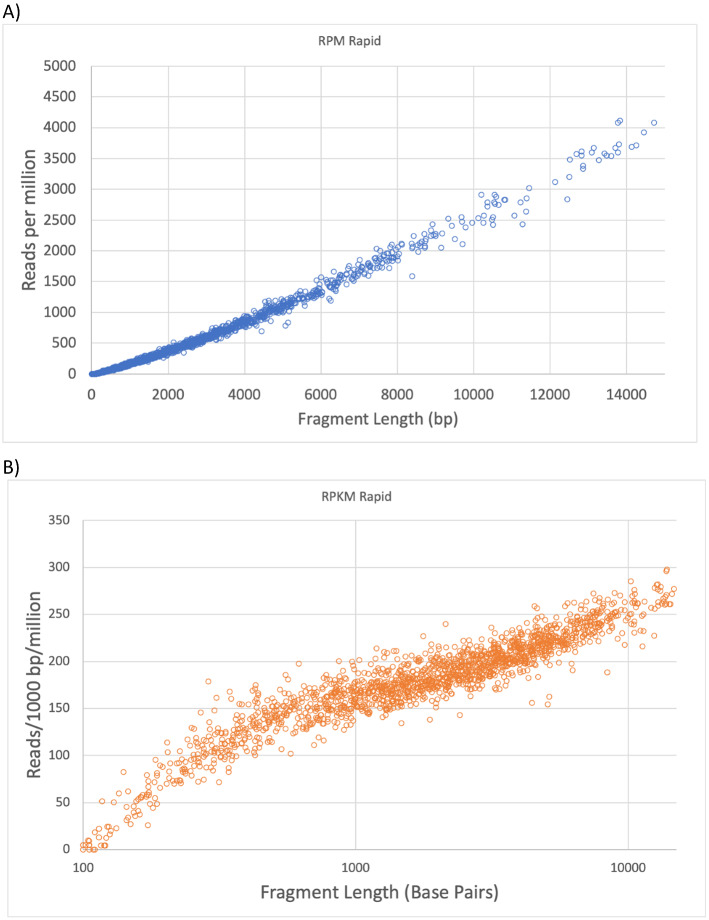
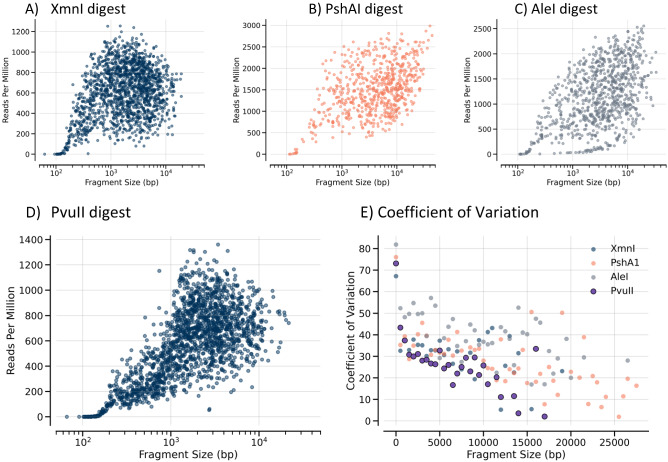
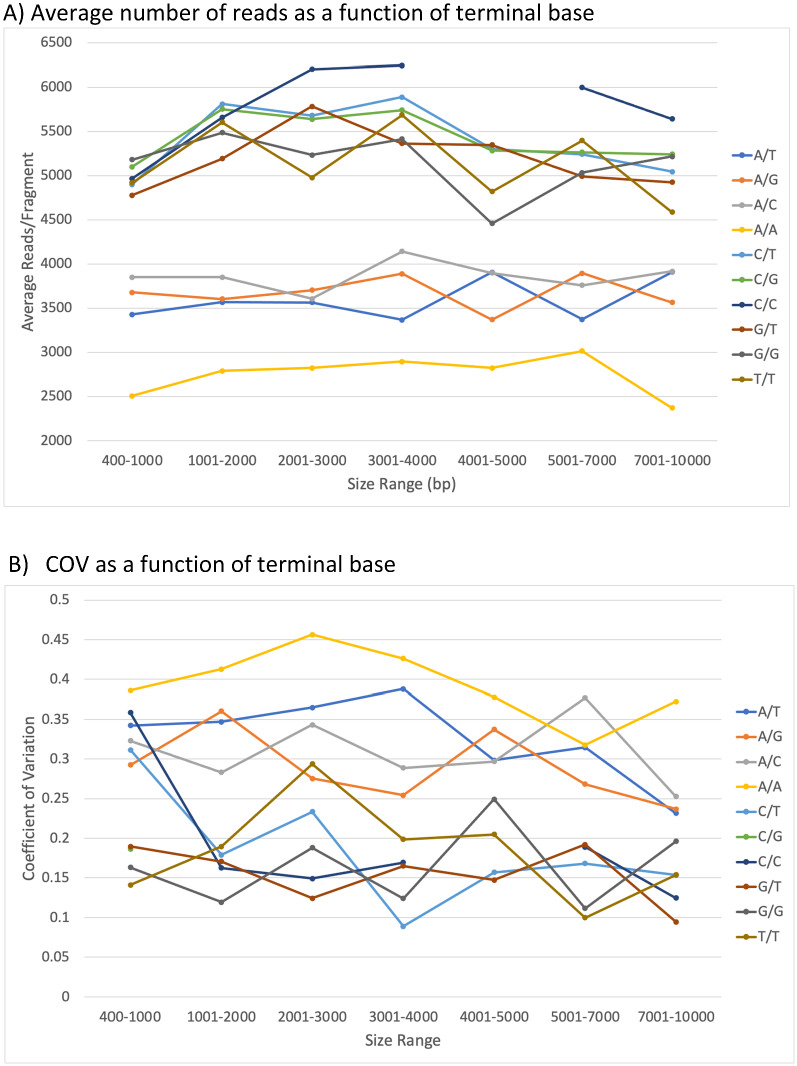
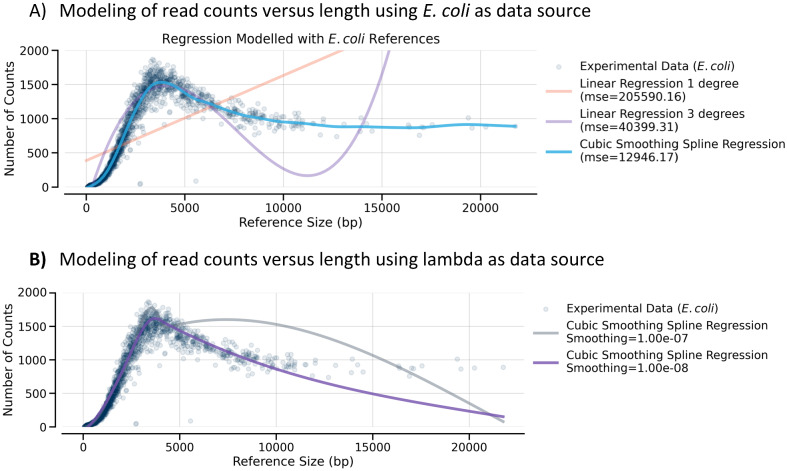
There are many applications in which quantitative information about DNA mixtures with different molecular lengths is important. Gene therapy vectors are much longer than can be sequenced individually via short-read NGS. However, vector preparations may contain smaller DNAs that behave differently during sequencing. We have used two library preparations each for Pacific Biosystems (PacBio) and Oxford Nanopore Technologies NGS to determine their suitability for quantitative assessment of varying sized DNAs. Equimolar length standards were generated from E. coli genomic DNA. Both PacBio library preparations provided a consistent length dependence though with a complex pattern. This method is sufficiently sensitive that differences in genomic copy number between DNA from E. coli grown in exponential and stationary phase conditions could be detected. The transposase-based Oxford Nanopore library preparation provided a predictable length dependence, but the random sequence starts caused the loss of original length information. The ligation-based approach retained length information but read frequency was more variable. Modeling of E. coli versus lambda read frequency via cubic spline smoothing showed that the shorter genome could be used as a suitable internal spike-in for DNAs in the 200 bp to 10 kb range, allowing meaningful QC to be carried out with AAV preparations.
© 2022. The Author(s).
Conflict of interest statement
All authors are current or former employees of Homology Medicines Inc.
Figures


References
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
