

Improved Fine-Tuning of In-Domain Transformer Model for Inferring COVID-19 Presence in Multi-Institutional Radiology Reports
- PMID: 36323915
- PMCID: PMC9629758
- DOI: 10.1007/s10278-022-00714-8
Improved Fine-Tuning of In-Domain Transformer Model for Inferring COVID-19 Presence in Multi-Institutional Radiology Reports
Abstract
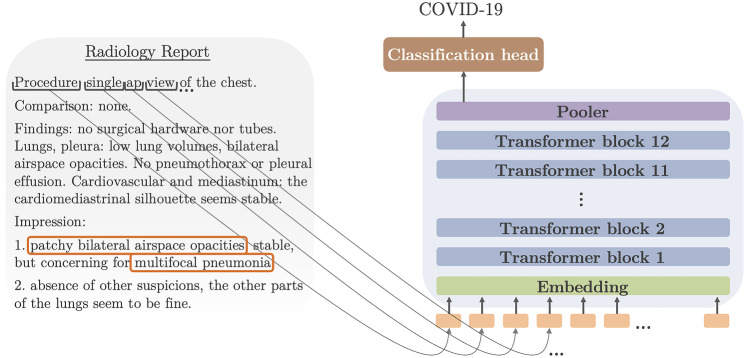
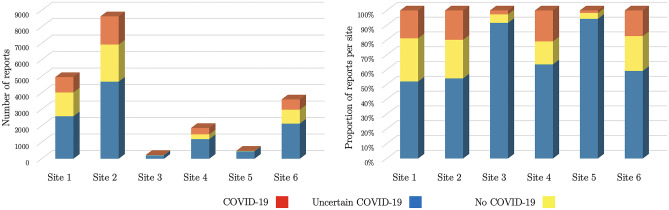
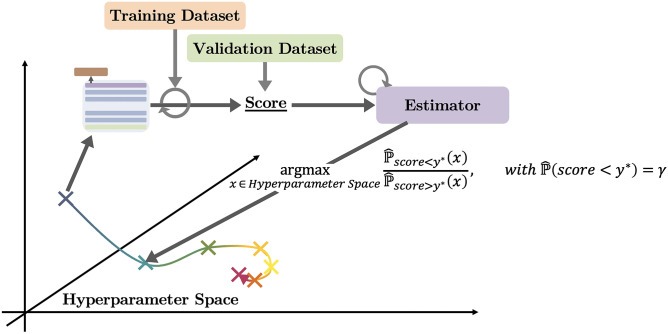
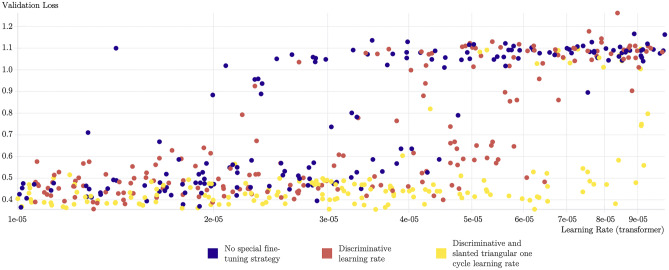
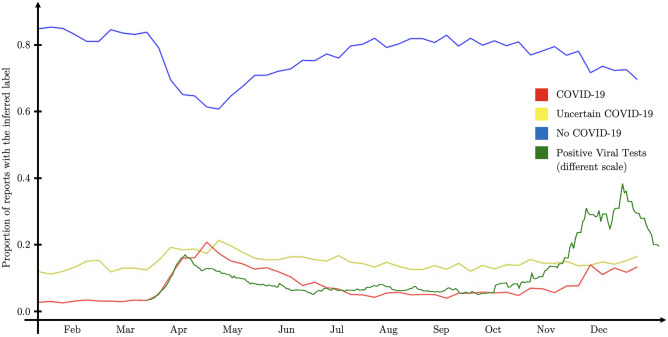
Building a document-level classifier for COVID-19 on radiology reports could help assist providers in their daily clinical routine, as well as create large numbers of labels for computer vision models. We have developed such a classifier by fine-tuning a BERT-like model initialized from RadBERT, its continuous pre-training on radiology reports that can be used on all radiology-related tasks. RadBERT outperforms all biomedical pre-trainings on this COVID-19 task (P<0.01) and helps our fine-tuned model achieve an 88.9 macro-averaged F1-score, when evaluated on both X-ray and CT reports. To build this model, we rely on a multi-institutional dataset re-sampled and enriched with concurrent lung diseases, helping the model to resist to distribution shifts. In addition, we explore a variety of fine-tuning and hyperparameter optimization techniques that accelerate fine-tuning convergence, stabilize performance, and improve accuracy, especially when data or computational resources are limited. Finally, we provide a set of visualization tools and explainability methods to better understand the performance of the model, and support its practical use in the clinical setting. Our approach offers a ready-to-use COVID-19 classifier and can be applied similarly to other radiology report classification tasks.
Keywords: BERT; COVID-19; Classification; Natural language processing (NLP); Radiology; Transformer.
© 2022. The Author(s) under exclusive licence to Society for Imaging Informatics in Medicine.
Conflict of interest statement
Personal financial interests: Board of directors and shareholder, Bunkerhill Health; Option holder, whiterabbit.ai; Advisor and option holder, GalileoCDS; Advisor and option holder, Sirona Medical; Advisor and option holder, Adra; Advisor and option holder, Kheiron; Advisor, Sixth Street; Chair, SIIM Board of Directors; Member at Large, Board of Directors of the Pennsylvania Radiological Society; Member at Large, Board of Directors of the Philadelphia Roentgen Ray Society; Member at Large, Board of Directors of the Association of University Radiologists (term just ended in June); Honoraria, Sectra (webinars); Honoraria, British Journal of Radiology (section editor); Speaker honorarium, Icahn School of Medicine (conference speaker); Speaker honorarium, MGH (conference speaker). Recent grant and gift support paid to academic institutions involved: Carestream; Clairity; GE Healthcare; Google Cloud; IBM; IDEXX; Hospital Israelita Albert Einstein; Kheiron; Lambda; Lunit; Microsoft; Nightingale Open Science; Nines; Philips; Subtle Medical; VinBrain; Whiterabbit.ai; Lowenstein Foundation; Gordon and Betty Moore Foundation; Paustenbach Fund. Grant funding: NIH; Independence Blue Cross; RSNA.
Figures

Similar articles
-
Automatic text classification of actionable radiology reports of tinnitus patients using bidirectional encoder representations from transformer (BERT) and in-domain pre-training (IDPT).BMC Med Inform Decis Mak. 2022 Jul 30;22(1):200. doi: 10.1186/s12911-022-01946-y. BMC Med Inform Decis Mak. 2022. PMID: 35907966 Free PMC article.
-
RadBERT: Adapting Transformer-based Language Models to Radiology.Radiol Artif Intell. 2022 Jun 15;4(4):e210258. doi: 10.1148/ryai.210258. eCollection 2022 Jul. Radiol Artif Intell. 2022. PMID: 35923376 Free PMC article.
-
Transformer versus traditional natural language processing: how much data is enough for automated radiology report classification?Br J Radiol. 2023 Sep;96(1149):20220769. doi: 10.1259/bjr.20220769. Epub 2023 May 25. Br J Radiol. 2023. PMID: 37162253 Free PMC article.
-
Natural Language Processing in Radiology: Update on Clinical Applications.J Am Coll Radiol. 2022 Nov;19(11):1271-1285. doi: 10.1016/j.jacr.2022.06.016. Epub 2022 Aug 25. J Am Coll Radiol. 2022. PMID: 36029890 Review.
-
Review of Natural Language Processing in Radiology.Neuroimaging Clin N Am. 2020 Nov;30(4):447-458. doi: 10.1016/j.nic.2020.08.001. Neuroimaging Clin N Am. 2020. PMID: 33038995 Review.
Cited by
-
Impact of hospital-specific domain adaptation on BERT-based models to classify neuroradiology reports.Eur Radiol. 2025 Sep;35(9):5299-5313. doi: 10.1007/s00330-025-11500-9. Epub 2025 Mar 17. Eur Radiol. 2025. PMID: 40097844 Free PMC article.
-
Evaluating acute image ordering for real-world patient cases via language model alignment with radiological guidelines.Commun Med (Lond). 2025 Aug 4;5(1):332. doi: 10.1038/s43856-025-01061-9. Commun Med (Lond). 2025. PMID: 40760099 Free PMC article.
-
A vision-language foundation model for the generation of realistic chest X-ray images.Nat Biomed Eng. 2025 Apr;9(4):494-506. doi: 10.1038/s41551-024-01246-y. Epub 2024 Aug 26. Nat Biomed Eng. 2025. PMID: 39187663 Free PMC article.
-
Automated deidentification of radiology reports combining transformer and "hide in plain sight" rule-based methods.J Am Med Inform Assoc. 2023 Jan 18;30(2):318-328. doi: 10.1093/jamia/ocac219. J Am Med Inform Assoc. 2023. PMID: 36416419 Free PMC article.
References
-
- Vaswani Ashish, Shazeer Noam, Parmar Niki, Uszkoreit Jakob. Llion Jones, Aidan N. Gomez: Lukasz Kaiser, and Illia Polosukhin. Attention is all you need; 2017.
-
- Devlin Jacob, Chang Ming-Wei, Lee Kenton. and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding; 2019.
-
- Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander Rush. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45, Online, October 2020. Association for Computational Linguistics. 10.18653/v1/2020.emnlp-demos.6. https://aclanthology.org/2020.emnlp-demos.6.
-
- Emily Alsentzer, John Murphy, William Boag, Wei-Hung Weng, Di Jindi, Tristan Naumann, and Matthew McDermott. Publicly available clinical BERT embeddings. In Proceedings of the 2nd Clinical Natural Language Processing Workshop, pages 72–78, Minneapolis, Minnesota, USA, June 2019. Association for Computational Linguistics. 10.18653/v1/W19-1909. https://aclanthology.org/W19-1909.
-
- Jinhyuk Lee, Wonjin Yoon, Sungdong Kim, Donghyeon Kim, Sunkyu Kim, Chan Ho So, and Jaewoo Kang. Biobert: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics, Sep 2019. ISSN 1460-2059. 10.1093/bioinformatics/btz682. 10.1093/bioinformatics/btz682. - DOI - PMC - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Medical
