

Representational ethical model calibration
- PMID: 36333390
- PMCID: PMC9636204
- DOI: 10.1038/s41746-022-00716-4
Representational ethical model calibration
Abstract
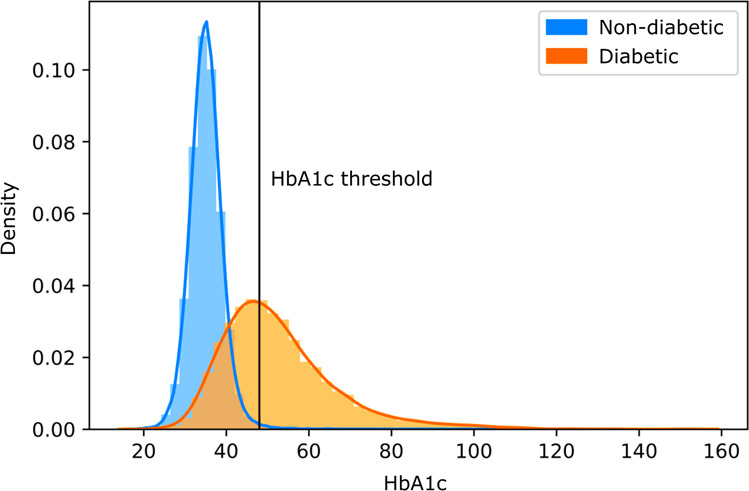
Equity is widely held to be fundamental to the ethics of healthcare. In the context of clinical decision-making, it rests on the comparative fidelity of the intelligence - evidence-based or intuitive - guiding the management of each individual patient. Though brought to recent attention by the individuating power of contemporary machine learning, such epistemic equity arises in the context of any decision guidance, whether traditional or innovative. Yet no general framework for its quantification, let alone assurance, currently exists. Here we formulate epistemic equity in terms of model fidelity evaluated over learnt multidimensional representations of identity crafted to maximise the captured diversity of the population, introducing a comprehensive framework for Representational Ethical Model Calibration. We demonstrate the use of the framework on large-scale multimodal data from UK Biobank to derive diverse representations of the population, quantify model performance, and institute responsive remediation. We offer our approach as a principled solution to quantifying and assuring epistemic equity in healthcare, with applications across the research, clinical, and regulatory domains.
© 2022. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures






References
-
- Sackett, D. L. Evidence-based medicine. In Seminars in perinatology, vol. 21, 3–5 (Elsevier, 1997). - PubMed
-
- Crisp, R. Aristotle: Nicomachean Ethics (Cambridge University Press, 2014).
-
- Health equity. https://www.who.int/health-topics/health-equity. Accessed: 2022-08-13.
Grants and funding
LinkOut - more resources
Full Text Sources
