

BLMM: Parallelised computing for big linear mixed models
- PMID: 36336314
- PMCID: PMC10985650
- DOI: 10.1016/j.neuroimage.2022.119729
BLMM: Parallelised computing for big linear mixed models
Abstract
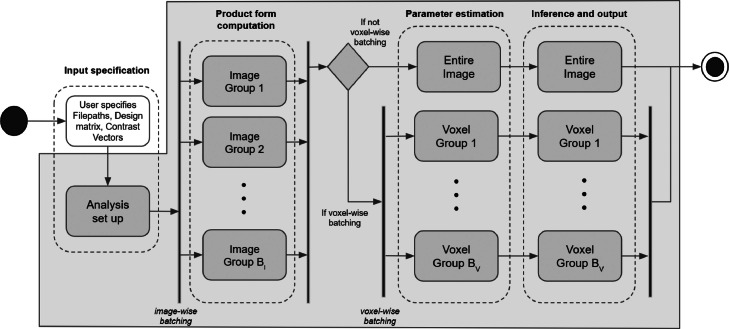
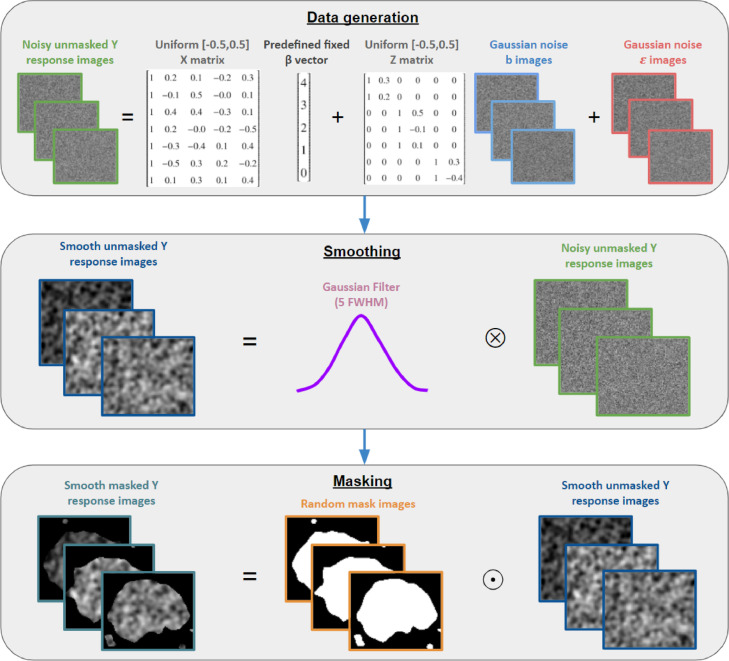
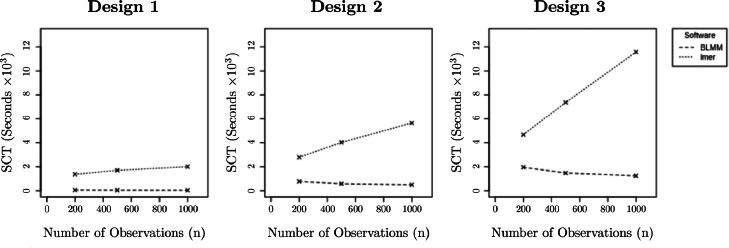
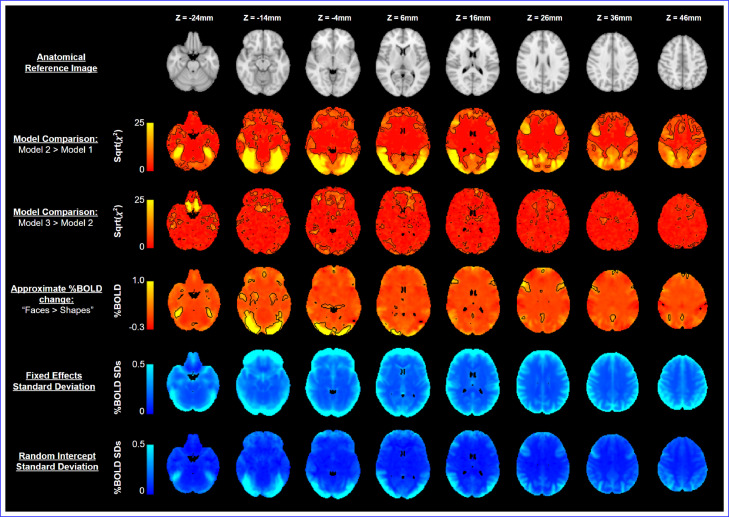
Within neuroimaging large-scale, shared datasets are becoming increasingly commonplace, challenging existing tools both in terms of overall scale and complexity of the study designs. As sample sizes grow, researchers are presented with new opportunities to detect and account for grouping factors and covariance structure present in large experimental designs. In particular, standard linear model methods cannot account for the covariance and grouping structures present in large datasets, and the existing linear mixed models (LMM) tools are neither scalable nor exploit the computational speed-ups afforded by vectorisation of computations over voxels. Further, nearly all existing tools for imaging (fixed or mixed effect) do not account for variability in the patterns of missing data near cortical boundaries and the edge of the brain, and instead omit any voxels with any missing data. Yet in the large-n setting, such a voxel-wise deletion missing data strategy leads to severe shrinkage of the final analysis mask. To counter these issues, we describe the "Big" Linear Mixed Models (BLMM) toolbox, an efficient Python package for large-scale fMRI LMM analyses. BLMM is designed for use on high performance computing clusters and utilizes a Fisher Scoring procedure made possible by derivations for the LMM Fisher information matrix and score vectors derived in our previous work, Maullin-Sapey and Nichols (2021).
Copyright © 2022. Published by Elsevier Inc.
Conflict of interest statement
Not applicable.
Figures


References
-
- Allen N., Sudlow C., Downey P., Peakman T., Danesh J., Elliott P., Gallacher J., Green J., Matthews P., Pell J., Sprosen T., Collins R. Uk biobank: current status and what it means for epidemiology. Health Policy Technol. 2012;1(3):123–126. doi: 10.1016/j.hlpt.2012.07.003. - DOI
-
ISSN 2211-8837
-
- Baayen R.H., Davidson D.J., Bates D.M. Mixed-effects modeling with crossed random effects for subjects and items. J. Mem. Lang. 2008;59(4):390–412. doi: 10.1016/j.jml.2007.12.005. - DOI
-
ISSN 0749-596X, URL http://www.sciencedirect.com/science/article/pii/S0749596X07001398. Special Issue: Emerging Data Analysis
-
- Barch D.M., Burgess G.C., Harms M.P., Petersen S.E., Schlaggar B.L., Corbetta M., Glasser M.F., Curtiss S., Dixit S., Feldt C., Nolan D., Bryant E., Hartley T., Footer O., Bjork J.M., Poldrack R., Smith S., Johansen-Berg H., Snyder A.Z., Essen D.C.V. Function in the human connectome: task-fmri and individual differences in behavior. NeuroImage 2013-oct vol. 80. 2013;80 doi: 10.1016/j.neuroimage.2013.05.033. - DOI - PMC - PubMed
-
- Bates, D., 2006. lmer, p-values and all that. https://stat.ethz.ch/pipermail/r-help/2006-May/094765.html, Accessed: 2020-12-07.
-
- Bates D., Mchler M., Bolker B., Walker S. Fitting linear mixed-effects models using lme4. J. Stat. Softw. 2015;67(1):1–48. doi: 10.18637/jss.v067.i01. - DOI
-
ISSN 1548-7660
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Medical
Research Materials
