

Value-free reinforcement learning: policy optimization as a minimal model of operant behavior
- PMID: 36341023
- PMCID: PMC9635588
- DOI: 10.1016/j.cobeha.2021.04.020
Value-free reinforcement learning: policy optimization as a minimal model of operant behavior
Abstract
Reinforcement learning is a powerful framework for modelling the cognitive and neural substrates of learning and decision making. Contemporary research in cognitive neuroscience and neuroeconomics typically uses value-based reinforcement-learning models, which assume that decision-makers choose by comparing learned values for different actions. However, another possibility is suggested by a simpler family of models, called policy-gradient reinforcement learning. Policy-gradient models learn by optimizing a behavioral policy directly, without the intermediate step of value-learning. Here we review recent behavioral and neural findings that are more parsimoniously explained by policy-gradient models than by value-based models. We conclude that, despite the ubiquity of 'value' in reinforcement-learning models of decision making, policy-gradient models provide a lightweight and compelling alternative model of operant behavior.
Keywords: computational modelling; decision-making; policy gradient; reinforcement learning; value.
Figures
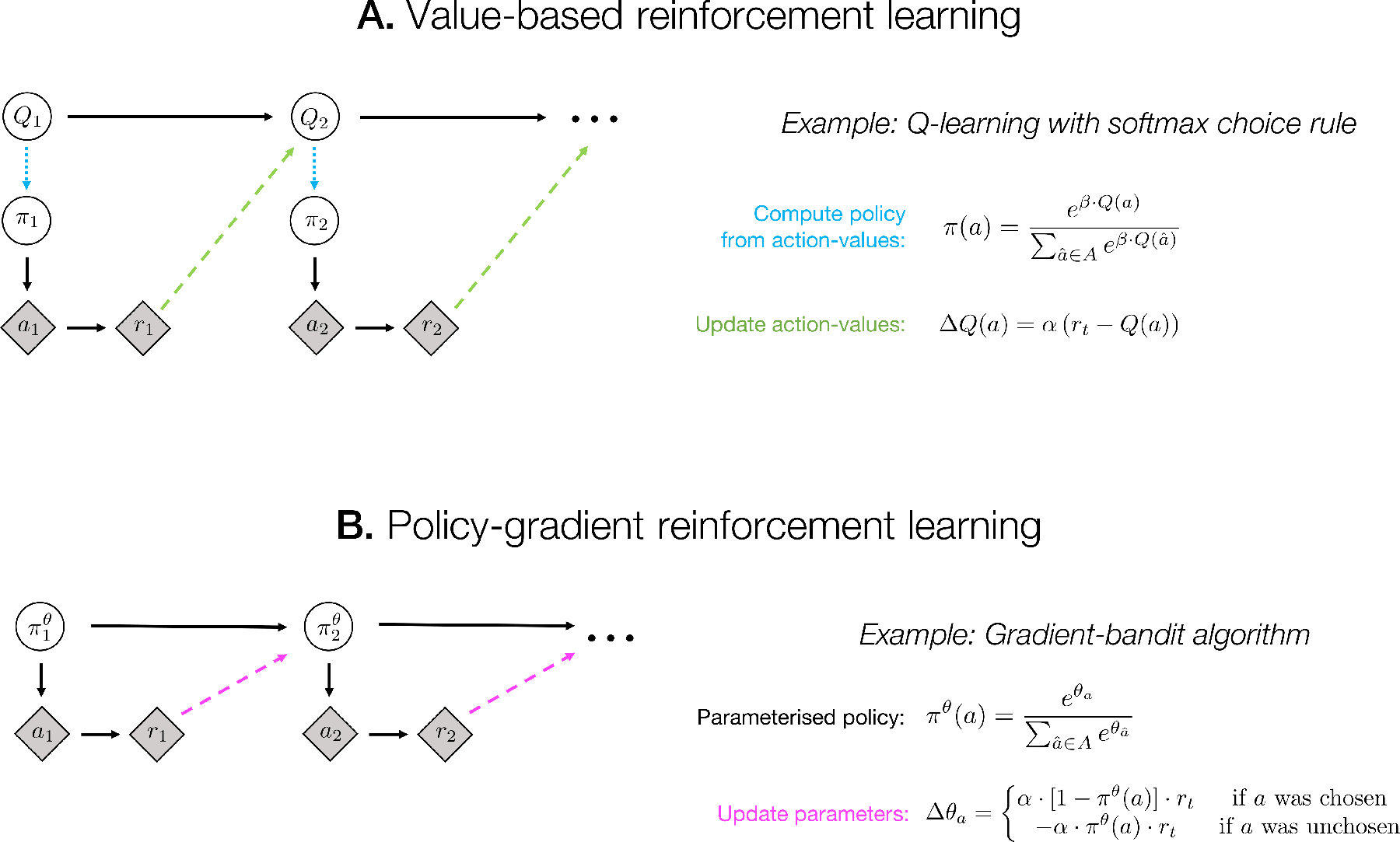
References
-
- Miller KJ, Shenhav A, Ludvig EA, Habits without values, Psychological Review 126 (2019) 292–311. - PMC - PubMed
-
* This paper presents evidence that habit formation—a process previously linked with model-free learning of action-values—may be instead produced by a value-free process in which choosing an action directly strengthens its future choice probability. Although this is not strictly speaking a policy-gradient model, it nevertheless points to the feasibility of explaining operant behavior in terms of modulation of a policy, without recourse to the explanatory construct of value.
-
- Juechems K, Summerfield C, Where does value come from?, Trends in Cognitive Sciences 23 (2019) 836–850. - PubMed
-
- Suri G, Gross JJ, McClelland JL, Value-based decision making: An interactive activation perspective, Psychological Review 127 (2020) 153. - PubMed
-
- Hayden B, Niv Y, The case against economic values in the brain, 2020. Preprint hosted at PsyArXiv. - PubMed
Grants and funding
LinkOut - more resources
Full Text Sources