

Discerning asthma endotypes through comorbidity mapping
- PMID: 36344522
- PMCID: PMC9640644
- DOI: 10.1038/s41467-022-33628-8
Discerning asthma endotypes through comorbidity mapping
Abstract
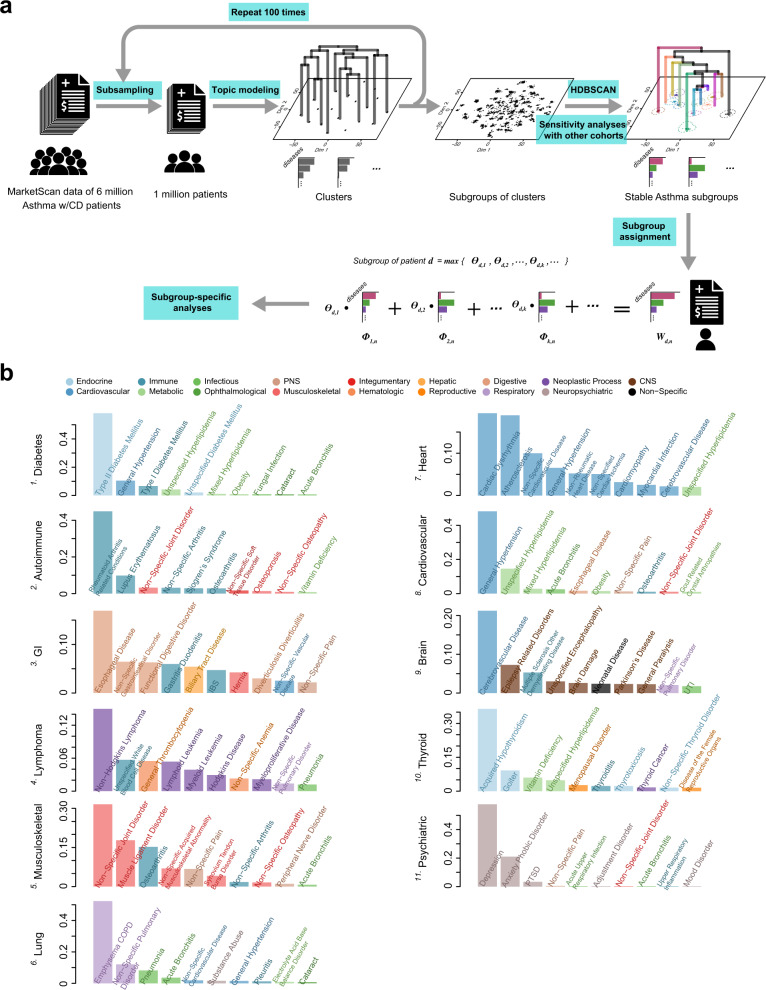
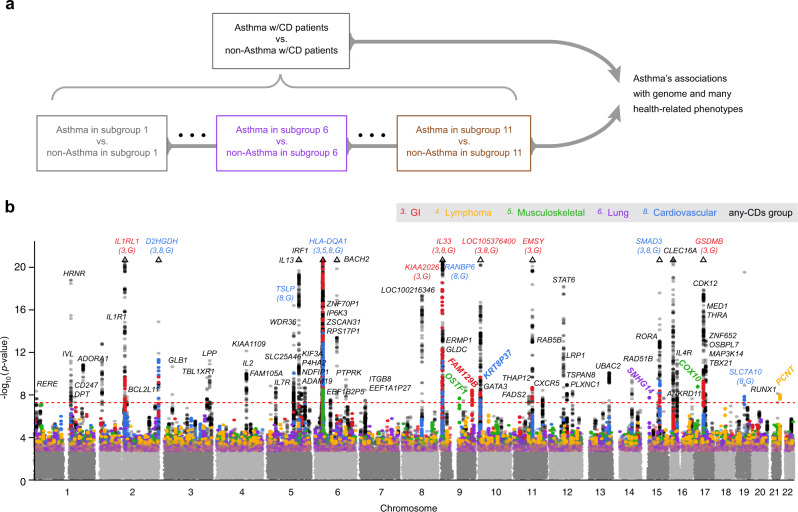
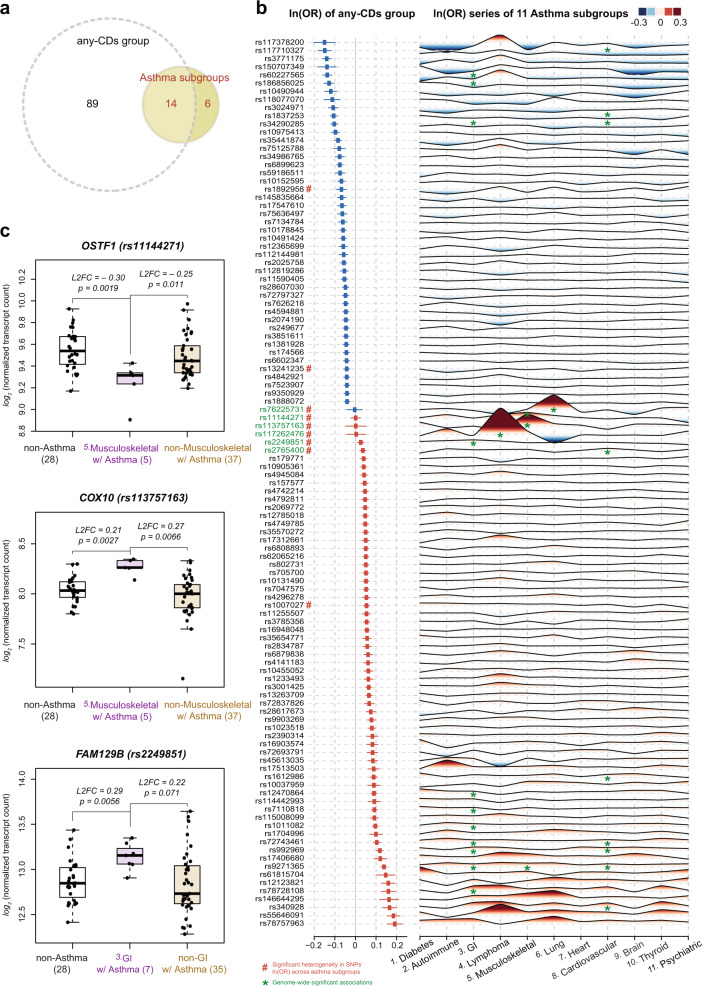
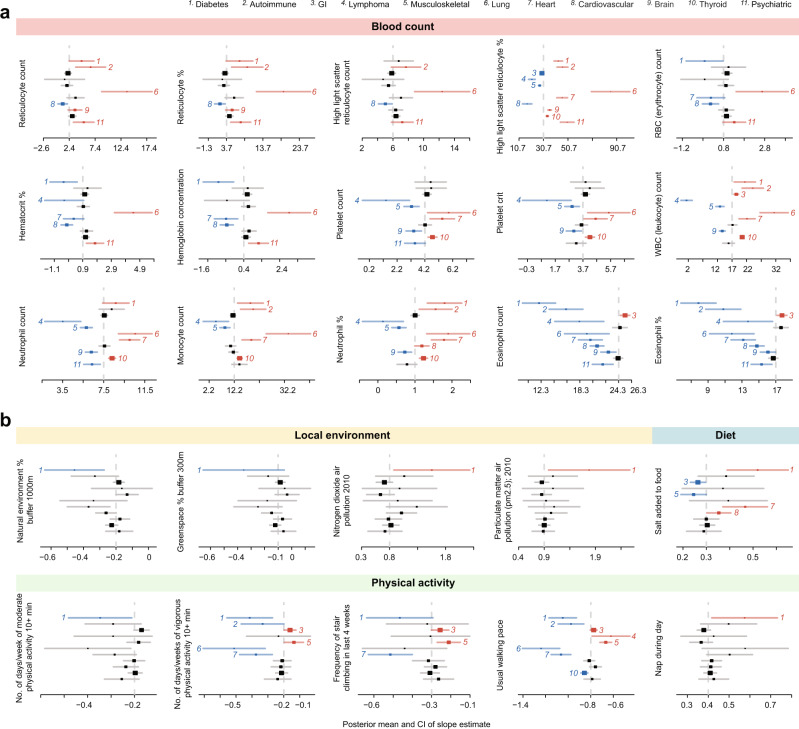
Asthma is a heterogeneous, complex syndrome, and identifying asthma endotypes has been challenging. We hypothesize that distinct endotypes of asthma arise in disparate genetic variation and life-time environmental exposure backgrounds, and that disease comorbidity patterns serve as a surrogate for such genetic and exposure variations. Here, we computationally discover 22 distinct comorbid disease patterns among individuals with asthma (asthma comorbidity subgroups) using diagnosis records for >151 M US residents, and re-identify 11 of the 22 subgroups in the much smaller UK Biobank. GWASs to discern asthma risk loci for individuals within each subgroup and in all subgroups combined reveal 109 independent risk loci, of which 52 are replicated in multi-ancestry meta-analysis across different ethnicity subsamples in UK Biobank, US BioVU, and BioBank Japan. Fourteen loci confer asthma risk in multiple subgroups and in all subgroups combined. Importantly, another six loci confer asthma risk in only one subgroup. The strength of association between asthma and each of 44 health-related phenotypes also varies dramatically across subgroups. This work reveals subpopulations of asthma patients distinguished by comorbidity patterns, asthma risk loci, gene expression, and health-related phenotypes, and so reveals different asthma endotypes.
© 2022. The Author(s).
Conflict of interest statement
J.S. reports grants from NIH, during the conduct of the study; grants from NIH, personal fees from PulmOne Advanced Medical Devices, Ltd, Israel, personal fees and non-financial support from Regeneron/Sanofi-Genzyme, grants from Chicago Biomedical Consortium Accelerator Network, outside the submitted work; in addition, J.S. has US Patents #6,090,618, #6,114,311, #6,284,743, #6,291,211, #6,297,221, #6,331,527, #7,169,764 issued, and two patent applications (WO2020206109 and WO2020206118) pending. The other authors declare no competing interests. S.W. reports grants from NIH during the conduct of the study; grants from NIH and personal fees from Regeneron/Sanofi-Genzyme and Astra-Zeneca, outside the submitted work.
Figures
References
-
- CDC.gov. CDC - Asthma - Data and Surveillance - Asthma Surveillance Data. Available at: http://www.cdc.gov/asthma/asthmadata.htm [Accessed 15 September 2019] (2018).
-
- Bouzigon E, et al. Effect of 17q21 variants and smoking exposure in early-onset asthma. N. Engl. J. Med. 2008;359:1985–1994. - PubMed
Publication types
MeSH terms
Grants and funding
- UL1 TR000445/TR/NCATS NIH HHS/United States
- R01 MH107666/MH/NIMH NIH HHS/United States
- MC_QA137853/MRC_/Medical Research Council/United Kingdom
- S10 RR025141/RR/NCRR NIH HHS/United States
- UH3 OD023282/OD/NIH HHS/United States
- U19 AI095230/AI/NIAID NIH HHS/United States
- U01 HL108634/HL/NHLBI NIH HHS/United States
- U19 AI162310/AI/NIAID NIH HHS/United States
- R01 HD074711/HD/NICHD NIH HHS/United States
- P50 GM115305/GM/NIGMS NIH HHS/United States
- UL1 TR002389/TR/NCATS NIH HHS/United States
- U01 HG009086/HG/NHGRI NIH HHS/United States
- R01 MH113362/MH/NIMH NIH HHS/United States
- P30 DK020595/DK/NIDDK NIH HHS/United States
- R01 HL122712/HL/NHLBI NIH HHS/United States
- S10 OD017985/OD/NIH HHS/United States
- U19 HL065962/HL/NHLBI NIH HHS/United States
- R01 HL129735/HL/NHLBI NIH HHS/United States
- R01 HL104608/HL/NHLBI NIH HHS/United States
- RC2 GM092618/GM/NIGMS NIH HHS/United States
- UG3 OD023282/CD/ODCDC CDC HHS/United States
- UG3 OD023282/OD/NIH HHS/United States
- K08 HL153955/HL/NHLBI NIH HHS/United States
- U01 HG006378/HG/NHGRI NIH HHS/United States
- UL1 RR024975/RR/NCRR NIH HHS/United States
- R01 NS032830/NS/NINDS NIH HHS/United States
- U01 HG004798/HG/NHGRI NIH HHS/United States
- MC_PC_17228/MRC_/Medical Research Council/United Kingdom
- UL1 TR002243/TR/NCATS NIH HHS/United States
