

Sequencing Illumina libraries at high accuracy on the ONT MinION using R2C2
- PMID: 36351772
- PMCID: PMC9808628
- DOI: 10.1101/gr.277031.122
Sequencing Illumina libraries at high accuracy on the ONT MinION using R2C2
Abstract
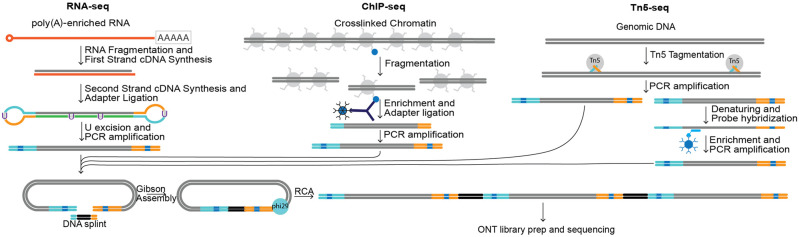
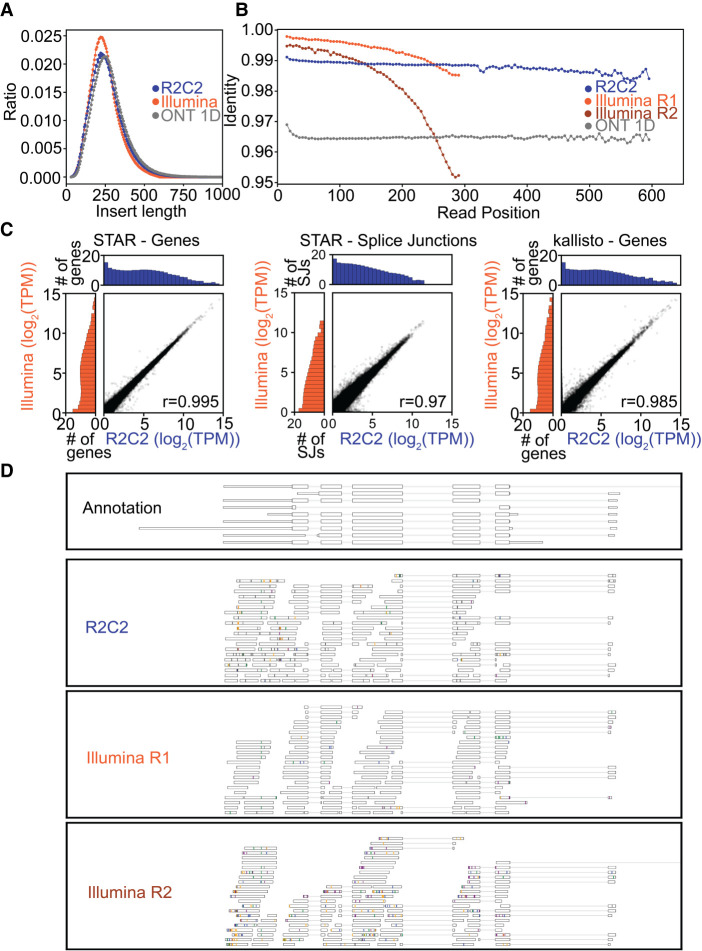
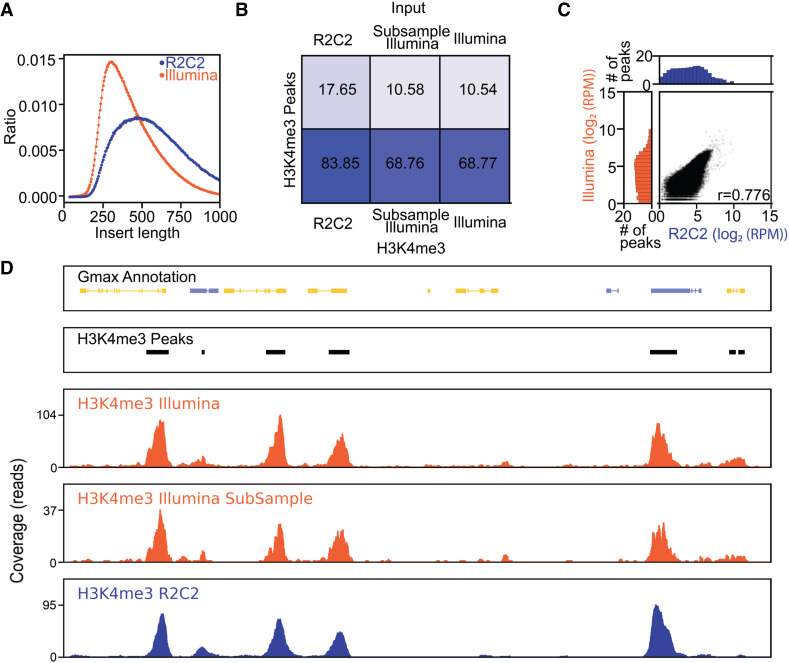
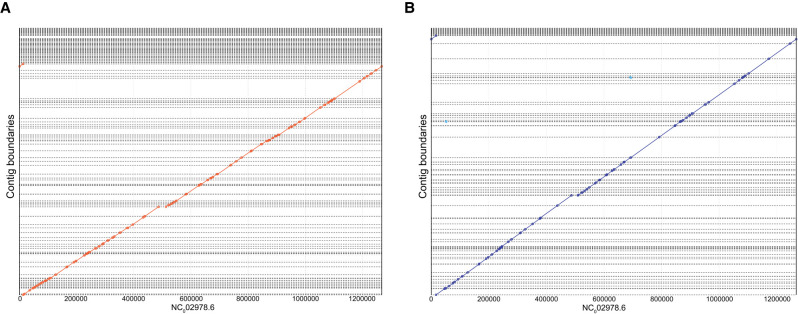
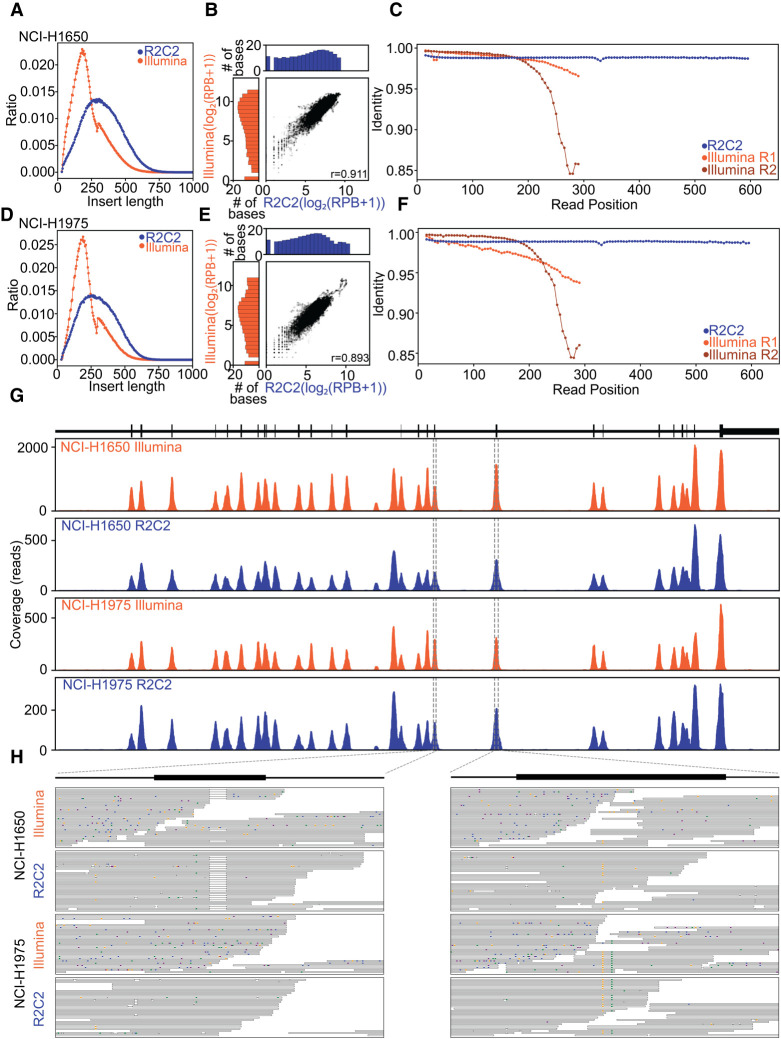
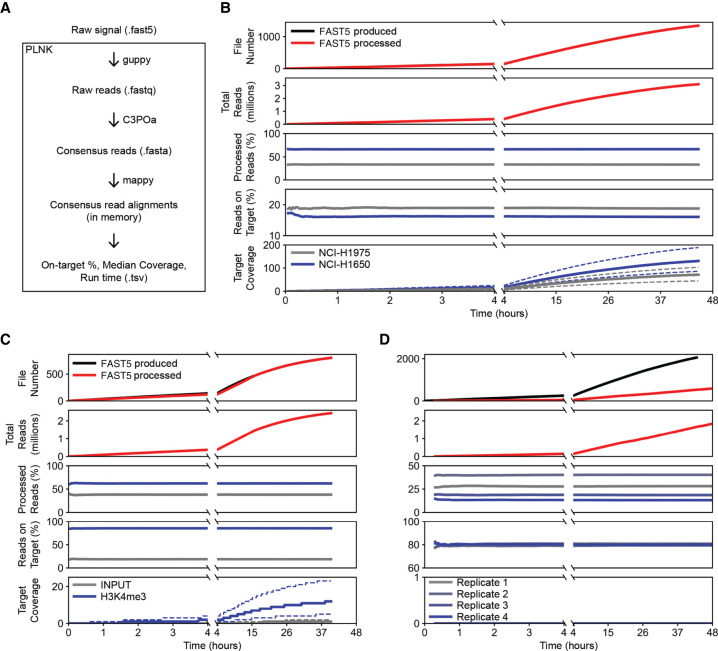
High-throughput short-read sequencing has taken on a central role in research and diagnostics. Hundreds of different assays take advantage of Illumina short-read sequencers, the predominant short-read sequencing technology available today. Although other short-read sequencing technologies exist, the ubiquity of Illumina sequencers in sequencing core facilities and the high capital costs of these technologies have limited their adoption. Among a new generation of sequencing technologies, Oxford Nanopore Technologies (ONT) holds a unique position because the ONT MinION, an error-prone long-read sequencer, is associated with little to no capital cost. Here we show that we can make short-read Illumina libraries compatible with the ONT MinION by using the rolling circle to concatemeric consensus (R2C2) method to circularize and amplify the short library molecules. This results in longer DNA molecules containing tandem repeats of the original short library molecules. This longer DNA is ideally suited for the ONT MinION, and after sequencing, the tandem repeats in the resulting raw reads can be converted into high-accuracy consensus reads with similar error rates to that of the Illumina MiSeq. We highlight this capability by producing and benchmarking RNA-seq, ChIP-seq, and regular and target-enriched Tn5 libraries. We also explore the use of this approach for rapid evaluation of sequencing library metrics by implementing a real-time analysis workflow.
© 2022 Zee et al.; Published by Cold Spring Harbor Laboratory Press.
Figures
References
-
- Ali SM, Hensing T, Schrock AB, Allen J, Sanford E, Gowen K, Kulkarni A, He J, Suh JH, Lipson D, et al. 2016. Comprehensive genomic profiling identifies a subset of crizotinib-responsive ALK-rearranged non-small cell lung cancer not detected by fluorescence in situ hybridization. Oncologist 21: 762–770. 10.1634/theoncologist.2015-0497 - DOI - PMC - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources