

APPINetwork: an R package for building and computational analysis of protein-protein interaction networks
- PMID: 36353604
- PMCID: PMC9639416
- DOI: 10.7717/peerj.14204
APPINetwork: an R package for building and computational analysis of protein-protein interaction networks
Abstract
Background: Protein-protein interactions (PPIs) are essential to almost every process in a cell. Analysis of PPI networks gives insights into the functional relationships among proteins and may reveal important hub proteins and sub-networks corresponding to functional modules. Several good tools have been developed for PPI network analysis but they have certain limitations. Most tools are suited for studying PPI in only a small number of model species, and do not allow second-order networks to be built, or offer relevant functions for their analysis. To overcome these limitations, we have developed APPINetwork (Analysis of Protein-protein Interaction Networks). The aim was to produce a generic and user-friendly package for building and analyzing a PPI network involving proteins of interest from any species as long they are stored in a database.
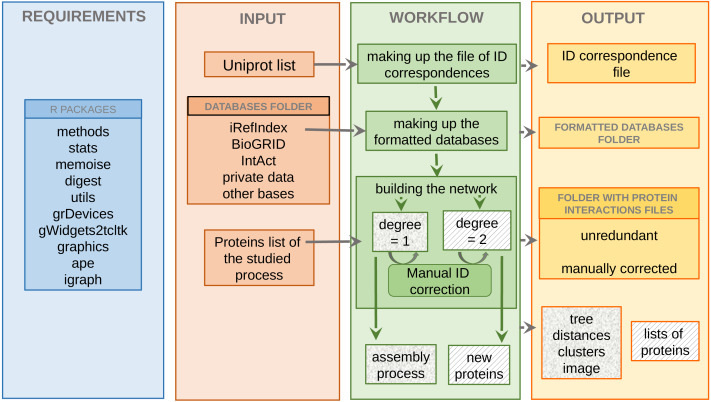
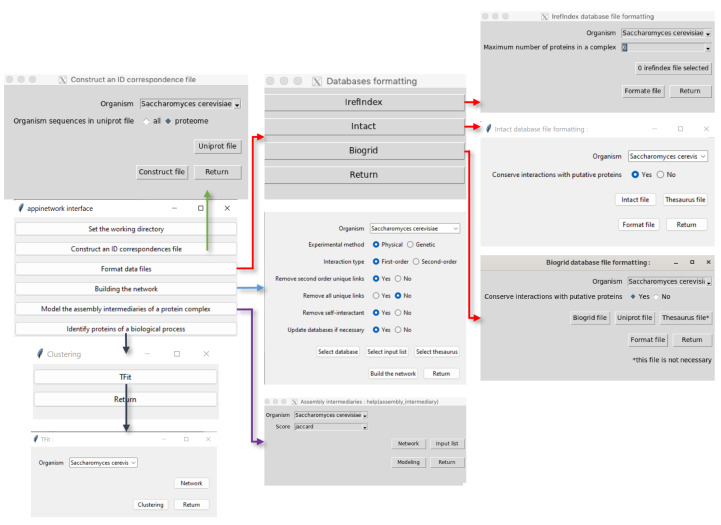
Methods: APPINetwork is an open-source R package. It can be downloaded and installed on the collaborative development platform GitLab (https://forgemia.inra.fr/GNet/appinetwork). A graphical user interface facilitates its use. Graphical windows, buttons, and scroll bars allow the user to select or enter an organism name, choose data files and network parameters or methods dedicated to network analysis. All functions are implemented in R, except for the script identifying all proteins involved in the same biological process (developed in C) and the scripts formatting the BioGRID data file and generating the IDs correspondence file (implemented in Python 3). PPI information comes from private resources or different public databases (such as IntAct, BioGRID, and iRefIndex). The package can be deployed on Linux and macOS operating systems (OS). Deployment on Windows is possible but it requires the prior installation of Rtools and Python 3.
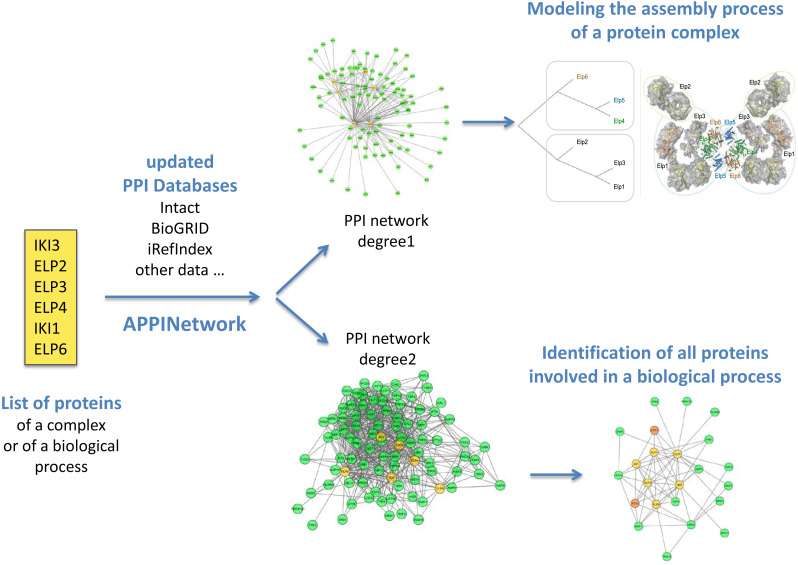
Results: APPINetwork allows the user to build a PPI network from selected public databases and add their own PPI data. In this network, the proteins have unique identifiers resulting from the standardization of the different identifiers specific to each database. In addition to the construction of the first-order network, APPINetwork offers the possibility of building a second-order network centered on the proteins of interest (proteins known for their role in the biological process studied or subunits of a complex protein) and provides the number and type of experiments that have highlighted each PPI, as well as references to articles containing experimental evidence.
Conclusion: More than a tool for PPI network building, APPINetwork enables the analysis of the resultant network, by searching either for the community of proteins involved in the same biological process or for the assembly intermediates of a protein complex. Results of these analyses are provided in easily exportable files. Examples files and a user manual describing each step of the process come with the package.
Keywords: Network; Network clustering; Protein complex intermediaries; Protein–protein interaction.
©2022 Gosset et al.
Conflict of interest statement
The authors declare there are no competing interests.
Figures
References
-
- Aranda B, Blankenburg H, Kerrien S, Brinkman FS, Ceol A, Chautard E, Dana JM, De Las Rivas J, Dumousseau M, Galeota E, Gaulton A, Goll J, Hancock RE, Isserlin R, Jimenez RC, Kerssemakers J, Khadake J, Lynn DJ, Michaut M, O’Kelly G, Ono K, Orchard S, Prieto C, Razick S, Rigina O, Salwinski L, Simonovic M, Velankar S, Winter A, Wu G, Bader GD, Cesareni G, Donaldson IM, Eisenberg D, Kleywegt GJ, Overington J, Ricard-Blum S, Tyers M, Albrecht M, Hermjakob H. PSICQUIC and PSISCORE: accessing and scoring molecular interactions. Nature Methods. 2011;29:528–529. doi: 10.1038/nmeth.1637. - DOI - PMC - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
