

Unsupervised Image-to-Image Translation: A Review
- PMID: 36366238
- PMCID: PMC9654990
- DOI: 10.3390/s22218540
Unsupervised Image-to-Image Translation: A Review
Abstract
Supervised image-to-image translation has been proven to generate realistic images with sharp details and to have good quantitative performance. Such methods are trained on a paired dataset, where an image from the source domain already has a corresponding translated image in the target domain. However, this paired dataset requirement imposes a huge practical constraint, requires domain knowledge or is even impossible to obtain in certain cases. Due to these problems, unsupervised image-to-image translation has been proposed, which does not require domain expertise and can take advantage of a large unlabeled dataset. Although such models perform well, they are hard to train due to the major constraints induced in their loss functions, which make training unstable. Since CycleGAN has been released, numerous methods have been proposed which try to address various problems from different perspectives. In this review, we firstly describe the general image-to-image translation framework and discuss the datasets and metrics involved in the topic. Furthermore, we revise the current state-of-the-art with a classification of existing works. This part is followed by a small quantitative evaluation, for which results were taken from papers.
Keywords: computer vision; deep learning; generative adversarial networks; machine learning; review; unsupervised image-to-image translation.
Conflict of interest statement
The authors declare no conflict of interest.
Figures
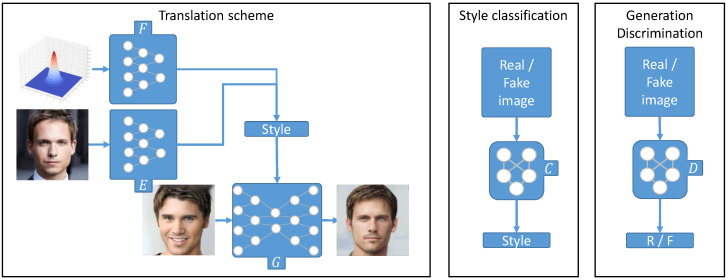
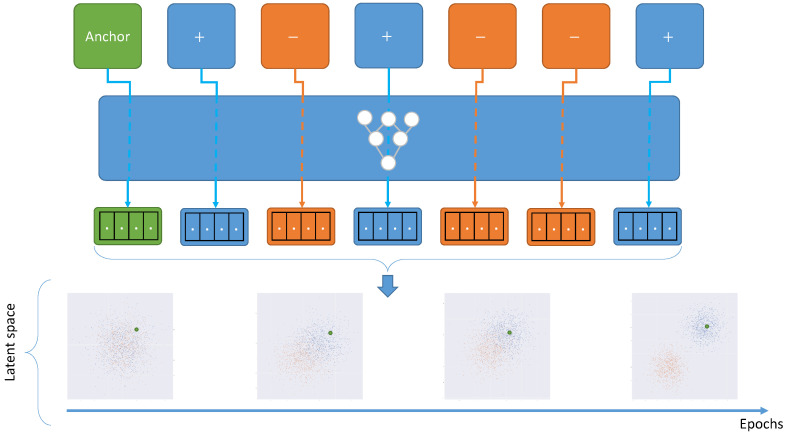
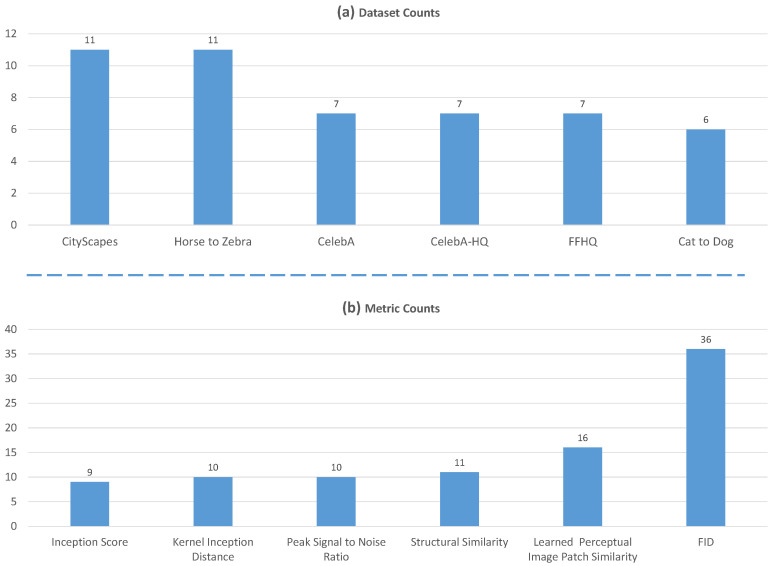
References
-
- Isola P., Zhu J.Y., Zhou T., Efros A.A. Image-to-Image Translation with Conditional Adversarial Networks; Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR); Honolulu, HI, USA. 21–26 July 2017; pp. 5967–5976. - DOI
-
- Wang T.C., Liu M.Y., Zhu J.Y., Tao A., Kautz J., Catanzaro B. High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs. [(accessed on 31 December 2018)]; Available online: http://xxx.lanl.gov/abs/1711.11585.
-
- Bousmalis K., Silberman N., Dohan D., Erhan D., Krishnan D. Unsupervised Pixel-Level Domain Adaptation with Generative Adversarial Networks; Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR); Honolulu, HI, USA. 21–26 July 2017; pp. 95–104. - DOI
-
- Liu M.Y., Breuel T., Kautz J. Unsupervised Image-to-Image Translation Networks. arXiv. 20171703.00848
-
- Taigman Y., Polyak A., Wolf L. Unsupervised Cross-Domain Image Generation. [(accessed on 31 December 2017)]; Available online: http://xxx.lanl.gov/abs/1611.02200[cs]
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
