

Application of convex hull analysis for the evaluation of data heterogeneity between patient populations of different origin and implications of hospital bias in downstream machine-learning-based data processing: A comparison of 4 critical-care patient datasets
- PMID: 36387013
- PMCID: PMC9659720
- DOI: 10.3389/fdata.2022.603429
Application of convex hull analysis for the evaluation of data heterogeneity between patient populations of different origin and implications of hospital bias in downstream machine-learning-based data processing: A comparison of 4 critical-care patient datasets
Abstract
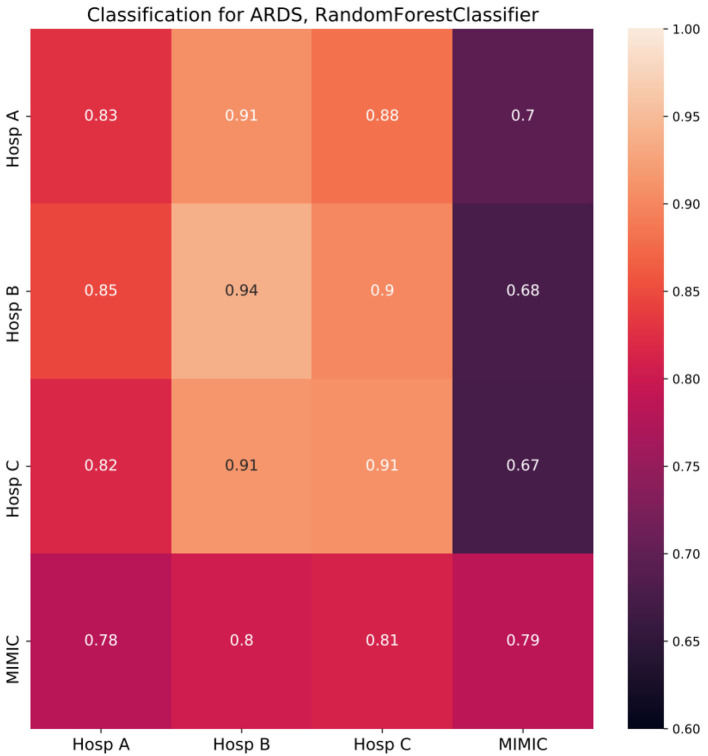
Machine learning (ML) models are developed on a learning dataset covering only a small part of the data of interest. If model predictions are accurate for the learning dataset but fail for unseen data then generalization error is considered high. This problem manifests itself within all major sub-fields of ML but is especially relevant in medical applications. Clinical data structures, patient cohorts, and clinical protocols may be highly biased among hospitals such that sampling of representative learning datasets to learn ML models remains a challenge. As ML models exhibit poor predictive performance over data ranges sparsely or not covered by the learning dataset, in this study, we propose a novel method to assess their generalization capability among different hospitals based on the convex hull (CH) overlap between multivariate datasets. To reduce dimensionality effects, we used a two-step approach. First, CH analysis was applied to find mean CH coverage between each of the two datasets, resulting in an upper bound of the prediction range. Second, 4 types of ML models were trained to classify the origin of a dataset (i.e., from which hospital) and to estimate differences in datasets with respect to underlying distributions. To demonstrate the applicability of our method, we used 4 critical-care patient datasets from different hospitals in Germany and USA. We estimated the similarity of these populations and investigated whether ML models developed on one dataset can be reliably applied to another one. We show that the strongest drop in performance was associated with the poor intersection of convex hulls in the corresponding hospitals' datasets and with a high performance of ML methods for dataset discrimination. Hence, we suggest the application of our pipeline as a first tool to assess the transferability of trained models. We emphasize that datasets from different hospitals represent heterogeneous data sources, and the transfer from one database to another should be performed with utmost care to avoid implications during real-world applications of the developed models. Further research is needed to develop methods for the adaptation of ML models to new hospitals. In addition, more work should be aimed at the creation of gold-standard datasets that are large and diverse with data from varied application sites.
Keywords: ARDS; convex hull (CH); data pooling; dataset-bias; generalization error.
Copyright © 2022 Sharafutdinov, Bhat, Fritsch, Nikulina, E. Samadi, Polzin, Mayer, Marx, Bickenbach and Schuppert.
Conflict of interest statement
HM is an employee of Bayer AG, Germany. HM has stock ownership with Bayer AG, Germany. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Figures


Similar articles
-
Computational Simulation of Virtual Patients Reduces Dataset Bias and Improves Machine Learning-Based Detection of ARDS from Noisy Heterogeneous ICU Datasets.IEEE Open J Eng Med Biol. 2023 Feb 8;5:611-620. doi: 10.1109/OJEMB.2023.3243190. eCollection 2024. IEEE Open J Eng Med Biol. 2023. PMID: 39184970 Free PMC article.
-
Ensemble machine learning model trained on a new synthesized dataset generalizes well for stress prediction using wearable devices.J Biomed Inform. 2023 Dec;148:104556. doi: 10.1016/j.jbi.2023.104556. Epub 2023 Dec 2. J Biomed Inform. 2023. PMID: 38048895
-
Evaluating and Enhancing the Generalization Performance of Machine Learning Models for Physical Activity Intensity Prediction From Raw Acceleration Data.IEEE J Biomed Health Inform. 2020 Jan;24(1):27-38. doi: 10.1109/JBHI.2019.2917565. Epub 2019 May 20. IEEE J Biomed Health Inform. 2020. PMID: 31107668
-
Deep Learning in Large and Multi-Site Structural Brain MR Imaging Datasets.Front Neuroinform. 2022 Jan 20;15:805669. doi: 10.3389/fninf.2021.805669. eCollection 2021. Front Neuroinform. 2022. PMID: 35126080 Free PMC article. Review.
-
[Data-driven intensive care: a lack of comprehensive datasets].Med Klin Intensivmed Notfmed. 2024 Jun;119(5):352-357. doi: 10.1007/s00063-024-01141-z. Epub 2024 Apr 26. Med Klin Intensivmed Notfmed. 2024. PMID: 38668882 Review. German.
Cited by
-
Computational Simulation of Virtual Patients Reduces Dataset Bias and Improves Machine Learning-Based Detection of ARDS from Noisy Heterogeneous ICU Datasets.IEEE Open J Eng Med Biol. 2023 Feb 8;5:611-620. doi: 10.1109/OJEMB.2023.3243190. eCollection 2024. IEEE Open J Eng Med Biol. 2023. PMID: 39184970 Free PMC article.
-
A hybrid modeling framework for generalizable and interpretable predictions of ICU mortality across multiple hospitals.Sci Rep. 2024 Mar 8;14(1):5725. doi: 10.1038/s41598-024-55577-6. Sci Rep. 2024. PMID: 38459085 Free PMC article.
-
Developing an Artificial Intelligence-Based Representation of a Virtual Patient Model for Real-Time Diagnosis of Acute Respiratory Distress Syndrome.Diagnostics (Basel). 2023 Jun 17;13(12):2098. doi: 10.3390/diagnostics13122098. Diagnostics (Basel). 2023. PMID: 37370993 Free PMC article.
-
Analysis of Chest X-ray for COVID-19 Diagnosis as a Use Case for an HPC-Enabled Data Analysis and Machine Learning Platform for Medical Diagnosis Support.Diagnostics (Basel). 2023 Jan 20;13(3):391. doi: 10.3390/diagnostics13030391. Diagnostics (Basel). 2023. PMID: 36766496 Free PMC article.
References
-
- Balestriero R., Pesenti J., LeCun Y. (2021). Learning in high dimension always amounts to extrapolation. arXiv preprint arXiv:2110.09485. 10.48550/arXiv.2110.09485 - DOI
-
- Barish M., Bolourani S., Lau L. F., Shah S., Zanos T. P. (2021). External validation demonstrates limited clinical utility of the interpretable mortality prediction model for patients with COVID-19. Nat. Mach. Intell. 3, 25–27. 10.1038/s42256-020-00254-2 - DOI
LinkOut - more resources
Full Text Sources
Research Materials