

Moving the needle: Employing deep reinforcement learning to push the boundaries of coarse-grained vaccine models
- PMID: 36405722
- PMCID: PMC9670804
- DOI: 10.3389/fimmu.2022.1029167
Moving the needle: Employing deep reinforcement learning to push the boundaries of coarse-grained vaccine models
Abstract
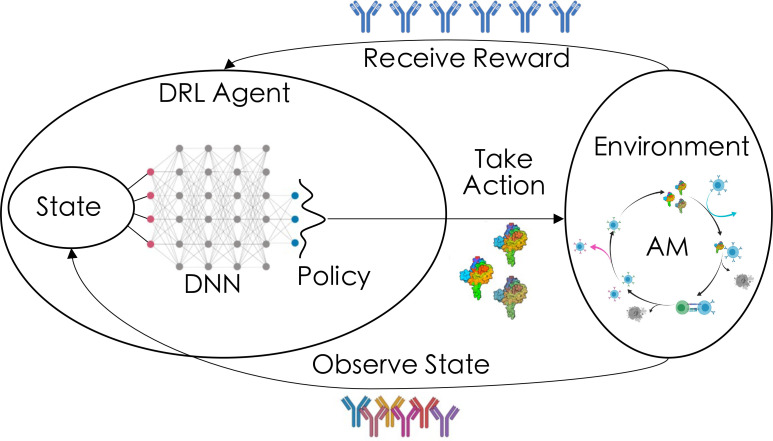
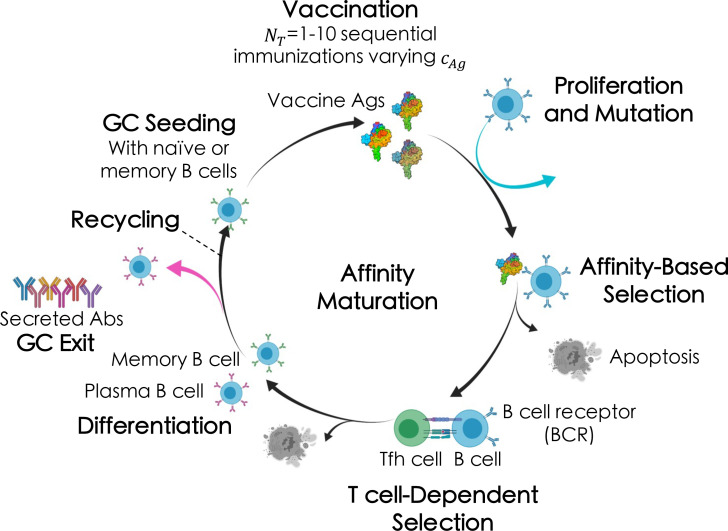
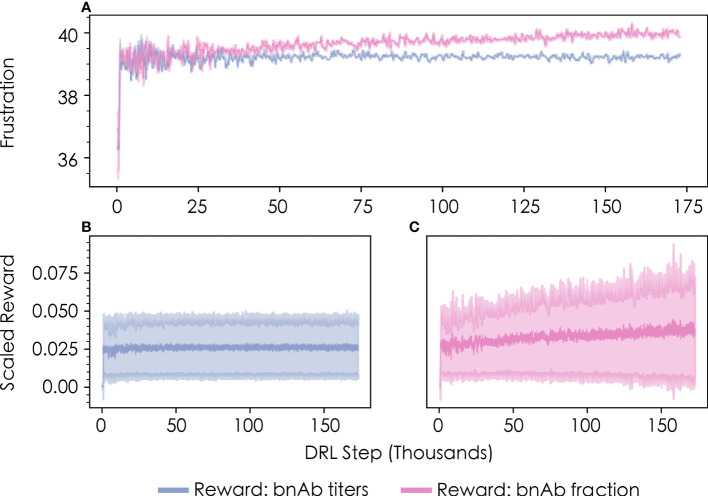
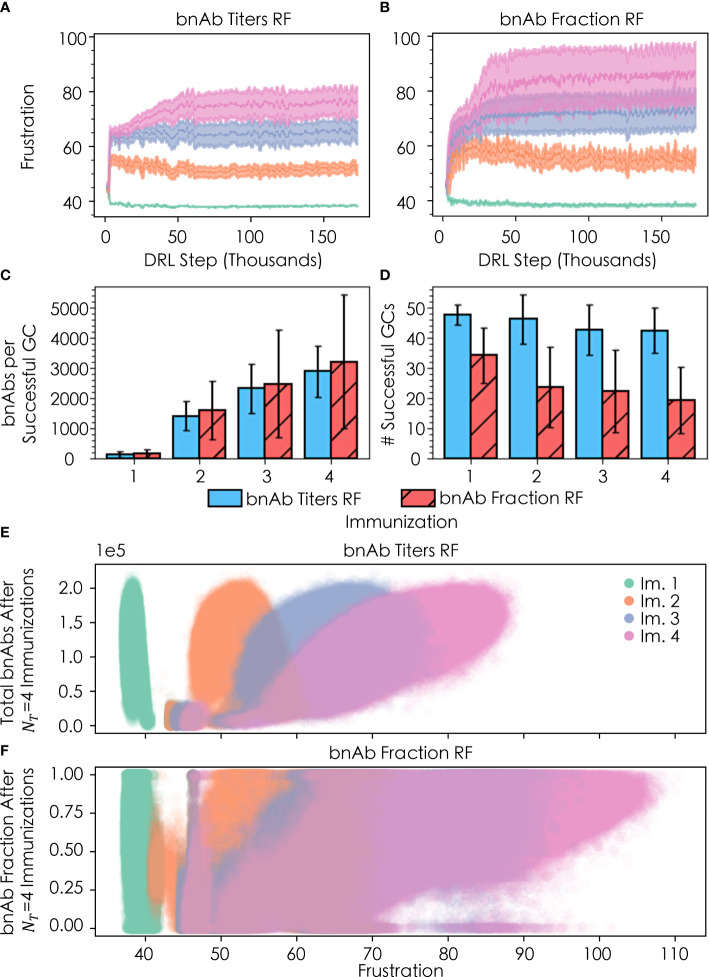
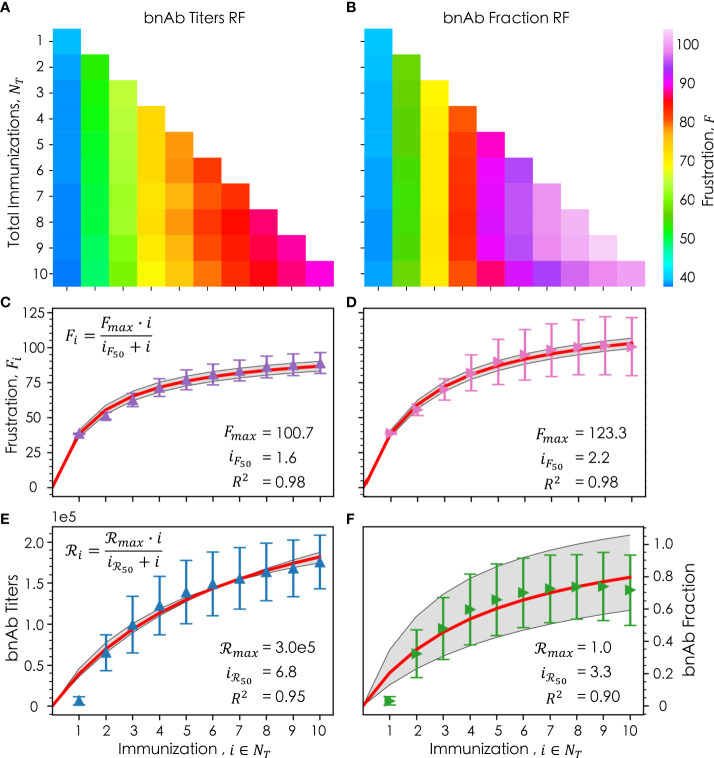
Highly mutable infectious disease pathogens (hm-IDPs) such as HIV and influenza evolve faster than the human immune system can contain them, allowing them to circumvent traditional vaccination approaches and causing over one million deaths annually. Agent-based models can be used to simulate the complex interactions that occur between immune cells and hm-IDP-like proteins (antigens) during affinity maturation-the process by which antibodies evolve. Compared to existing experimental approaches, agent-based models offer a safe, low-cost, and rapid route to study the immune response to vaccines spanning a wide range of design variables. However, the highly stochastic nature of affinity maturation and vast sequence space of hm-IDPs render brute force searches intractable for exploring all pertinent vaccine design variables and the subset of immunization protocols encompassed therein. To address this challenge, we employed deep reinforcement learning to drive a recently developed agent-based model of affinity maturation to focus sampling on immunization protocols with greater potential to improve the chosen metrics of protection, namely the broadly neutralizing antibody (bnAb) titers or fraction of bnAbs produced. Using this approach, we were able to coarse-grain a wide range of vaccine design variables and explore the relevant design space. Our work offers new testable insights into how vaccines should be formulated to maximize protective immune responses to hm-IDPs and how they can be minimally tailored to account for major sources of heterogeneity in human immune responses and various socioeconomic factors. Our results indicate that the first 3 to 5 immunizations, depending on the metric of protection, should be specially tailored to achieve a robust protective immune response, but that beyond this point further immunizations require only subtle changes in formulation to sustain a durable bnAb response.
Keywords: HIV - human immunodeficiency virus; affinity maturation; agent-based modelling; deep reinforcement learning (Deep RL); immunovirology; multiscale (MS) modelling; vaccine design protocol.
Copyright © 2022 Faris, Orbidan, Wells, Petersen and Sprenger.
Conflict of interest statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Figures
Similar articles
-
Strategies for induction of HIV-1 envelope-reactive broadly neutralizing antibodies.J Int AIDS Soc. 2021 Nov;24 Suppl 7(Suppl 7):e25831. doi: 10.1002/jia2.25831. J Int AIDS Soc. 2021. PMID: 34806332 Free PMC article. Review.
-
Multiscale affinity maturation simulations to elicit broadly neutralizing antibodies against HIV.PLoS Comput Biol. 2022 Apr 20;18(4):e1009391. doi: 10.1371/journal.pcbi.1009391. eCollection 2022 Apr. PLoS Comput Biol. 2022. PMID: 35442968 Free PMC article.
-
Potent Induction of Envelope-Specific Antibody Responses by Virus-Like Particle Immunogens Based on HIV-1 Envelopes from Patients with Early Broadly Neutralizing Responses.J Virol. 2022 Jan 12;96(1):e0134321. doi: 10.1128/JVI.01343-21. Epub 2021 Oct 20. J Virol. 2022. PMID: 34668778 Free PMC article.
-
Coadministration of CH31 Broadly Neutralizing Antibody Does Not Affect Development of Vaccine-Induced Anti-HIV-1 Envelope Antibody Responses in Infant Rhesus Macaques.J Virol. 2019 Feb 19;93(5):e01783-18. doi: 10.1128/JVI.01783-18. Print 2019 Mar 1. J Virol. 2019. PMID: 30541851 Free PMC article.
-
Human Ig knockin mice to study the development and regulation of HIV-1 broadly neutralizing antibodies.Immunol Rev. 2017 Jan;275(1):89-107. doi: 10.1111/imr.12505. Immunol Rev. 2017. PMID: 28133799 Free PMC article. Review.
Cited by
-
Broadly neutralizing antibodies for HIV prevention: a comprehensive review and future perspectives.Clin Microbiol Rev. 2024 Jun 13;37(2):e0015222. doi: 10.1128/cmr.00152-22. Epub 2024 Apr 30. Clin Microbiol Rev. 2024. PMID: 38687039 Free PMC article. Review.
-
Retrospective SARS-CoV-2 human antibody development trajectories are largely sparse and permissive.Proc Natl Acad Sci U S A. 2025 Jan 28;122(4):e2412787122. doi: 10.1073/pnas.2412787122. Epub 2025 Jan 22. Proc Natl Acad Sci U S A. 2025. PMID: 39841142 Free PMC article.
-
The application of machine learning in clinical microbiology and infectious diseases.Front Cell Infect Microbiol. 2025 May 1;15:1545646. doi: 10.3389/fcimb.2025.1545646. eCollection 2025. Front Cell Infect Microbiol. 2025. PMID: 40375898 Free PMC article. Review.
-
Deep learning in next-generation vaccine development for infectious diseases.Mol Ther Nucleic Acids. 2025 Jun 4;36(3):102586. doi: 10.1016/j.omtn.2025.102586. eCollection 2025 Sep 9. Mol Ther Nucleic Acids. 2025. PMID: 40641804 Free PMC article. Review.
References
-
- Vaccine-preventable diseases. Health.mil; (2020). Available at: https://www.health.mil/Military-Health-Topics/Health-Readiness/Immunizat....
-
- HIV/AIDS . Available at: https://www.who.int/data/gho/data/themes/hiv-aids.
-
- WHO . WHO coronavirus (COVID-19) dashboard with vaccination data. Available at: https://covid19.who.int/.
-
- History of 1918 flu pandemic. In: Pandemic influenza (Flu) (2018). CDC. Available at: https://www.cdc.gov/flu/pandemic-resources/1918-commemoration/1918-pande....
-
- Janeway CJ, Travers P, Walport M. Pathogens have evolved various means of evading or subverting normal host defenses. Immunobiology: Immune System Health Dis 5th edition (2001). Available at: https://www.ncbi.nlm.nih.gov/books/NBK27176/
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Medical