

Information extraction from electronic medical documents: state of the art and future research directions
- PMID: 36405956
- PMCID: PMC9640816
- DOI: 10.1007/s10115-022-01779-1
Information extraction from electronic medical documents: state of the art and future research directions
Abstract
In the medical field, a doctor must have a comprehensive knowledge by reading and writing narrative documents, and he is responsible for every decision he takes for patients. Unfortunately, it is very tiring to read all necessary information about drugs, diseases and patients due to the large amount of documents that are increasing every day. Consequently, so many medical errors can happen and even kill people. Likewise, there is such an important field that can handle this problem, which is the information extraction. There are several important tasks in this field to extract the important and desired information from unstructured text written in natural language. The main principal tasks are named entity recognition and relation extraction since they can structure the text by extracting the relevant information. However, in order to treat the narrative text we should use natural language processing techniques to extract useful information and features. In our paper, we introduce and discuss the several techniques and solutions used in these tasks. Furthermore, we outline the challenges in information extraction from medical documents. In our knowledge, this is the most comprehensive survey in the literature with an experimental analysis and a suggestion for some uncovered directions.
Keywords: Electronic medical records; Information extraction; Medical named entities recognition; Medical relation extraction; Section detection.
© The Author(s), under exclusive licence to Springer-Verlag London Ltd., part of Springer Nature 2022, Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
Conflict of interest statement
Conflict of interestThe authors declare that they have no competing interests.
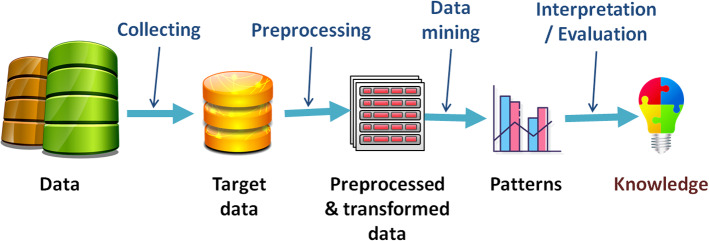
Figures
References
-
- Abacha AB, Zweigenbaum P (2011) Medical entity recognition: a comparaison of semantic and statistical methods. In: Proceedings of BioNLP 2011 workshop, pp 56–64
-
- Aich S, Sain M, Park J, Choi KW, Kim HC (2017) A text mining approach to identify the relationship between gait-parkinson’s disease (pd) from pd based research articles. In: 2017 international conference on inventive computing and informatics (ICICI), IEEE, pp 481–485
-
- Akbik A, Bergmann T, Blythe D, Rasul K, Schweter S, Vollgraf R (2019) Flair: an easy-to-use framework for state-of-the-art nlp. In: Proceedings of the 2019 conference of the north american chapter of the association for computational linguistics (Demonstrations), pp 54–59
-
- Al-Dafas M, Albujeer A, Hussien SA, Ibrahim RK. On the adaption of data mining technology to categorize cancer diseases. Int J Artif Intell Inform. 2022;3(2):80–91.
Publication types
LinkOut - more resources
Full Text Sources