

Adaptability of AI for safety evaluation in regulatory science: A case study of drug-induced liver injury
- PMID: 36425225
- PMCID: PMC9679417
- DOI: 10.3389/frai.2022.1034631
Adaptability of AI for safety evaluation in regulatory science: A case study of drug-induced liver injury
Abstract
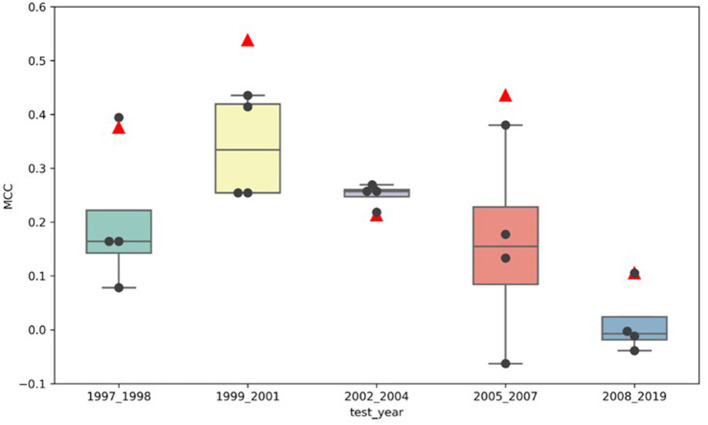
Artificial intelligence (AI) has played a crucial role in advancing biomedical sciences but has yet to have the impact it merits in regulatory science. As the field advances, in silico and in vitro approaches have been evaluated as alternatives to animal studies, in a drive to identify and mitigate safety concerns earlier in the drug development process. Although many AI tools are available, their acceptance in regulatory decision-making for drug efficacy and safety evaluation is still a challenge. It is a common perception that an AI model improves with more data, but does reality reflect this perception in drug safety assessments? Importantly, a model aiming at regulatory application needs to take a broad range of model characteristics into consideration. Among them is adaptability, defined as the adaptive behavior of a model as it is retrained on unseen data. This is an important model characteristic which should be considered in regulatory applications. In this study, we set up a comprehensive study to assess adaptability in AI by mimicking the real-world scenario of the annual addition of new drugs to the market, using a model we previously developed known as DeepDILI for predicting drug-induced liver injury (DILI) with a novel Deep Learning method. We found that the target test set plays a major role in assessing the adaptive behavior of our model. Our findings also indicated that adding more drugs to the training set does not significantly affect the predictive performance of our adaptive model. We concluded that the proposed adaptability assessment framework has utility in the evaluation of the performance of a model over time.
Keywords: AI; adaptability; deep learning; drug safety; drug-induced liver injury (DILI); regulatory science; risk assessment.
Copyright © 2022 Connor, Li, Roberts, Thakkar, Liu and Tong.
Conflict of interest statement
Author RR is co-founder and co-director of ApconiX, an integrated toxicology and ion channel company that provides expert advice on non-clinical aspects of drug discovery and drug development to academia, industry, and not-for-profit organizations. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Figures



References
-
- FDA (2021). Advancing Regulatory Science at FDA: Focus Areas of Regulatory Science (FARS). MD, USA: FDA Silver Spring.
-
- Groce A., Peled D., Yannakakis M. (2002). “Tools and Algorithms for the Construction and Analysis of Systems.” In: Lecture Notes in Computer Science. eds. JP. Katoen, and P. Stevens (Berlin; Heidelberg: Springer; ) 2280. 10.1007/3-540-46002-0_25 - DOI
Publication types
LinkOut - more resources
Full Text Sources
Research Materials