

Contextual inference in learning and memory
- PMID: 36435674
- PMCID: PMC9789331
- DOI: 10.1016/j.tics.2022.10.004
Contextual inference in learning and memory
Abstract
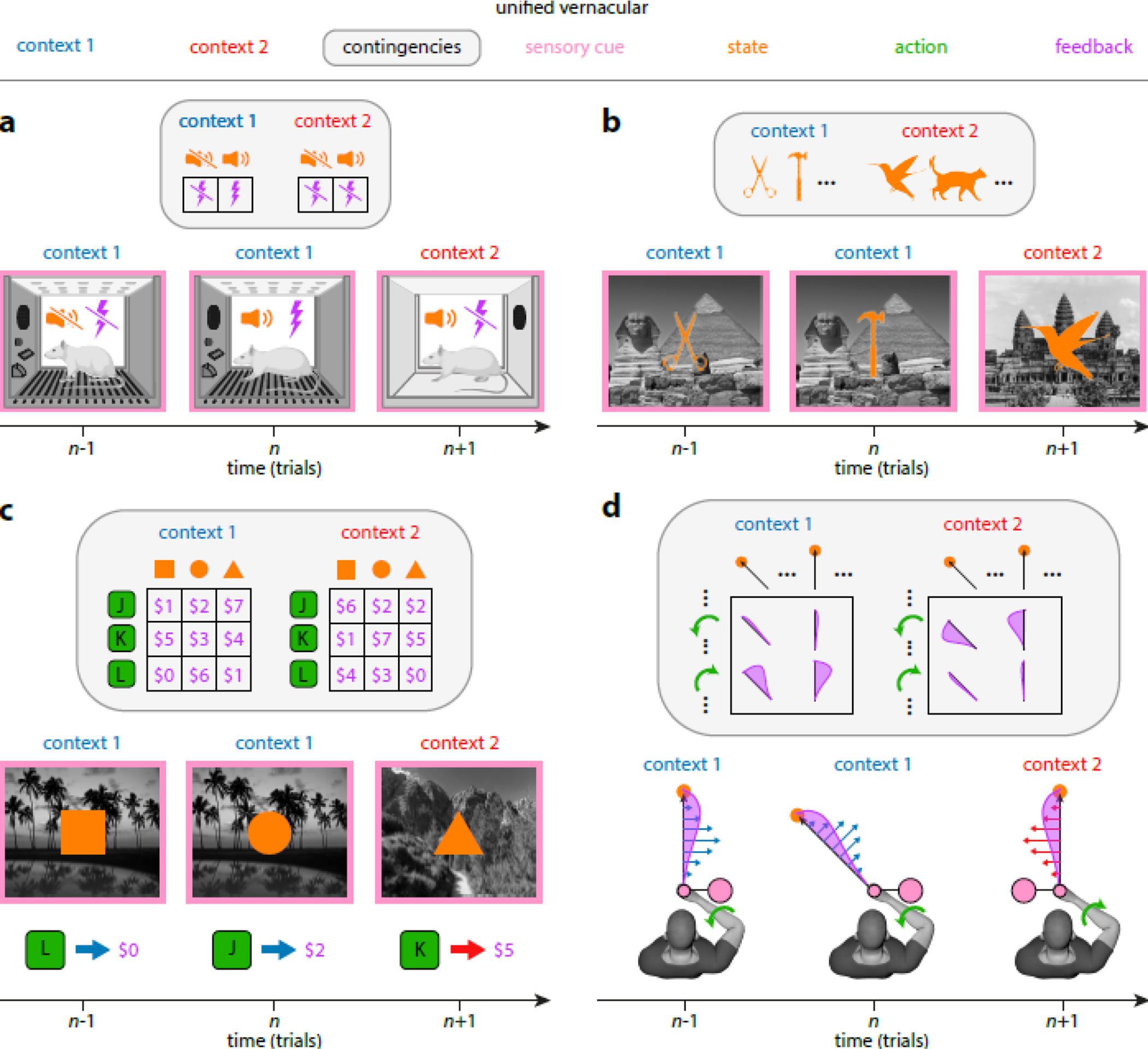
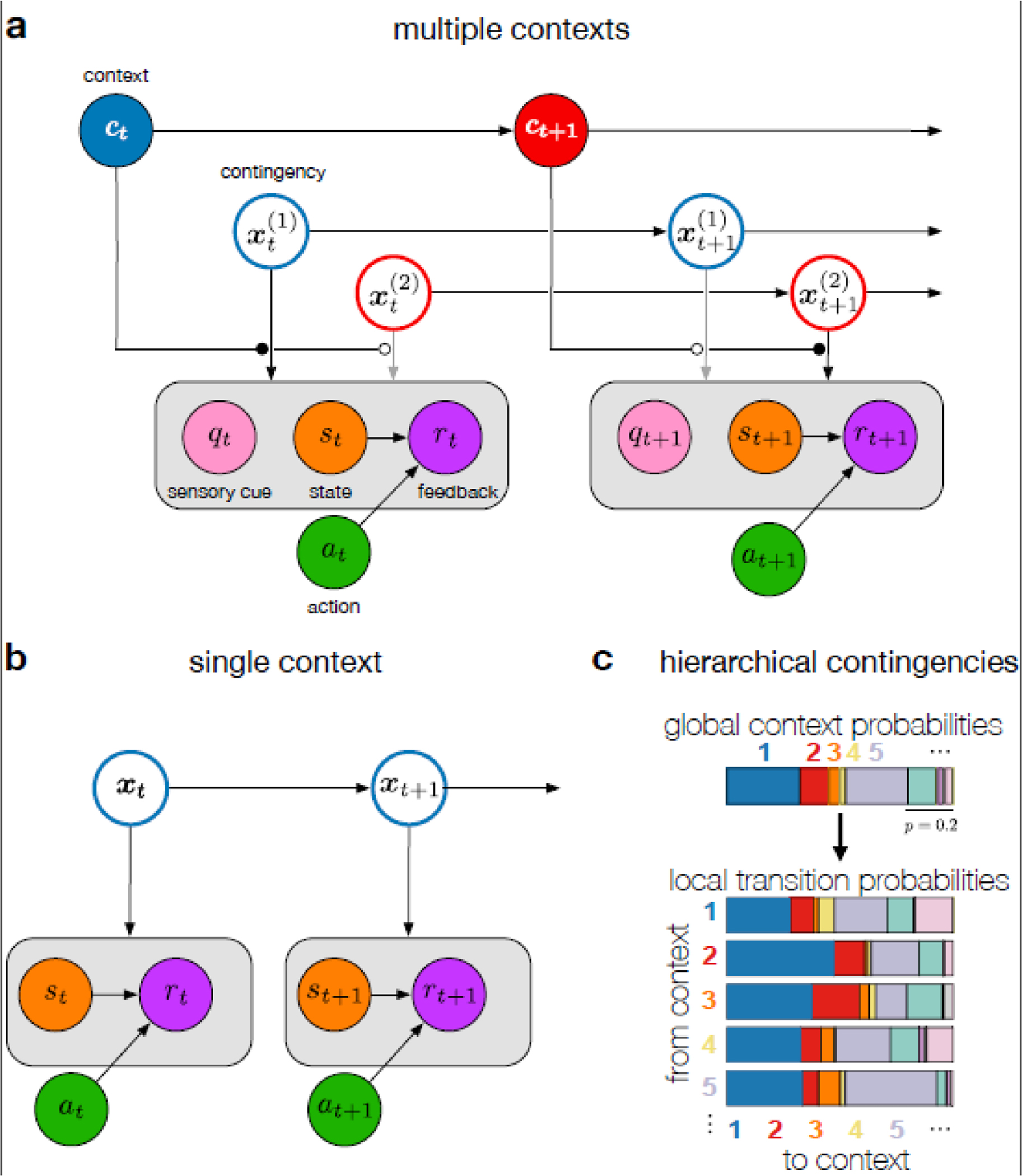
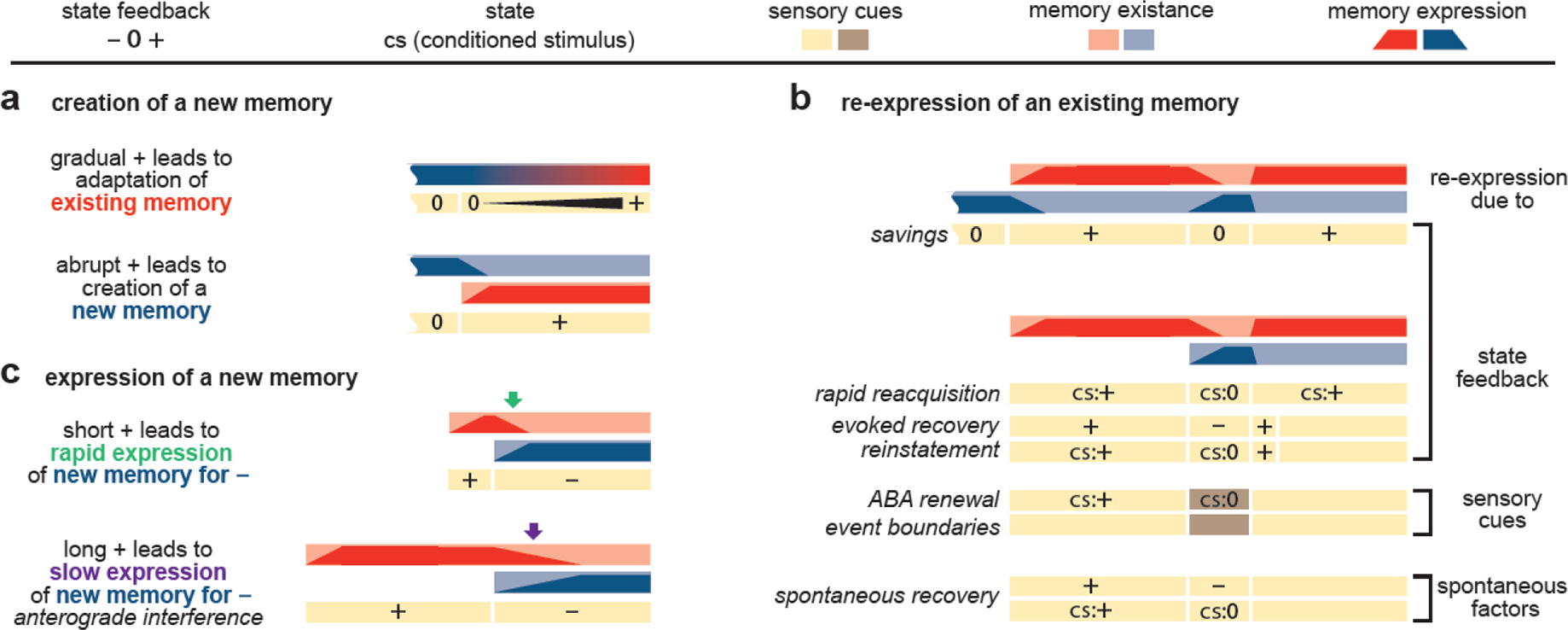
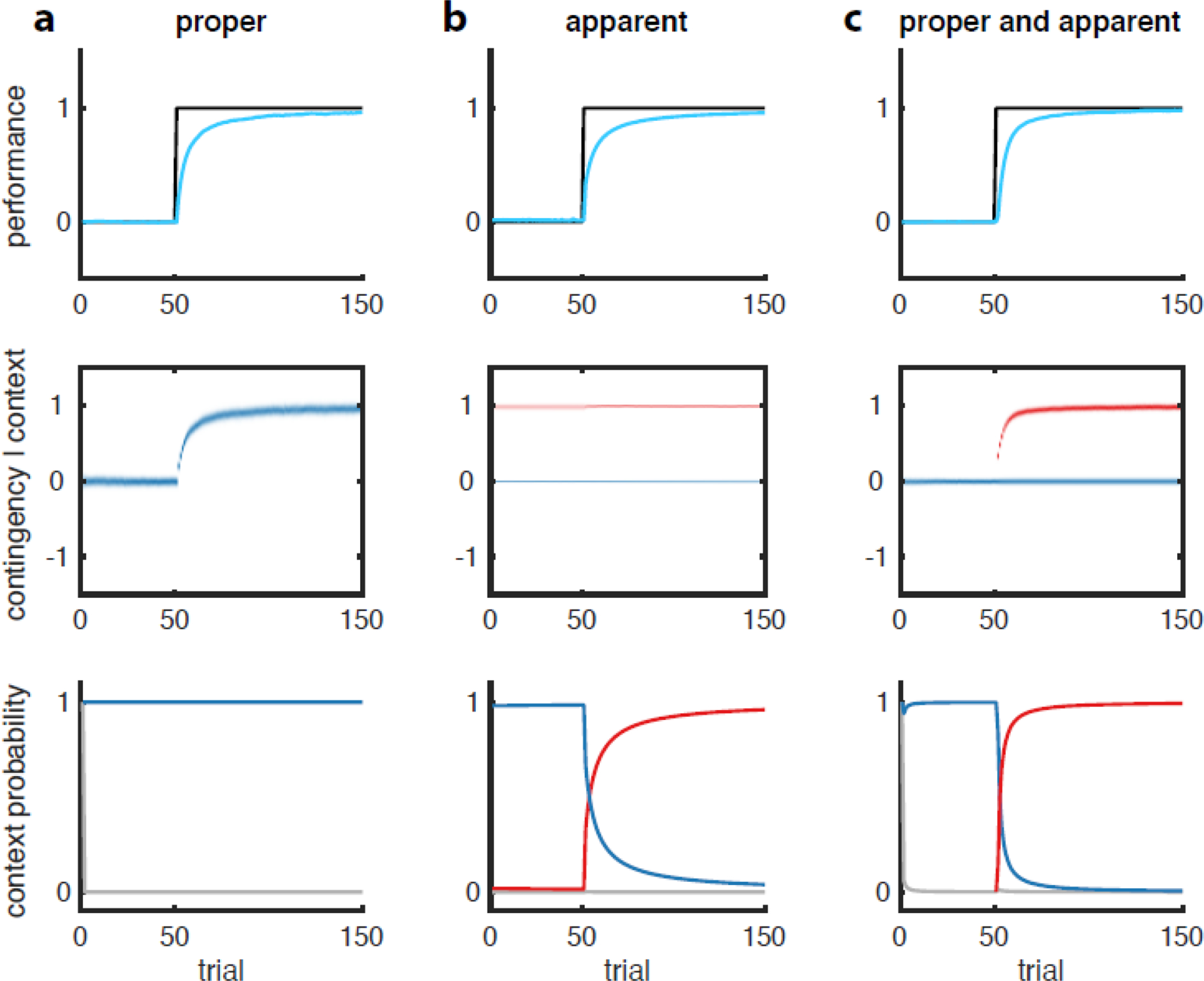
Context is widely regarded as a major determinant of learning and memory across numerous domains, including classical and instrumental conditioning, episodic memory, economic decision-making, and motor learning. However, studies across these domains remain disconnected due to the lack of a unifying framework formalizing the concept of context and its role in learning. Here, we develop a unified vernacular allowing direct comparisons between different domains of contextual learning. This leads to a Bayesian model positing that context is unobserved and needs to be inferred. Contextual inference then controls the creation, expression, and updating of memories. This theoretical approach reveals two distinct components that underlie adaptation, proper and apparent learning, respectively referring to the creation and updating of memories versus time-varying adjustments in their expression. We review a number of extensions of the basic Bayesian model that allow it to account for increasingly complex forms of contextual learning.
Keywords: Bayesian inference; context-dependent learning; learning; memory.
Copyright © 2022 The Authors. Published by Elsevier Ltd.. All rights reserved.
Conflict of interest statement
Declaration of interests D.M.W. is a consultant to CTRL-Labs Inc., in the Reality Labs Division of Meta. This entity did not support or influence this work. The authors declare no other competing interests.
Figures
References
-
- Courville AC, Daw ND, and Touretzky DS (2006). Bayesian theories of conditioning in a changing world. Trends in Cognitive Sciences 10, 294–300. - PubMed
-
- Redish AD, Jensen S, Johnson A, and Kurth-Nelson Z (2007). Reconciling reinforcement learning models with behavioral extinction and renewal: implications for addiction, relapse, and problem gambling. Psychological Review 114, 784–805. - PubMed
-
- Gershman SJ, Blei DM, and Niv Y (2010). Context, learning, and extinction. Psychological Review 117, 197–209. - PubMed
-
- Howard MW and Kahana MJ (2002). A distributed representation of temporal context. Journal of Mathematical Psychology 46, 269–299.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Medical
